Linkerd、Consul、Istio、Kuma、Traefik、AWS App服务网格全方位对比
Servicemesh的市场竞争
Servicemesh的市场竞争
- 1: (2017)2017年Servicemesh年度总结
- 2: (2021)服务网格除了 Istio,其实你还可以有其它 8 种选择
- 3: (2021)服务网格联网:使用案例、最佳实践和顶级服务网格选择比较
- 4: (2021)Google Cloud 服务网格: Traffic Director 与 Anthos Service Mesh 的左右互搏
- 5: (2021)服务网格比较: Istio 与 Linkerd
1 - (2017)2017年Servicemesh年度总结
2017年Servicemesh年度总结
在过去的几年中,微服务技术得以迅猛普及,和容器技术一起成为这两年中最吸引眼球的技术热点。而以Spring Cloud为代表的传统侵入式开发框架,占据着微服务市场的主流地位,甚至一度成为微服务的代名词。
直到2017年年底,当非侵入式的Service Mesh技术终于从萌芽到走向了成熟,当Istio横空出世,人们才惊觉:微服务并非只有侵入式一种玩法,微服务更不是Spring Cloud的独角戏!
这一次的新生力量,完全不按照常理出牌,出场就霸道地掀翻桌子,直接摆出新的玩法:Service Mesh,下一代微服务!让我们一起来回顾这一场起于2017年的Service Mesh大战,一起领略各家产品的风采。
Service Mesh的萌芽期
在我们正式开始之前,我们将时间回到2016年:有些故事背景需要预交交代一下。
虽然直到2017年底,Service Mesh才开始较大规模被世人了解,这场微服务市场之争也才显现,但是其实Service Mesh这股微服务的新势力,早在 2016年初就开始萌芽:
-
2016年1月15日,离开Twitter的基础设施工程师William Morgan和Oliver Gould,在github上发布了Linkerd 0.0.7版本,他们同时组建了一个创业小公司Buoyant,业界第一个Service Mesh项目诞生。
-
2016年,Matt Klein在Lyft默默的进行Envoy的开发。Envoy诞生的时间其实要比Linkerd更早一些,只是在Lyft内部不为人所知。
在2016年初,Service Mesh还只是Buoyant公司的内部词汇,而之后,随着Linkerd的开发和推广,Service Mesh这个名词开始逐步走向社区并被广泛接受,喜爱和推崇:
- 2016年9月29日在SF Microservices上,“Service Mesh”这个词汇第一次在公开场合被使用。这标志着“Service Mesh”这个词,从Buoyant公司走向社区。
- 2016年10月,Alex Leong开始在buoyant公司的官方Blog中开始”A Service Mesh for Kubernetes”系列博客的连载。随着”The services must mesh”口号的喊出,buoyant和Linkerd开始service mesh概念的布道。
在2016年,第一代的Service Mesh产品稳步推进:
- 2016年9月13日,Matt Klein宣布Envoy在github开源,直接发布1.0.0版本
- 2016年下半年,Linkerd陆续发布了0.8和0.9版本,开始支持HTTP/2 和gRPC,1.0发布在即;同时,借助Service Mesh在社区的认可度,Linkerd在年底开始申请加入CNCF。
而在这个世界的另外一个角落,Google和IBM两位巨人,握手开始合作,他们联合Lyft,启动了Istio项目。这样,在第一代Service Mesh还未走向市场主流时,以Istio为代表的第二代Service Mesh就迫不及待地准备上路。
现在我们可以进入主题,开始2017和2018年Service Mesh市场竞争的回顾。
急转而下的Linkerd
2017年,Linkerd迎来了一个梦幻般的开局,喜讯连连:
- 2017年1月23日,Linkerd加入CNCF
- 2017年3月7日,Linkerd宣布完成千亿次产品请求
- 2017年4月25日,Linkerd 1.0版本发布
可谓各条战线都进展顺利:产品完成1.0 release,达成最重要的里程碑;被客户接受并在生产线上成功大规模应用,这代表着市场的认可;进入CNCF更是意义重大,是对Linkerd的极大认可,也使得Linkerd声名大噪。一时风光无量,可谓”春风得意马蹄疾,一日看尽长安花”。
需要特别指出的是,Linkerd加入CNCF,对于Service Mesh技术是一个非常重要的历史事件:这代表着社区对Service Mesh理念的认同和赞赏,Service Mesh也因此得到社区更大范围的关注。
趁热打铁,就在Linkerd 1.0版本发布的同一天,Service Mesh的前驱继续Service Mesh的布道:
- 2017年4月25日,William Morgan发布博文”What’s a service mesh? And why do I need one?“。正式给Service Mesh做了一个权威定义。
然而现实总是那么残酷,这个美好的开局,未能延续多久就被击碎:
- 2017年5月24日,Istio 0.1 release版本发布,google和IBM高调宣讲,社区反响热烈,很多公司在这时就纷纷站队表示支持Istio。
Linkerd的风光瞬间被盖过,从意气风发的少年一夜之间变成过气网红。当然,从产品成熟度上来说,linkerd作为业界仅有的两个生产级Service Mesh实现之一,暂时还可以在Istio成熟前继续保持市场。但是,随着Istio的稳步推进和日益成熟,外加第二代Service Mesh的天然优势,Istio取代第一代的Linkerd只是个时间问题。
面对Google和IBM加持的Istio,linkerd实在难有胜算:
- Istio作为第二代Service Mesh,通过控制平面带来了前所未有的控制力,远超Linkerd。
- Istio通过收编和Linkerd同为第一代Service Mesh的Envoy,直接拥有了一个功能和稳定性与Linkerd在一个水准的数据平面。
- 基于c++的Envoy在性能和资源消耗上本来就强过基于Scala/Jvm的Linkerd
- Google和IBM在人力,资源和社区影响力方面远非Buoyant公司可以比拟
Linkerd的发展态势顿时急转而下,未来陷入一片黑暗。出路在哪里?
