内容摘录自官方文档 Programming Model 一节
为了理解这个编程模型,你应该熟悉以下核心概念:
- 目的地绑定器(Destination Binders):负责提供与外部消息系统的集成的组件。
- 绑定(Bindings):外部消息系统和应用程序之间的桥梁,提供消息生产者和消费者(由目的地绑定器创建)。
- 消息(Message):生产者和消费者使用的典型数据结构,用于与目的地绑定器通信(从而通过外部消息系统与其他应用程序通信)。
内容摘录自官方文档 Programming Model 一节
为了理解这个编程模型,你应该熟悉以下核心概念:
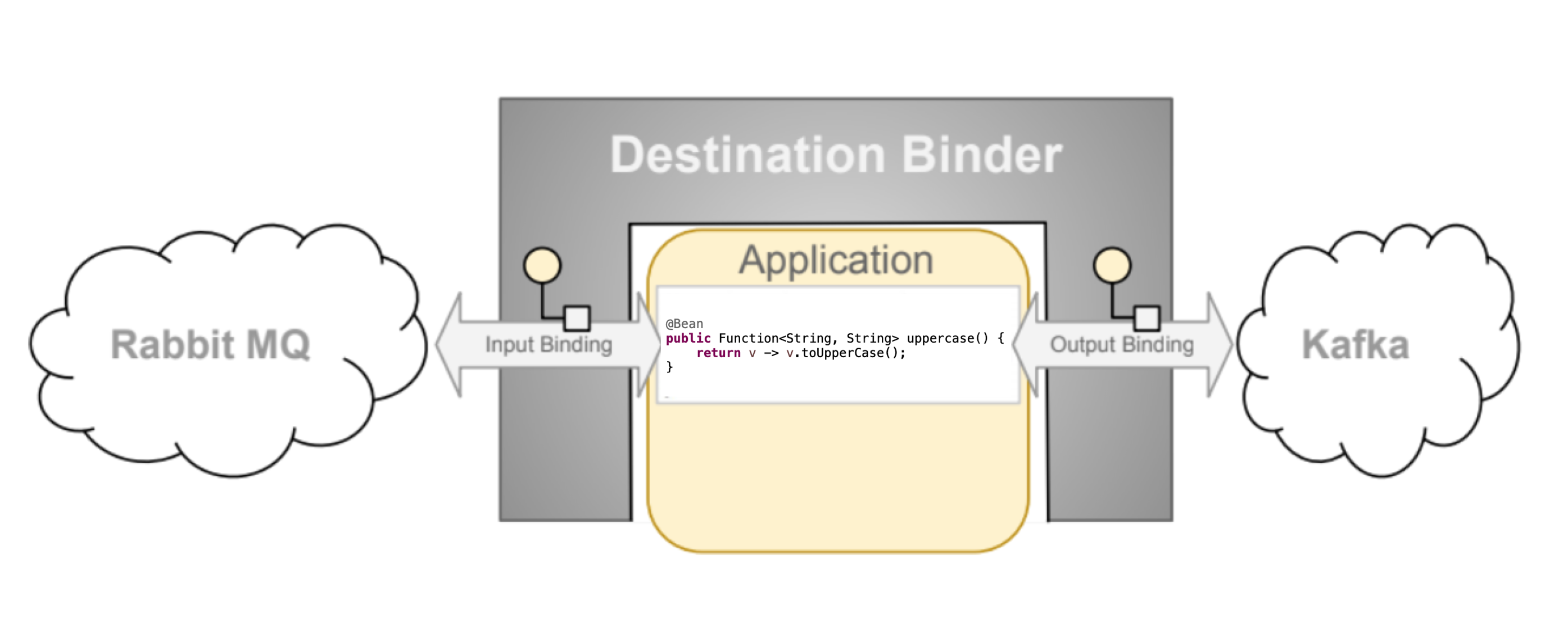
内容摘录自官方文档 Destination Binders 一节
目的地绑定器(Destination Binders)是 Spring Cloud Stream 的扩展组件,负责提供必要的配置和实现,以促进与外部消息系统的集成。这种集成负责生产者和消费者之间的连接、委托和消息的路由、数据类型转换、用户代码的调用等。
Binder 处理了很多本来要落在开发者身上的责任。然而,为了达到这个目的,Binder 仍然需要一些帮助,其形式是来自用户的极简而必要的指令集,这些指令通常以某种类型的 binding 配置的形式出现。
虽然讨论所有可用的 binder 和 binding 配置选项超出了本节的范围(本手册的其他部分将广泛涉及这些选项),但 binding 作为一个概念,确实需要特别注意。下一节将详细讨论它。
内容摘录自官方文档 Bindings 一节
如前所述,binding 在外部消息系统(如队列、主题等)和应用程序提供的生产者和消费者之间提供了一座桥梁。
下面的例子显示了一个完全配置和运行的 Spring Cloud Stream 应用程序,该应用程序接收作为字符串类型的消息的有效载荷(见内容类型协商部分),将其记录到控制台,并在将其转换为大写字母后向下发送。
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> {
System.out.println("Received: " + value);
return value.toUpperCase();
};
}
}
上面的例子看起来和任何 spring-boot 应用程序没有什么不同。它定义了一个 Function 类型的 bean,这就是它。那么,它是如何成为 spring-cloud-stream 应用程序的呢?它之所以成为 spring-cloud-stream 应用程序,仅仅是因为在 classpath 上存在 spring-cloud-stream 和 binder 的依赖关系以及自动配置类,有效地将启动应用程序的上下文设置为 spring-cloud-stream 应用程序。在这种情况下,Supplier、Function 或 Consumer 类型的 bean 被视为事实上的消息处理程序,触发绑定到所提供的绑定器所暴露的目的地,并遵循一定的命名惯例和规则以避免额外的配置。
绑定 (binding) 是一个抽象概念,代表了绑定器(binder)和用户代码所暴露的源和目标之间的桥梁,这个抽象概念有一个名字,虽然我们尽力限制运行 spring-cloud-stream 应用程序所需的配置,但在需要对每个绑定 (binding) 进行额外配置的情况下,了解这些名字是必要的。
在本手册中,你会看到一些配置属性的例子,如 spring.cloud.stream.bindings.input.destination=myQueue。这个属性名称中的 input 段就是我们所说的绑定名称(binding name),它可以通过几种机制衍生出来。下面的小节将描述 spring-cloud-stream 用于控制绑定名称(binding name)的命名惯例和配置元素。
与 spring-cloud-stream 以前的版本中使用的基于注解的支持(legacy)所要求的显式命名不同,函数式编程模型在涉及到绑定名称时默认为简单的约定,从而大大简化了应用配置。让我们来看看第一个例子。
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
在前面的例子中,我们有一个应用程序,它有一个单一的函数作为消息处理程序。作为 Function,它有一个输入和输出。用来命名输入和输出绑定的命名规则如下:
<functionName> + -in- + <index><functionName> + -out- + <index>in 和 out 对应的是 binding 的类型(如输入或输出)。index是输入或输出绑定的索引。对于典型的单一输入/输出函数,它总是0,所以它只与具有多个输入和输出参数的函数有关。
