DreamMesh抛砖引玉(6)-性能开销
之前我们反复谈到,Service Mesh的核心在于将原有以类库方式提供的功能拆分到独立的sidecar进程中,以远程调用的方式来强行解耦服务间通讯的业务语义和服务间通讯的具体实现。这带来了诸多的好处,我们这里不再累述,而是来看看这对性能会有什么影响。
TBD: 暂时处于纸上谈兵状态,后续我们需要找到实际测试数据来验证我们的分析和猜想。
在上一节中我们看到,在引入Service Mesh之后,客户端和服务器端之间不再直接连接,而是走了mesh转发。这必然会带来额外的资源消耗,肯定会对性能有所影响。但是具体会到什么地步?这些影响会有多大?什么情况下可能会导致不适合使用Service Mesh。让我们来深入探讨这个话题。
序列化性能
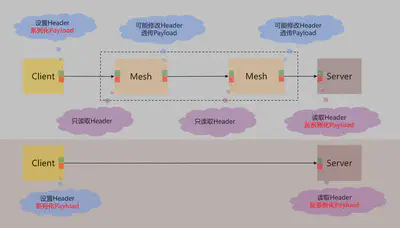
从图中可以看到,虽然加入Mesh(有可能是两个,如Istio/Conduit都是客户端服务器各一个),但是在Mesh内只读取(也可能做一些必要的修改)header,没有对Payload进行处理。
因此,全程下来,和侵入式开发框架相比,以HTTP协议为例,对比如下:
| 模式 | Payload序列化 | Payload反序列化 | HTTP协议解析 | HTTP协议组装 |
|---|---|---|---|---|
| 侵入式框架 | 1次 | 1次 | 1次 | 1次 |
| Service Mesh | 1次 | 1次 | 3次 | 3次 |
因此,全程下来,和侵入式开发框架相比:
-
在Payload序列化方面的开销相同
都只是一次序列化和反序列化,而且都没有发生在Mesh内部。因此引入Service Mesh之后,完全不必担心Payload序列化和反序列化的性能。原来是什么性能现在还是如此,不增不减。
-
多了两次HTTP协议的解析和组装
假定HTTP协议处理的资源消耗为1,我们来看当Payload不同时的性能对比:
消耗 Payload很重 Payload稍重 Payload很轻 Payload为空 Payload序列化 10000 100 10 0 侵入式开发框架协议处理 | 2 | 2 | 2 | 2 | Service Mesh协议处理 6 6 6 6 侵入式开发框架总额 | 10002 | 102 | 12 | 2 | Service Mesh总额 10006 106 16 6 消耗对比 | 增加4/10000 | 增加4% | 增加33% | 增加200% | 结论就是:payload越重,Service Mesh增加的消耗就越不起眼。但是对于Payload很轻的情况,尤其对于HTTP GET这种没有payload的请求,Service Mesh消耗增加的就会变的很夸张:增加200%!
-
考虑服务器端处理请求的消耗大小
消耗 消耗很大的请求 一般请求 请求很轻 空请求 服务器端处理请求的消耗 1000000 10000 100 0 侵入式开发框架 | 10002 | 102 | 12 | 2 | Service Mesh 10006 106 16 6 侵入式开发框架总额 1010002 10102 112 2 Service Mesh总额 1010006 10106 116 6 消耗对比 | 增加少到可忽略 | 增加4/10000 | 增加3% | 增加200% |
分析的结果,我们大体可以给出如下推断:
-
对于普通请求,有payload而且服务器端需要处理时,多增加的4次HTTP协议处理带来的消耗不大,大部分情况下几乎可以忽略。
-
对于特别轻量级的请求,比如没有payload而且服务器端处理简单(不做请求,或者足够简单如命中缓存)而且应答简单,则多增加的4次HTTP协议处理会带来非常明显的性能损失
TBD: 此处有待实际验证,需要跑性能测试进行对比。有测试数据的同学请联系我。
网络传输开销
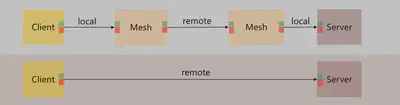
如图所示,Service Mesh下,多了两次远程调用:
- client发送请求给和client一起部署的Mesh
- 服务器端部署Mesh将收到的请求转发给Server
但是需要指出的是,这两次远程调用都发在在本地,也就是"localhost/127.0.0.1",走loopback/环回地址。而loopback可以绕开TCP/IP协议栈的下层,也就是会跳过链路层,物理层之类,不会真的经过网卡走网络,而是直接在IP层就处理了。如果优化得当还可以用Unix Socket之类的进一步提升性能,因此这两个我标记为"local"的调用,实际可以理解为是在内存里面兜了一圈,而不是真的走网络。
而两个标记为"remote"的调用,从网络条件来说可以认为是完全一致的,都是从client所在机器到server所在机器,中间的线路/速率/延迟/转发等都相同。
这样一来,在网络传输开销方面,Service Mesh增加的开销只在于两次loopback的网络调用。这个开销和client/server之间真实的网络线路相比可以认为是非常小的,无论是网络流量还是网络延迟。
推断:网络传输开销的增加基本上不大。
内存开销