在一个多月后,Linkerd给出一个答案:和Istio集成,成为Istio的数据面板。
- 2017年7月11日,Linkerd发布版本1.1.1,宣布和Istio项目集成。Buoyant发表博文”Linkerd and Istio: like peanut butter and jelly”。
这个方案在意料之中,毕竟面对Google和IBM的联手威胁,选择低头和妥协是可以理解的。只是存在两个疑问:
- 和Envoy相比,Linkerd并没有特别优势。考虑编程语言的天生劣势,Linkerd想替代Envoy难度非常之大。
- 即使替代成功,在Istio的架构下,只是作为一个数据平面存在的Linkerd,可以发挥的空间有限。这种境地的Linkerd,是远远无法承载起Buoyant的未来的。
Linkerd的这个谜团,直到2017年即将结束的12月,在Conduit发布之后才被解开。
波澜不惊的Envoy
自从在2016年决定委身于Istio之后,Envoy就开始了一条波澜不惊的平稳发展之路,和Linkerd的跌宕起伏完全不同。
在功能方面,由于定位在数据平面,因此Envoy无需考虑太多,很多工作在Istio的控制平面完成就好,Envoy从此专心于将数据平面做好,完善各种细节。在市场方面,Envoy和Linkerd性质不同,不存在生存和发展的战略选择,也没有正面对抗生死大敌的巨大压力。Envoy在2017年有条不紊地陆续发布了1.2、1.3、1.4和1.5版本,在2018年发布了1.6、1.7、1.8版本,稳步地完善自身,表现非常稳健。
稳打稳扎的Envoy一方面继续收获独立客户,一方面伴随Istio一起成长。作为业界仅有的两个生产级Service Mesh实现之一,Envoy在2017年中收获了属于它的殊荣:
- 2017年9月14日,Envoy加入CNCF,成为CNCF的第二个Service Mesh项目
可谓名至实归,水到渠成。作为一个无需承载一家公司未来的开源项目,Envoy在2017和2018年的表现,无可挑剔。
背负使命的Istio
从Google和IBM联手决定推出Istio开始,Istio就注定永远处于风头浪尖,无论成败。
Istio背负了太多的使命:
- 建立Google和IBM在微服务市场的统治地位
- 为Google和IBM的公有云打造杀手锏级特性
- 在k8s的基础上,延续Google的战略布局
Google在企业市场的战略布局,是从底层开始,一步一步向上,一步一步靠近应用。刚刚大获全胜的K8s为Istio准备了一个非常好的基石,而Istio的历史使命,就是继k8s拿下容器之后,更进一步,拿下微服务!