因此,如果你想把这个函数的输入映射到一个叫做 “my-topic” 的远程目标(例如,主题、队列等),你可以通过以下属性来实现:
--spring.cloud.stream.bindings.uppercase-in-0.destination=my-topic
请注意 uppercase-in-0 是如何作为属性名称中的一个段的。同样,uppercase-out-0也是如此。
有些时候,为了提高可读性,你可能想给你的 binding 一个更具描述性的名字(比如 “账户”,“订单” 等)。另一种方式是你可以将隐式绑定名称映射到显式绑定名称。你可以用 spring.cloud.stream.function.bindings.<binding-name> 属性来做。该属性还为依赖基于自定义接口的绑定的现有应用程序提供了一个迁移路径,这些绑定需要显式名称。
例如:
--spring.cloud.stream.function.bindings.uppercase-in-0=input
在前面的例子中,你把 uppercase-in-0 binding name 映射并有效地重命名为 input。现在,所有的配置属性都可以参考 input的binding name(例如, --spring.cloud.bindings.input.destination=my-topic)。
虽然描述性的 binding name 可能会增强配置的可读性,但它们也会通过将隐式绑定名称映射到显式绑定名称而产生另一种程度的误导。而且,由于所有后续的配置属性都将使用显式绑定名称,你必须始终参考这个 “bindings” 属性,以确定它实际上对应的是哪个功能。我们认为,对于大多数情况(函数组合除外),这可能是一种矫枉过正的做法,所以,我们建议完全避免使用它,尤其是不使用它可以在 binding 目的地和 binding name 之间提供一条清晰的路径,比如 spring.cloud.stream.bindings.uppercase-in-0.destination=sample-topic,在这里你可以清楚地将 uppercase 函数的输入与 sample-topic 的目的地相关联。
关于属性和其他配置选项的更多信息,请参见配置选项部分。
在上一节中,我们解释了如何通过你的应用程序提供的 Function, Supplier 或 Consumer 驱动来隐式地创建 binding。然而,有时你可能需要显式地创建绑定,而绑定并不与任何函数挂钩。这通常是为了支持与其他框架(如Spring integration 框架)的集成,在那里你可能需要直接访问底层的 MessageChannel。
Spring Cloud Stream 允许你通过 spring.cloud.stream.input-bindings 和 spring.cloud.output-bindings 属性明确定义输入和输出绑定。注意到属性名称中的复数,允许你通过简单地使用;作为分隔符来定义多个绑定。请看下面的测试案例作为一个例子:
@Test
public void testExplicitBindings() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(EmptyConfiguration.class))
.web(WebApplicationType.NONE)
.run("--spring.jmx.enabled=false",
"--spring.cloud.stream.input-bindings=fooin;barin",
"--spring.cloud.stream.output-bindings=fooout;barout")) {
assertThat(context.getBean("fooin-in-0", MessageChannel.class)).isNotNull();
assertThat(context.getBean("barin-in-0", MessageChannel.class)).isNotNull();
assertThat(context.getBean("fooout-out-0", MessageChannel.class)).isNotNull();
assertThat(context.getBean("barout-out-0", MessageChannel.class)).isNotNull();
}
}
@EnableAutoConfiguration
@Configuration
public static class EmptyConfiguration {
}