这里有两方面的内存开销增加:
-
Sidecar进程额外占用的内存
和原有client/server进程相比,现在多了Sidecar的进程,必然会多出一些内存占用。
首当其冲的就是以Java为典型代表的基于JVM的语言,由他们编写的sidecar天然就要额外占用很多内存。其次,通过GC机制来自动回收内存,内存占用也会多一些。因此,基于Scala语言的Linkerd在这方面就吃亏比较大,和基于C++的Envoy相比差距明显。所以后来Bueyant重新开发Conduit时干脆选择用Rust。
-
请求转发过程中占用的内存
请求在一路转发的过程中,sidecar肯定要占用内存的:毕竟一边接收请求,一边转发,期间要解析协议格式把Header读取出来。
此时,sidecar代码实现中"zero copy"是最基本的要求,必须做到。
遇到需要改动请求的情况就麻烦了,比如需要添加一个header(如http_x_forwarded_host),需要去除某个header(抹掉某些敏感信息),或者改写某个header的值(如Host)。在无法只读的情况下简单的"zero copy"肯定不可行,但是如果实现的足够好,起码Payload部分还是可以继续实现"zero copy"的。
TBD: 需要去读一下Envoy和Conduit的代码,看看他们具体如何实现。
在这一点上,HTTP/2(还有基于HTTP/2的gRPC)有天然优势:HTTP/2协议是基于帧的,Header帧和Data帧是分别发送的,因此对Header帧的修改完全不会影响到Data帧的处理,在编码实现上要比Header/Body一起传输的HTTP1.1简单的多。
有一点应该比较明朗:Service Mesh不适合大文件传输。毕竟中间多了两次sidecar转发,对内存开销和后面提到的CPU开销都会有负面影响。
sidecar的部署模型
额外的话题:sidecar的部署模型,是否一定要和服务实例一对一?
这是目前Istio/Conduit的标准部署模型,部署服务实例都会插入一个sidecar。考虑引入Docker之后,同一台物理机器上,容器的部署数量会大为增加,反映在服务实例上就是会有大量的服务实例部署在同一个物理机器上。此时是否应该考虑共享sidecar以减少sidecar的部署数量?这样可以大幅度的节约内存。
cpu开销
继续看回这个图片,多了两次sidecar的转发:
必然会有CPU开销的增加:
- 两次sidecar转发请求,无论是接收请求还是发送请求,都涉及到网络IO
- 接收请求之后,必须解析协议,读取header
但是和前面序列化的分析类似,只有当请求足够简单并且服务器端处理请求的负载足够低导致QPS非常高时,才会对性能有明显影响。对于大多数情况,影响应该不大。
讨论和反馈
- 敖小剑:昨晚写好的,反思了一下sm的性能问题。你们有测试过吗?直连和走两次sidecar对性能有多大影响?
- 田晓亮:影响不大,如果不是简单的helloworld,比如你的业务代码只往标准输出打印一行字符串,可以忽略。我觉得还是贴近真实来看性能损耗,因为真实世界没有helloworld
- 敖小剑:如果是呢?我推演的是,简单请求加服务器端空实现,要除于3的。
- 田晓亮:恩,空实现确实,下降40%吧。
- 敖小剑:我们要备着一种情况,就是服务器端做了缓存,在缓存命中的情况下,服务器端接近空实现。
- 田晓亮:对。但是一般性能瓶颈都在业务,性能下降可以忽略。其实我认为一般的业务tps真不高,尤其我面对的还有动态语言。
- 崔秀龙:我是做了一段时间的优化工作之后,就再也不管啥性能问题了。
- 田晓亮:恩,可以忽略,我的客户也没关心这个问题,不敏感。看到那么多能力后,估计觉得性能就不是事了。
- 崔秀龙:我遇到的绝大多数性能问题是 debug/review 范畴,轮不到拔尖优化。
- 敖小剑:嗯,我主要是担心有人较真,从推演上说空实现的极致性能会有超过50%的下降。这样你们以前说的30万qps估计应该保不住了。
- 崔秀龙:我所见过的企业用户的计算资源不是不足,是多得愁人。
- 田晓亮:还真是。
- 李乘胜:一般大多数内部的企业系统,资源利用率都很低。
- 敖小剑:我还在想着如果服务qps不高,每个服务实例一个sidecar是不是太浪费了?istio支持在单个节点上只部署一个envoy给多个pod里面的服务共用吗?
- 崔秀龙:没这法子吧?不合理啊,如果说一个业务应用,跟envoy是同体量的,是不是太“微”了?qps 都不高了,多个envoy又不会怀孕。
- 敖小剑:可是一个节点上跑几十个docker实例时,就起几十个envoy,好浪费啊。
- 李大伟:我们以前也考虑过sidecar是不是太浪费了,没选sidecar模式,生产运营半年多后发现计算资源根本用不了,上层应用的qps一点都不给力。
- 田晓亮:Sidecar肯定是最佳实践,只要内存控制住。
后记
有兴趣的朋友,请联系我的微信,加入DreamMesh内部讨论群。
敖小剑
新时代农民工 * 中年码农
我目前研究的方向主要在Microservice、Servicemesh、Serverless等Cloud Native相关的领域,全职从事Dapr开发,欢迎交流和指导。