2017年,Istio稳步向前,先后发布0.1 / 0.2 / 0.3 / 0.4 四个版本,在2018年初,Istio的发布周期修改为每月一次。
在社区方面,Istio借助Google和IBM的大旗,外加自身过硬的实力、先进的理念,很快获得了社区的积极响应和广泛支持。包括Oracle和Red Hat在内的业界大佬都明确表示对支持Istio,而Isito背后,还有日渐强大的Kubernetes和CNCF社区。
在平台支持方面,Istio的初期版本只支持k8s平台,从0.3版本开始提供对非k8s平台的支持。从策略上说,Istio借助了k8s,但是没有强行绑定在k8s上。
Istio面世之后,赞誉不断,尤其是Service Mesh技术的爱好者,可以说是为之一振:以新一代Service Mesh之名横空出世的Istio,对比Linkerd,优势明显。同时产品路线图上有一大堆令人眼花缭乱的功能。假以时日,如果Istio能顺利地完成开发,稳定可靠,那么这会是一个非常美好、值得憧憬的大事件,它的意义重大:
- 重新定义微服务开发方式,让Service Mesh成为主流技术
- 大幅降低微服务开发的入门门槛,让更多的企业和开发人员可以落地微服务
- 统一微服务的开发流程,标准化开发/运维方式
2018年上半年的Istio,在万众瞩目充满期待之时,突然陷入困境长达数月:开发进度放缓,代码质量下降,经常犯低级错误。表现令人惊讶和迷惑,好在这个状态在年中开始好转,进入下半年之后Istio开始稳打稳扎:
- 2018年6月1日,发布0.8.0 LTS版本,这是Istio第一个长期支持版本
- 2018年7月31日,发布令整个社区期待已久的1.0.0版本
- 2018年10月,预计发布1.1.0版本
从目前发展态势看,Istio慢慢的完善产品,表现相对2017年要成熟很多,虽然依然存在诸多问题,虽然依然缺乏大规模的落地实践。但相信随着时间的推移,Google和Istio社区应该能够继续向前推进。
背水一战的Buoyant
2017年底的KubeConf,在Service Mesh成为大会热点、Istio备受瞩目时,Buoyant公司出人意料地给了踌躇满志又稍显拖沓的Istio重重一击:
- 2017年12月5日,Conduit 0.1.0版本发布,Istio的强力竞争对手亮相KubeConf。
Conduit的整体架构和Istio一致,借鉴了Istio数据平面+控制平面的设计,同时别出心裁地选择了Rust编程语言来实现数据平面,以达成Conduit 宣称的更轻、更快和超低资源占用。
继Isito之后,业界第二款第二代Service Mesh产品就此诞生,一场大战就此浮出水面。Buoyant在Linkerd不敌Istio的恶劣情况下,绝地反击,祭出全新设计的Conduit作为对抗Istio的武器。
需要额外指出的是,作为一家初创型企业,在第一款主力产品Linkerd被Istio强力阻击之后,Buoyant已经身陷绝境,到了生死存亡之秋,作为背负公司期望,担负和Istio正面抗衡职责的Conduit,可谓压力巨大。
从目前得到的信息分析,Conduit明显是有备而来,针对Istio当前状况,针锋相对的:
- 编程语言:为了达成更轻、更快和更低资源消耗的目标,考虑到Istio的数据面板用的是基于C++语言的Envoy,Conduit跳过了Golang,直接选择了Rust,颇有些剑走偏锋的意味。不过,单纯以编程语言而言,在能够完全掌握的前提下,Rust的确是做Proxy的最佳选择。考虑到Envoy在性能方面的良好表现,Conduit要想更进一步,选择Rust也是可以理解。
- 架构设计:在借鉴Istio整体架构的同时,Conduit做了一些改进。首先Conduit控制平面的各个组件是以服务的方式提供功能的,极富弹性。另外,控制平面特意为定制化需求进行了可扩展设计,可以通过编写gPRC插件来扩展Conduit的功能而无需直接修改Conduit,这对于有定制化需求的客户是非常便利的。
然而,要抗衡Istio和其身后的Google与IBM,谈何容易。尤其控制平面选择Rust,成为一把双刃剑,固然Rust的上佳表现让Conduit在性能和资源消耗方面有不小的亮点,但是Rust毕竟是小众语言,普及程度远远不能和Java/C++/Golang相比,导致Conduit很难从社区借力,体现在Conduit的contributor数量长期停滞在20人上下。Conduit几乎是凭Buoyant以一家之力在独立支撑对抗Istio庞大的社区,终于难以为继:
- 2018年7月,Conduit 0.5发布,同时宣布这是 Conduit 最后一个版本,Conduit未来将作为Linkerd2.0的基础继续存在。随后Conduit的github仓库被从
runconduit/conduit更名为linkerd/linkerd2
在2017年5月Istio发布0.1版本之后,在巨大的生存压力下,Buoyant就一直在苦苦寻找出路,尝试过多种思路:
- 用Linkerd做数据平面,和Istio集成,替代Envoy。但Linkerd终究是Scala编写,做数据平面和Envoy比毫无优势,Istio官方也没有任何正面回应,不了了之
- 2017年底启动Conduit项目,剑走偏锋选择Rust做数据平面,但控制平面和Istio相比相去甚远,最终在2018年5月停止发展,转为Linkerd2.0。
- 2018年5月尝试在GraalVM上运行Linkerd,试图通过将Linkerd提前编译为本地可执行文件,以换取更快的启动时间和更少的内存占用。但后续未见有进一步的信息。
- 2018年5月启动Linkerd2.0,在Conduit的基础上(也许应该称为改名?)继续发展,定位为k8s平台上的轻量级Service Mesh。
作为Service Mesh先驱,Buoyant这两年中的发展道路,充满挑战,面对Istio和背后的Google,艰难险阻可想而知,期待他们在后面能有更好的表现。
其他参与者
Service Mesh市场,除了业界先驱Linkerd/Envoy,和后起之秀Istio/Conduit,还有一些其它的竞争者陆陆续续在2017和2018年进入这个市场。
Nginmesh
首先是nginmesh,来自大名鼎鼎的Nginx,定位为"Istio compatible service mesh using NGINX":