正如你所看到的,我们声明了两个 input 绑定和两个 output 绑定,而我们的配置中没有定义任何函数,但我们还是能够成功地创建这些绑定并访问它们相应的通道。
其余适用于隐式绑定的绑定规则也适用于此(例如,你可以看到 fooin 变成了 fooin-in-0 绑定/通道等)。
内容摘录自官方文档 Producing and Consuming Messages 一节
你可以通过简单地编写函数并将其作为 “@Bean " 公开,来编写 Spring Cloud Stream 应用程序。你也可以使用基于 Spring Integration 注解的配置或基于 Spring Cloud Stream 注解的配置,不过从 spring-cloud-stream 3.x 开始,我们建议使用函数实现。
内容摘录自官方文档 Spring Cloud Function support 一节
内容摘录自官方文档 Overview 一节
自 Spring Cloud Stream v2.1以来,定义流处理程序和源的另一个选择是使用 Spring Cloud Function 的内置支持,在那里它们可以被表达为 java.util.function.[Supplier/Function/Consumer] 类型的 bean。
要指定哪个函数式 bean 绑定到绑定所暴露的外部目标,你必须提供 spring.cloud.function.define 属性。
如果你只有 java.util.function.[Supplier/Function/Consumer] 类型的单个Bean,你可以跳过 spring.cloud.function.define 属性,因为这种函数 Bean 会被自动发现。然而,使用这种属性被认为是最好的做法,以避免任何混淆。有些时候,这种自动发现可能会妨碍工作,因为 java.util.function.[Supplier/Function/Consumer] 类型的单体 Bean 可能有处理消息以外的目的,但由于是单体,它被自动发现并自动绑定。对于这些罕见的情况,你可以通过提供 spring.cloud.stream.function.autodetect 属性来禁用自动发现,其值设置为 false。
下面是应用程序将消息处理程序暴露为 java.util.function.Function 的例子,通过充当数据的消费者和生产者,有效地支持直通语义。
@SpringBootApplication
public class MyFunctionBootApp {
public static void main(String[] args) {
SpringApplication.run(MyFunctionBootApp.class);
}
@Bean
public Function<String, String> toUpperCase() {
return s -> s.toUpperCase();
}
}
在前面的例子中,我们定义了一个名为 toUpperCase 的 java.util.function.Function 类型的 bean,作为消息处理程序,其 “input” 和 “output” 必须绑定到所提供的目标绑定器所暴露的外部目的地。默认情况下,‘inpu’ 和 ‘output’ binding name 将是 toUpperCase-in-0 和 toUpperCase-0。请参阅函数绑定名称部分,了解用于建立绑定名称的命名规则的细节。
下面是支持其他语义的简单功能应用的例子。
下面是一个以 java.util.function.Supplier 形式暴露的 source 语义的例子:
@SpringBootApplication
public static class SourceFromSupplier {
@Bean
public Supplier<Date> date() {
return () -> new Date(12345L);
}
}
下面是一个以 java.util.function.Consumer 形式暴露的 sink 语义的例子
@SpringBootApplication
public static class SinkFromConsumer {
@Bean
public Consumer<String> sink() {
return System.out::println;
}
}
root
topic1
subtopic
topic2
subtopic
内容摘录自官方文档 Suppliers (Sources) 一节
当涉及到它们的调用如何被触发时,Function 和 Consumer 是非常直接的。它们是根据发送到它们所绑定的目的地的数据(事件)来触发的。换句话说,它们是典型的事件驱动型组件。
