Istio Mixer Cache工作原理与源码分析(2)-工作原理
前言
经过前面的基础概念的介绍,我们现在已经可以勾勒出一个mixer cache的实现轮廓,当然实际代码实现时会有很多细节。但是为了方便理解,我们在深入细节之前,先给出一个简化版本,让大家快速了解mixer cache的实现原理。后面的章节我们再逐渐深入。
Mixer Cache分为两个部分:
- check cache
- quota cache
简单起见,我们先关注check cache,在check cache讲述清楚之后,我们再继续看quota cache。
备注:istio一直在持续更新,以下代码来源于istio 0.8版本。
Mixer Check Cache的构造
Mixer Cache在实现时,在envoy的内存中,保存有两个数据结构:
class CheckCache {
std::unordered_map<std::string, Referenced> referenced_map_;
using CheckLRUCache = utils::SimpleLRUCache<std::string, CacheElem>;
std::unique_ptr<CheckLRUCache> cache_;
}
具体代码: 见istio/proxy项目,文件
src/istio/mixerclient/check_cache.h
- referenced_map:保存的是引用属性
- cache:保存的是check的结果
这里和一般缓存不一样,有两个map,也就是存在两套key/value两层缓存,为什么要这样设计?
Mixer Check Cache的核心设计
缓存在设计上,最核心的内容就是如何设计缓存的key,这个问题在mixer check cache中尤其突出。
为什么要有两层Map?
我们继续以这个最基本的场景为例:
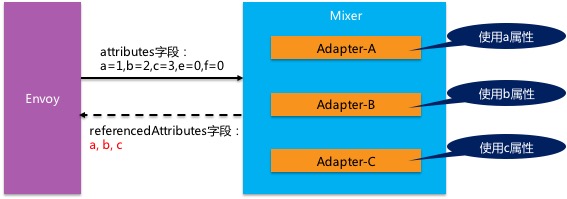
注意这个场景下属性的使用情况是这样的:
- envoy提交的请求中有5个属性,”a=1,b=2,c=3,e=0,f=0”
- mixer中有三个adapter,每个adapter只使用提交属性中的一个属性a/b/c
- 在CheckResponse中返回referencedAttributes字段的内容为”a,b,c”
要怎么设计这个Mixer check cache?先分析缓存的逻辑语义:
- 返回的referencedAttributes字段的内容为”a,b,c”,说明这三个属性被使用
- 结合输入的”a=1,b=2,c=3,e=0,f=0”,就可以得知"a=1,b=2,c=3"这个属性和属性的值的组合,代表一个输入,结果是固定而可以缓存的
- 如果下一个请求,同样提供”a,b,c”三个属性,并且三个属性的值是"a=1,b=2,c=3",则可以直接使用这个缓存的结果
注意:由于哪些属性可能会被使用是取决于运行时实际部署的adapter,因此mixer check cache的key计算时是无法直接指定要计算哪些属性的,也就无法简单的对输入属性做简单计算得到key。这是mixer cache和一般场景下的缓存的关键差异。
mixer check cache在工作时,如果要命中缓存,就必须带有两层匹配逻辑:
- 请求中是否携带有匹配的属性,在上面的例子中,就是要有”a,b,c”三个属性
- 这些属性是否具备匹配的值,在上面的例子中,就是要”a=1,b=2,c=3”
在具体实现上:
- referenced_map 是第一层缓存,用来保存引用属性的组合,注意只有属性名,这里不保存属性值
- cache 是第二层缓存,用来保存输入的签名(根据引用属性的值计算而来)/value (check的检查结果)
两层cache是如何工作的?