- 2017年9月,在美国波特兰举行的nginx.conf大会上,nginx宣布了nginmesh。随即在github上发布了0.1.6版本。
- 2017年12月6日,nginmesh 0.2.12版本发布
- 2017年12月25日,nginmesh 0.3.0版本发布
之后沉寂过一段时间,后来又突然持续更新,接连发布了几个版本。但是,在2018年7月发布0.7.1版本之后,就停止提交代码。
Aspen Mesh
来自大名鼎鼎的F5 Networks公司,基于Istio构建,定位企业服务网格,口号是"Service MeshMade Easy"。Aspen Mesh项目据说启动非常之早,在2017年5月Istio发布0.1版本不久之后就开始组件团队进行开发,但是一直以来都非常低调,外界了解到的信息不多。
在2018年9月,Aspen Mesh 1.0发布,基于Istio 1.0。注意这不是一个开源项目,但是可以在Aspen Mesh的官方网站上申请免费试用。
Consul Connect
Consul是来自HashiCorp公司的产品,主要功能是服务注册和服务发现,基于Golang和Raft协议。
在2018年6月26日发布的Consul 1.2版本中,提供了新的Connect功能,能够将现有的Consul集群自动转变为Service Mesh。Connect 通过自动TLS加密和基于鉴权的授权机制支持服务和服务之间的安全通信。
Kong
Kong是被广泛使用的开源API Gateway,在2018年9月18号,kong宣布1.0版本准备发布(实际为9月26日在github上发布了1.0.0rc1版本,GA版本即将发布),而在1.0发布之后kong将转型为服务控制平台,支持Service Mesh。
比较有意思的是,Kong CTO Marco Palladino 撰文提出"Service Mesh Pattern"的概念,即Service Mesh是一种新的模式,而不是一种新的技术。
Maistra
2018年9月,Red Hat的OpenShift Service Mesh技术预览版上线,基于Istio。
Red Hat是Istio项目的早期采用者和贡献者,希望将Istio正式成为OpenShift平台的一部分。Red Hat为OpenShift上的Istio开始了一个技术预览计划,为现有的OpenShift Container Platform客户提供在其OpenShift集群上部署和使用Istio平台的能力。
Red Hat正在与上游Istio社区合作,以帮助推进Istio框架,按照Red Hat的惯例,围绕Istio的工作也是开源的。为此Red Hat创建了一个名为Maistra的社区项目。
Service Mesh国内发展
2017年,随着Service Mesh的发展,国内技术社区也开始通过新闻报道/技术文章等开始接触Service Mesh,但是传播范围和影响力都非常有限。直到2017年底才剧烈升温,开始被国内技术社区关注:
- 2017年10月QCon上海站,来自敖小剑的名为”Service Mesh:下一代微服务”的演讲,成为Service Mesh技术在国内大型技术峰会上的第一次亮相。
- 2017年12月,在全球架构师峰会(ArchSummit)2017北京站上,华为田晓亮分享了”Service Mesh在华为云的实践”。
- 2017年12月,新浪微博周晶分享Service Mesh在微博的落地情况。
- 2018年6月,Service Mesh中国技术社区成立,网站servicemesher.com开通,并开始在杭州,北京,深圳组织多场线下Meetup,同时组织翻译Envoy,Istio官方文档和各种博客文章,大力推动了Service Mesh在国内的交流与发展。
- 2018年7月,Istio核心开发团队成员Lin Sun在ArchSummit2018深圳站进行了名为"Istio-构造、守护、监控微服务的守护神"的演讲,这是Istio官方在国内第一次亮相。
之后,作为Service Mesh国内最早的开发和实践者,以下公司相继宣布和开源了自己的Service Mesh产品:
- 2017年底,新浪微博Service Mesh的核心实现,跨语言通信和服务治理已经在Motan系列项目中提供
- 2018年6月,蚂蚁金服对外宣布Service Mesh类产品SOFAMesh,这是一个基于Istio的增强扩展版本,并使用基于Golang开发的SOFAMosn作为数据平面替代Envoy。
- 2018年8月,华为开源了基于Golang的Service Mesh产品——Mesher。
从2017年底开始,国内技术社区就对Service Mesh保持密切关注,尤其在Servicemesher社区成立后,社区内的分享和讨论非常密切,形成了良好的技术交流氛围。以蚂蚁金服、新浪微博、华为为代表的前锋力量相继开源为国内Service Mesh社区的繁荣注入了活力,以InfoQ为代表的技术媒体也一直保持对Service Mesh这种前沿技术的关注。
总结
Service Mesh在过去的两年间,迅猛发展,涌现出多个产品,市场竞争激烈。而目前看,Istio借助k8s和云原生的大潮,依托Google在社区的巨大号召力,发展势头良好,有望成为这一轮大战的赢家。
在下一章,我们将详细介绍Istio的架构和功能。
2 - (2021)服务网格除了 Istio,其实你还可以有其它 8 种选择
介绍 9 种较受欢迎的用以支撑微服务开发的服务网格框架,每种方案都给出了其适用场景。
前言
9 open-source service meshes compared
Bill Doerrfeld, Consultant, Doerrfeld.io
https://techbeacon.com/app-dev-testing/9-open-source-service-meshes-compared
服务网格除了 Istio,其实你还可以有其它 8 种选择
https://z.itpub.net/article/detail/91AA8B3895CE8F037D73675116731CED
哪种服务网格最适合你的企业?近年来,Kubernetes 服务网格框架数量增加迅速,使得这成为一个棘手的问题。
下面将介绍 9 种较受欢迎的用以支撑微服务开发的服务网格框架,每种方案都给出了其适用场景。
什么是服务网格
服务网格近年来有很高的话题度,背后的原因是什么?