然而,当谈到触发时,Supplier 属于自己的类别。因为根据定义,它是数据的源头(the origin),它不订阅任何绑定的目的地,因此,必须由其他机制来触发。还有一个 Supplier 实现的问题,它可以是命令式的(imperative),也可以是反应性的(reactive),它直接关系到这些 Supplier 的触发。
请看下面的例子:
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<String> stringSupplier() {
return () -> "Hello from Supplier";
}
}
前面的 Supplier Bean 在调用其 get() 方法时产生一个字符串。然而,谁会调用这个方法,多久调用一次?框架提供了一个默认的轮询机制(回答了 “谁?“的问题),它将触发 Supplier v的调用,默认情况下,它每隔一秒就会调用一次(回答了 “多久一次?“的问题)。换句话说,上述配置每秒钟产生一条消息,每条消息都被发送到一个由 binder 暴露的 output 目的地。要了解如何定制轮询机制,请看轮询配置属性部分。
考虑一个不同的例子:
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.fromStream(Stream.generate(new Supplier<String>() {
@Override
public String get() {
try {
Thread.sleep(1000);
return "Hello from Supplier";
} catch (Exception e) {
// ignore
}
}
})).subscribeOn(Schedulers.elastic()).share();
}
}
上面的 Supplier Bean采用了反应式编程风格。通常情况下,与命令式 Supplier 不同,它应该只被触发一次,因为调用它的 get() 方法会产生(供应)连续的消息流,而不是单个消息。
该框架认识到了编程风格的不同,并保证这样的 Supplier 只被触发一次。
然而,想象一下这样的用例:你想轮询一些数据源并返回代表结果集的有限数据流。反应式编程风格是这种 Supplier 的完美机制。然而,考虑到产生的数据流的有限性,这样的 Supplier 仍然需要被定期调用。
考虑一下下面的例子,它通过产生一个有限的数据流来模拟这种用例:
@SpringBootApplication
public static class SupplierConfiguration {
@PollableBean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.just("hello", "bye");
}
}
Bean本身被注解了 PollableBean 注解(@Bean的子集),从而向框架发出信号,尽管这样一个 Supplier 的实现是反应式的,但它仍然需要被轮询。
正如你现在所了解的,与 Function 和 Consumer 不同,Function 和 Consumer 是由事件触发的(它们有输入数据),Supplier 没有任何输入,因此由不同的机制– poller 触发,它可能有一个不可预知的线程机制。虽然大多数时候线程机制的细节与函数的下游执行无关,但在某些情况下可能会出现问题,特别是对于那些可能对线程亲和力有一定期望的集成框架。例如,Spring Cloud Sleuth 就依赖于存储在 thread local 中的追踪数据。对于这些情况,我们有另一种通过 StreamBridge 的机制,用户可以对线程机制有更多的控制。你可以在发送任意数据到输出端(例如Foreign事件驱动源)一节中获得更多细节。
内容摘录自官方文档 Consumer (Reactive) 一节
Reactive Consumer 有点特别,因为它的返回类型是空的,没有给框架留下可以订阅的引用。你很可能不需要写 Consumer<Flux<?>,而是把它写成 Function<Flux<?>, Mono<Void>>,调用 then operator 作为你流中的最后一个 operator。
比如说。
public Function<Flux<?>, Mono<Void>>consumer() {
return flux -> flux.map(..).filter(..).then();
}
但如果你确实需要写一个显式的 Consumer<Flux<?>,记得要订阅传入的 Flux。