为了避免陷入代码细节,我们先不看代码具体实现(这是下一章的内容),先只看工作原理:
- referenced_map 用来保存哪些属性组合已经被缓存,比如
{"k1": "a,b,c"}这样表示当前只有一个属性组合"a,b,c"被保存,为了简单我们先忽略key的计算方式。 - cache用来保存输入的签名(简单理解为有效输入内容”a=1,b=2,c=3”的hash结果)和check 结果(简化为true/false表示是否通过),比如
{ "a=1,b=2,c=3": "true" }
我们来看各种场景下的请求和缓存的匹配请求,先看最理想的缓存命中的场景:
-
请求为:”a=1,b=2,c=3,e=0,f=0”
这个请求和被缓存的请求是一模一样的,我们期待可以命中缓存。
匹配时,先进行第一层匹配:输入的”a=1,b=2,c=3,e=0,f=0”和 referenced_map {“k1”: “a,b,c”} 进行检查,发现输入的”a=1,b=2,c=3,e=0,f=0”可以和保存的"a,b,c"属性组合匹配。
然后继续,第二层缓存就可以简单通过key来匹配了。注意在对输入进行签名时,只需要计算引用属性的hash值,即只需要计算"a=1,b=2,c=3",再通过这个签名在cache中找到缓存结果。
这便是标准的mixer check cache的匹配姿势。
-
请求为:”a=1,b=2,c=3,e=1,f=2”
差异在于e/f属性的值有所不同,考虑到e/f两个属性没有adapter使用,和”a=1,b=2,c=3,e=0,f=0”等效,我们期待可以命中缓存。
第一层匹配,输入的”a=1,b=2,c=3,e=1,f=2”和{“k1”: “a,b,c”} 命中,由于属性组合是"a,b,c",因此计算签名时还是计算"a=1,b=2,c=3",因此可以命中第二层缓存。
通过这种在签名时忽略未被adapter使用的属性的方式,mixer check cache 做到了只检查被adapter使用的属性,而其他属性的值不会影响。
我们再来看缓存不命中的典型场景,此时会多一个保存新结果到缓存的过程:
-
新请求:”a=1,b=2,c=10,e=0,f=0”
不同在于c的取值有变化,这是一个新的有效输入,和已经缓存的"a=1,b=2,c=3"不同,应该无法命中。
匹配时,第一层匹配命中,计算签名时计算的输入是"a=1,b=2,c=10",得到的签名结果自然和缓存的"a=1,b=2,c=3"的签名不同,因此第二层缓存没有命中。
这是典型的属性组合匹配但是属性具体值不匹配的场景,我们看mixer check cache的后续处理。
缓存不命中,就需要向mixer发起远程,得到应答,应答中给出adapter使用的属性情况,此时依然是"a,b,c",和检查的结果,我们假定这次是false。即此时我们得到了一个新的输入和结果的对应关系,我们将这个结果保存起来:referenced_map 中现有的值是 {“k1”: “a,b,c”},无需改变。cache 从 { “a=1,b=2,c=3”: “true” } 增加新结果,变为 { “a=1,b=2,c=3”: “true”, “a=1,b=2,c=10”: “false”}
-
继续发送请求:”a=1,b=2,c=10,e=0,f=0”/”a=1,b=2,c=3,e=0,f=0”
如果继续有这样的请求进来,则继续命中。
-
新请求:”a=1,b=20,c=10,e=0,f=0”
如果属性a/b/c的值继续变化,则继续重复前面的不命中后更新缓存的步骤。
absence key
通过上面稍显枯燥的描述,我想大家基本可以了解 mixer check cache 的工作原理,但是注意这个是经过简化的最简单版本,我们现在来加上 absence key 这个极其重要的概念。
什么叫做 absence key ?我们需要继续看回这个图片,注意mixer adapter使用的属性是a/b/c三个:
前面我们列出来的所有场景中,每个输入中都包含有a/b/c三个属性,考虑到其他不使用的属性在匹配过程中会被忽略而不影响,我们来将关注点放在a/b/c三个属性上。需要考虑这种可能:如果a/b/c三个属性不是每次都同时提供,而是少一个或者多个,结果会怎么样?
此时两层缓存的数据为:
- referenced_map = {“k1”: “a,b,c”}
- cache = { “a=1,b=2,c=3”: “true”, “a=1,b=2,c=10”: “false”}
如果我们有一个输入 ”a=1,b=2,c不存在,e=0,f=0” ,注意在这个输入中 c没有出现的。此时肯定缓存无法匹配,需要发送请求到mixer,我们再假设mixer adapter的处理逻辑在输入为"a=1,b=2,c不存在"的结果为"false"(这样可以和输入为"a=1,b=2,c=3"的结果"true"区分开)。
设计上有个问题:mixer该怎么返回引用属性来让mixer check cache可以正确的保存这个结果并用于后续的请求?
| 输入 | 输出 | 引用属性 |
|---|---|---|
| ”a=1,b=2,c=3,e=0,f=0” | true | “a,b,c” |
| ”a=1,b=2,c不存在,e=0,f=0” | false | “a,b"还是"a,b,c”? |
关键点:当输入中c不存在时,mixer的response中 referenced attribute 应该返回 “a,b” 还是 “a,b,c”?