微服务已经成为一种灵活快速的开发方式。然而,随着微服务数量成倍数地增长,开发团队开始遇到了部署和扩展性上的问题。
容器和 Kubernetes 这样的容器编排系统 ,将运行时和服务一起打包进镜像,调度容器到合适的节点,运行容器。这个方案可以解决开发团队遇到的不少问题[1]。然而,在这个操作流程中仍存在短板:如何管理服务间的通信。
在采用服务网格的场景下,以一种和应用代码解耦的方式,增强了应用间统一的网络通信能力。服务网格扩展了集群的管理能力,增强可观测性、服务发现、负载均衡、IT 运维监控及应用故障恢复等功能。
服务网格概览
服务网格一直有很高的热度。正如 Linkerd 的作者 William Morgan 所提到[2]的:“服务网格本质上无非就是和应用捆绑在一起的用户空间代理。” 此说法相当简洁,他还补充道,“如果你能透过噪音看清本质,服务网格能给你带来实实在在的重要价值。”
Envoy 是许多服务网格框架的核心组件,是一个通用的开源代理,常被用于 Pod 内的 sidecar 以拦截流量。也有服务网格使用另外的代理方案。
若论具体服务网格方案的普及程度,Istio 和 Linkerd 获得了更多的认可。也有其它可选项,包括 Consul Connect,Kuma,AWS App Mesh和OpenShift。下文会阐述9种服务网格提供的关键特性。
Istio
Istio 是基于 Envoy 构建的一个可扩展的开源服务网格。开发团队可以通过它连接、加密、管控和观察应用服务。Istio 于 2017 年开源,目前 IBM、Google、Lyft 仍在对其进行持续维护升级。Lyft 在 2017 年把 Envoy 捐赠给了 CNCF。
Istio 花了不少时间去完善增强它的功能特性。Istio 的关键特性包括负载均衡、流量路由、策略创建、可度量性及服务间认证。
Istio 有两个部分组成:数据平面和控制平面。数据平面负责处理流量管理,通过 Envoy 的 sidecar 代理来实现流量路由和服务间调用。控制平面是主要由开发者用来配置路由规则和观测指标。
Istio 观测指标是细粒度的属性,其中包含和服务行为相关的特定数据值。下面是个样例:
request.path: xyz/abc
request.size: 234
request.time: 12:34:56.789 04/17/2017
source.ip: [192 168 0 1]
destination.service.name: example
与其他服务网格相比,Istio 胜在其平台成熟度以及通过其 Dashbaord
着重突出的服务行为观测和业务管理功能,然而也因为这些高级特性和复杂的配置流程,Istio 可能并不如其它一些替代方案那样容易上手。
Linkerd
按照官网的说法,Linkerd 是一个轻量级、安全优先的 Kubernetes 服务网格。它的创建流程快到让人难以置信(据称在 Kubernetes 安装只需要 60 秒),这是大多数开发者喜闻乐见的。Linkerd 并没有采用基于 Envoy 的构建方案。而是使用了一个基于 Rust 的高性能代理 linkerd2-proxy,这个代理是专门为 Linkerd 服务网格编写的。
Linkerd 由社区驱动,是 100% 的 Apache 许可开源项目。它还是 CNCF 孵化项目。Linkerd 始于 2016 年,维护者也花了不少时间去解决其中的缺陷。
使用 Linkerd 服务网格,应用服务可以增强其可靠性、可观测性及其在 Kubernetes 上部署的安全性。举个例子,可观测性的增强可以帮助用户解决服务间的延迟问题。使用 Linkerd 不要求用户做很多代码调整或是花费大量时间写 YAML 配置文件。可靠的产品特性和正向的开发者使用回馈,使得 Linkerd 成为服务网格中一个强有力的竞争者。
Consul Connect
Consul Connect 是来自 HashiCorp 的服务网格,专注于路由和分段,通过应用级的 sidecar 代理来提供服务间的网络特性。Consult Connect 侧重于应用安全,提供应用间的双向 TLS 连接以实现授权和加密。
Consult Connect 独特的一点是提供了两种代理模式。一种是它内建的代理,同时它还支持 Envoy 方案。Connect 强调可观测性,集成了例如 Prometheus 这样的工具来监控来自 sidecar 代理的数据。Consul Connect 可以灵活地满足开发者使用需求。比如,它提供了多种方式注册服务:可以从编排系统注册,可以通过配置文件,通过 API 调用,或是命令行工具。
Kuma