另外,请记住,当混合反应式和命令式函数时,同样的规则也适用于函数组合。Spring Cloud Function 确实支持将反应式函数与命令式函数进行组合,但是你必须注意到某些限制。例如,假设你将反应式函数与命令式消费者进行组合。这种组合的结果是一个反应式 Consumer。然而,正如本节前面所讨论的那样,没有办法订阅这样的消费者,所以这个限制只能通过使你的消费者成为反应式并手动订阅(如前所述),或者将你的函数改为命令式来解决。
以下属性由 Spring Cloud Stream 公开(尽管自3.2版本起已被废弃),并以 spring.cloud.stream.poller 为前缀。
fixedDelay
默认轮询器的固定延迟,单位是毫秒。
默认值:1000L。
maxMessagesPerPoll
默认轮询器的每个轮询事件的最大信息。
默认值:1L。
cron
Cron触发器的Cron表达式值。
默认值:无。
initialDelay
定期触发器的初始延迟。
默认值:0。
timeUnit
应用于延迟值的时间单位。
默认值。MILLISECONDS。
例如 --spring.cloud.stream.poller.fixed-delay=2000 设置轮询器的间隔为每两秒轮询一次。
org.springframework.boot.autoconfigure.integration.IntegrationProperties.Poller 以了解更多信息。
上一节展示了如何配置一个将应用于所有绑定的默认轮询器。虽然它很适合 spring-cloud-stream 设计的微服务模型,即每个微服务代表一个组件(例如,供应商),因此默认轮询器配置就足够了,但在一些边缘情况下,你可能有几个组件需要不同的轮询配置。
在这种情况下,请使用按绑定方式配置轮询器。在这种情况下,你可以使用 spring.cloud.stream.bindings.supply-out-0.producer.poller...前缀为这种绑定配置轮询器(例如,spring.cloud.bindings.supply-out-0.producer.poller.fixed-delay=2000)。
内容摘录自官方文档 Sending arbitrary data to an output (e.g. Foreign event-driven sources) 一节
将任意的数据发送到输出端(如 Foreign 的事件驱动源)。
有些情况下,实际的数据源可能来自于不是绑定器的外部(Foreign)系统。例如,数据源可能是一个经典的 REST 端点。我们如何将这样的 source 与 spring-cloud-stream 使用的函数机制连接起来?
Spring Cloud Stream 提供了两种机制,让我们来详细了解一下。
在这里,对于这两个样本,我们将使用一个标准的MVC端点方法,名为 delegateToSupplier,与根 Web 上下文绑定,通过StreamBridge 机制将传入的请求委托给流。
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, "--spring.cloud.stream.source=toStream");
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("toStream-out-0", body);
}
}
在这里,我们自动装箱(Autowire)了一个 StreamBridge Bean,它允许我们将数据发送到 output binding,有效地将非流应用程序与 spring-cloud-stream 连接起来。请注意,前面的例子没有定义任何 source 函数(例如,Supplier Bean),因此框架没有触发器来提前创建源绑定,这在配置包含函数 Bean 的情况下是很典型的。这很好,因为StreamBridge会在第一次调用send(.)操作时为非现有的绑定启动创建输出绑定(以及必要时的目的地自动配置),并将其缓存起来供后续重用(更多细节见StreamBridge和动态目的地)。
然而,如果你想在初始化(启动)时预先创建一个输出绑定,你可以从spring.cloud.stream.source属性中获益,在那里你可以声明你的源的名称。所提供的名称将被用作触发器来创建一个源绑定。所以在前面的例子中,输出绑定的名称将是toStream-out-0,这与函数使用的绑定命名惯例一致(见绑定和绑定名称)。你可以使用;来表示多个源(多个输出绑定)(例如,–spring.cloud.stream.source=foo;bar)
另外,注意streamBridge.send(..)方法需要一个对象作为数据。这意味着你可以向它发送POJO或消息,它在发送输出时将经过同样的程序,就像它来自任何函数或供应商一样,提供与函数相同的一致性。这意味着输出类型的转换、分区等都会被尊重,就像它是由函数产生的输出一样。