先回顾一下 referenced attribute 的概念:按照我们之前介绍的逻辑,referenced attribute 返回的是 mixer adapter 使用到的属性。换句话说,这些属性之外的其他属性,是不会影响mixer adapter处理结果的,因此在缓存保存和匹配时都可以忽略。
首先来看,如果返回 “a,b” 会如何?这表示 c/e/f 属性可以被忽略,也就是不管c取值如何,是否出现,都不影响check的结果。即如果”a=1,b=2,c不存在,e=0,f=0”的结果为false,按照引用属性为"a,b"进行缓存,后面的”a=1,b=2,c=3,e=0,f=0”的请求,会被忽略c属性而命中”a=1,b=2"的缓存结果,导致返回false。
因此 mixer check cache 在设计中,引入了 absence key 的概念,mixer 的reponse里面,会明确指出:在输入为”a=1,b=2,c不存在,e=0,f=0”,输出为false这个场景下,referenced attribute 不仅仅包括出现在输入中的 a/b 两个属性,还有 c 这个虽然在输入中没有出现但是 mixer adapter 实际也使用了的属性的(属性c没有出现可以视为属性c的一个特别值)。这个没出现的属性c 被称为 absence key。
此时mixer check cache 在做缓存时,要处理 “a/b/c不存在” 这种特别的属性组合,具体步骤为:
- 第一层缓存 referenced_map = {“k1”: “a,b,c”} 和输入”a=1,b=2,c不存在,e=0,f=0” 因为c的缺席而无法匹配
- 发起对mixer的请求,获取新的应答,结果为false,引用属性为"a,b"和absence key c,我们简写为"a,b,c不存在"。
- 保存结果到第一层缓存 referenced_map 更新为 {“k1”: “a,b,c”, “k2”: “a,b,c不存在” }
- 保存结果到第二层缓存 cache 更新为 “a=1,b=2,c=3”: “true”, “a=1,b=2,c=10”: “false”, “a=1,b=2”: “false”}
之后的请求匹配缓存的过程,会稍有不同,体现在第一层缓存的匹配上,注意此时有两个属性组合 {“k1”: “a,b,c”, “k2”: “a,b,c不存在” }:
- 如果是 ”a=1,b=2,c=3,e=0,f=0” 这种a/b/c三个属性都提供的输入,则会匹配到 “k1”: “a,b,c”
- 如果是 ”a=1,b=2,c不存在,e=0,f=0” 这种提供了a/b属性而c没有提供的输入,则会匹配到 “k2”: “a,b,c不存在”
第二层缓存的匹配方式没有变化,注意由于属性c不存在,因此在计算”a=1,b=2,c不存在,e=0,f=0”这个输入的签名时,只需要计算”a=1,b=2”。
需要额外指出的是,当有多个属性被 mixer adapter 使用,而出现某个或者某几个属性不存在的场景,是可能有多种的,以上面"a,b,c"三个属性为例,会有"a,b"/“a,c”/“b,c”/“a”/“b”/“c”/""(即abc都不存在)7种情况,加上"a,b,c"都出现的情况,referenced_map 中会需要保存最多8种属性组合。而且,mixer adapter使用的属性越多,这个数量还会急剧增加。
备注:这个地方istio有一个bug,在研读代码时发现的,后来提交fix给了istio,后面我会结合代码给大家讲解。
总结
Mixer check Cache的设计,由于受限于无法得知mixer adaper会使用哪些属性,因此在设计上和普通缓存差异极大,必须明确引用属性和absence key的概念,才能正确理解mixer check cache。
下一节,我们终于可以展开源码了。
敖小剑
新时代农民工 * 中年码农
我目前研究的方向主要在Microservice、Servicemesh、Serverless等Cloud Native相关的领域,全职从事Dapr开发,欢迎交流和指导。