Kuma 来源于 Kong,自称是一个非常好用的服务网格替代方案。Kuma 是一个基于 Envoy 的平台无关的控制平面。Kuma 提供了安全、观测、路由等网络特性,同时增强了服务间的连通性。Kuma 同时支持 Kubernetes 和虚拟机。
Kuma 让人感兴趣的一点是,它的企业版可以通过一个统一控制面板来运维管理多个互相隔离独立的服务网格。这项能力可以满足安全要求高的使用场景。既符合隔离的要求,又实现集中控制。
Kuma 也是相对容易安装的一个方案。因为它预先内置了不少策略。这些策略覆盖了常见需求,例如路由,双向 TLS,故障注入,流量控制,加密等场景。
Kuma 原生兼容 Kong,对于那些已经采用 Kong API 管理的企业组织,Kuma 是个非常自然而然的候选方案。
Maesh
Maesh 是来自 Containous 的容器原生的服务网格,标榜自己是比市场其它服务网格更轻量级更易用的方案。和很多基于 Envoy 构建的服务网格不同,Maesh 采用了 Traefik, 一个开源的反向代理和负载均衡器。
Maesh 并没有采用 sidecar 的方式进行代理,而是在每个节点部署一个代理终端。这样做的好处是不需要去编辑 Kubernetes 对象,同时可以让用户有选择性地修改流量,Maesh 相比其他服务网格侵入性更低。Maesh 支持的配置方式:在用户服务对象上添加注解或是在服务网格对象上添加注解来实现配置。
实际上,SMI 是一种新的服务网格规范格式,对 SMI 的支持 Maesh 独有的一大亮点。随着 SMI 在业界逐渐被采用,可以提高可扩展性和减缓供应商绑定的担忧。
Maesh 要求 Kubernetes 1.11 以上的版本,同时集群里安装了 CoreDNS/KubeDNS。这篇安装指南[3]演示了如何通过 Helm v3 快速安装 Maesh。
$ helm repo add maesh https://containous.github.io/maesh/charts
$ helm repo update
$ helm install maesh maesh/maesh
ServiceComb-mesher
Apache 软件基金会形容旗下的 ServiceComb-mesher “是一款用 Go 语言实现的高性能服务网格”。Mesher 基于一个非常受欢迎的 Go 语言微服务开发框架 Go Chassis[4] 来设计实现。因此,它沿袭了 Go Chassis 的一些特性如服务发现、负载均衡、错误容忍、路由管理和分布式追踪等特性。
Mesher 采用了 sidecar 方式;每个服务有一个 Mesher sidecar 代理。开发人员通过 Admin API 和 Mesher 交互,查看运行时信息。Mesher 同时支持 HTTP 和 gRPC,可快速移植到不同的基础设施环境,包括 Docker、Kubernetes、虚拟机和裸金属机环境。
Network Service Mesh(NSM)
Network Service Mesh(NSM)是一款专门为 telcos 和 ISPs 设计的服务网格。它提供了一层级用以增强服务在 Kubernetes 的低层级网络能力。NSM 目前是 CNCF 的沙箱项目。
根据 NSM 的文档说明,“经常接触 L2/L3 层的网络运维人员抱怨说,适合他们的下一代架构的容器网络解决方案几乎没有”。
因此,NSM 在设计时就考虑到一些不同使用场景,尤其是网络协议不同和网络配置混杂的场景。这使得 NSM 对某些特殊场景具备相当吸引力,例如边缘计算、5G 网络和 IOT 设备等场景。NSM 使用简单直接的 API 接口去实现容器和外部端点的之间的通信。
和其他服务网格相比,NSM 工作在另一个不同的网络层。VMware 形容 NSM“专注于连接”。GitHub 的文档[5]演示了 NSM 是如何与 Envoy协同工作的。
AWS App Mesh
AWS APP Mesh 为开发者提供了“适用于不同服务的应用层的网络”。它接管了服务的所有网络流量,使用开源的 Envoy 代理去控制容器的流量出入。AWS App Mesh 支持 HTTP/2 gRPC。
AWS App Mesh 对于那些已经将容器平台深度绑定 AWS 的公司而言,会是相当不错的服务网格方案。AWS 平台包括 AWS Fargate,Amazon Elastic Container Service,Amazon Elastic Kubernetes Service(EKS),Amazon Elastic Compute Cloud(EC2),Kubernetes on EC2,包括 AWS App Mesh 不需要付额外费用。
AWS App Mesh 和 AWS 生态内的监控工具无缝兼容。这些工具包括 CloudWatch 和 AWS X-Ray,以及一些来自第三方供应商的工具。因为 AWS 计算服务支持 AWS Outposts,AWS App Mesh 可以和混合云和已经部署的应用良好兼容。
AWS App Mesh 的缺点可能是使得开发者深度绑定了单一供应商方案,相对闭源,可扩展性缺失。
OpenShift Service Mesh by Red Hat
OpenShift 是来自红帽的一款帮助用户“连接、管理、观测微服务应用”的容器管理平台。OpenShift 预装了不少提升企业能力的组件,也被形容为企业级的混合云 Kubernetes 平台。
OpenShift Service Mesh 基于开源的 Istio 构建,具备 Isito 的控制平面和数据平面等特性。OpenShift 利用两款开源工具来增强 Isito 的追踪能力和可观测性。OpenShift 使用 Jaeger 实现分布式追踪,更好地跟踪请求是如何在服务间调用处理的。
另一方面,OpenShift 使用了 Kiali 来增强微服务配置、流量监控、跟踪分析等方面的可观测性。
如何选择
正如文中所提到的,可供选择的服务网格方案[6]有很多,同时还有新的方案在涌现。当然,每一种方案在技术实现上都略有不同。选择一款合适的服务网格,主要考虑的因素包括,你能接受它带来多大的侵入性,它的安全性如何,以及平台成熟度等。
以下几点可以帮助 DevOps 团队选择一款适合他们场景的服务网格:
- 是否依赖Envoy。Envoy 有一个活跃的社区生态。开源,同时是许多服务网格的底座。Envoy 具备的丰富特性使得其成为一个很难绕过的因素。
- 具体使用场景。服务网格为微服务而生。如果你的应用是一个单体的庞然大物,那你在服务网格上的投入可能达不到预期的收益。如果不是所有应用都部署在 Kubernetes,则应该优先考虑平台无关的方案。
- 现有容器管理平台。有些企业已经使用了特定供应商的生态来解决容器编排问题,例如 AWS 的 EKS,红帽的 OpenShift,Consul。沿袭原有的生态,可以继承并拓展原有的特性。而这些可能是开源方案所不能提供的。
- 所在行业。许多服务网格不是为特定行业专门设计的。Kuma 统一管理多个隔离服务网格的能力可能更适用于收到高度管制的金融行业。底层网络 telcos 和 ISPs 则更应该考虑 Network Service Mesh。
- 对可视化的要求。可观测性是服务网格的核心能力之一。考虑进一步定制和更深度能力的团队应该优先考虑 Istio 或 Consul。
- 是否遵循开发标准。遵循开发标准使得你的平台更具备前瞻性和可扩展性。这使得企业会倾向于采用支持 SMI 的方案,Maesh 或其他基金会孵化的项目如 Linkerd。
- 是否重视用户体验。考虑运维人员的易用性是评判新工具的关键指标。这方 Linkerd 似乎在开发者中间口碑不错。
- 团队准备。评估你的团队所具备的资源和技术储备,在技术选型时决定你们适合用基于 Envoy 的 Istio,或是供应商抽象封装的方案,例如 OpenShift。
这些考虑因素没有覆盖到全部场景。此处仅是抛砖引玉,引起读者的思考。希望读完上面所列的服务网格清单,和相关的决策因素之后,你们的团队能找到新的方法去改善微服务应用的网络特性。
相关链接:
- https://techbeacon.com/app-dev-testing/3-reasons-why-you-should-always-run-microservices-apps-containers
- https://buoyant.io/service-mesh-manifesto/
- https://docs.mae.sh/quickstart/
- https://github.com/go-chassis/go-chassis
- https://github.com/networkservicemesh/examples/tree/master/examples/envoy_interceptor
- https://techbeacon.com/app-dev-testing/make-your-app-architecture-cloud-native-service-mesh
3 - (2021)服务网格联网:使用案例、最佳实践和顶级服务网格选择比较
研究使用案例,比较顶级网格选项,并讨论最佳做法。
前言
Networking with a service mesh: use cases, best practices, and comparison of top mesh options
作者 Amir Kaushansky
服务网格联网:使用案例、最佳实践和顶级服务网格选择比较
https://cloudnative.to/blog/top-service-mesh-pk/
译者 宋净超(Jimmy Song) 发表于 2021年7月19日
本文译自在 CNCF 官网上发布的博客 Networking with a service mesh: use cases, best practices, and comparison of top mesh options,有删节。作者是 Amir Kaushansky,ARMO 公司的产品 VP。
服务网格技术是随着微服务结构的普及而出现的。由于服务网格促进了网络与业务逻辑的分离,它使你能够专注于你的应用程序的核心竞争力。
微服务应用程序分布在多个服务器、数据中心或大陆上,使它们高度依赖网络。服务网格通过用路由规则和服务间包的动态方向控制流量来管理服务间的网络流量。
在这篇文章中,我们将研究使用案例,比较顶级网格选项,并讨论最佳做法。
让我们从使用服务网格的最常见场景开始。
使用案例
服务网格是一种连接微服务和管理它们之间流量的架构方法。它们在一个组织的许多层面上被大量用于生产。因此,有一些标准化的、被广泛接受的用例。
可观察性
假设你有一个后端服务的实例响应缓慢,在你的整个堆栈中造成了一个瓶颈。然后,来自前端服务的请求将超时,并重新尝试连接到缓慢的服务实例。在服务网格的帮助下,你可以使用一个断路器,确保前端实例只与健康的后端实例连接。因此,使用服务网格可以提高堆栈的可见性,并帮助你排除问题。
部署策略
部署策略(蓝/绿部署、金丝雀等)正在成为发布云原生应用升级的规范。服务网格允许部署策略,因为大多数部署策略都是基于将流量转移到特定实例。例如,你可以在服务网格中创建流量规则,以便只有一小部分用户(比如10%)会接触到新版本。
如果一切按预期进行,你可以将所有流量转移到最新版本,完成你的金丝雀部署。也建议检查Kubernetes的内部部署策略,并与你的应用程序的要求相匹配。
测试
为了保持你的生产堆栈的安全性,最好通过测试延迟、超时和灾难恢复来加固它们。
服务网格允许你通过延迟和不正确的响应在系统中制造混乱来测试其稳健性。例如,通过在服务网格流量规则中注入延迟,你可以测试当你的数据库对其查询响应缓慢时,前端和后端将如何表现。
API网关
API网关是server-client的设计模式,它使得从一个单一的入口点管理API成为可能。在服务网格的帮助下,你可以使用同样的方法进行服务间的通信,并在你的集群中创建复杂的API管理方案。建议你查看Gateway API,以便在即将到来的Kubernetes版本中把这些想法纳入本地Kubernetes资源。
服务网格作为 “智能 “胶水,通过流量策略、限制和测试功能动态地连接微服务。随着服务网格的日益普及,许多新的、被广泛接受的用例将加入上述的用例。
现在让我们来看看现有的顶级服务网格软件的优点和缺点。
顶级网格选项的比较
虽然每次会议上总有一些初创公司推出花哨的服务网格产品,但在云原生世界中,只有三个顶级网格选项被广泛使用。Istio、Linkerd和Consul Connect。它们都是拥有活跃社区的开源产品。基于他们的愿景和实施,他们也都有各自的优点和缺点。
Istio
Istio是一个Kubernetes原生的服务网格,最初由Lyft开发,并在业界被广泛采用。领先的云Kubernetes供应商,如谷歌、IBM和微软,都将Istio作为其服务的默认服务网格。Istio提供了一套强大的功能来创建服务之间的连接,包括请求路由、超时、断路和故障注入。此外,Istio通过延迟、流量和错误等指标对应用程序进行深入了解。
优点
最活跃的社区,业界采用率高,与Kubernetes和虚拟机一起使用。
缺点
学习曲线陡峭,对集群有很大的开销,没有本地管理仪表板。
Linkerd
Linkerd是第二大流行的服务网格,是云原生计算基金会(CNCF)的一部分。
从架构的角度来看,Linkerd类似于Istio,但有更多的灵活性。这种灵活性来自于可插拔架构的多个维度。例如,在连接方面,Linkerd与最流行的入口控制器一起工作,如Nginx、Traefik或Kong。同样,除了它自己的GUI,它还与Grafana、Prometheus和Jaeger合作,以实现可观察性。
优点
文档和简单的安装,在行业中得到采用,和企业支持。
缺点
只适用于Kubernetes,不支持虚拟机缺少一些网络路由功能,如断路或速率限制。
Consul Connect
Consul是分布式应用中最流行的服务发现和键/值存储,直到其母公司HashiCorp以Consul Connect的名义转换为服务网格。
因此,Consul Connect有一个混合架构,在应用程序旁边有Envoy sidecar,其控制平面和键/值存储是用Go开发的。从连接性和安全性的角度来看,Consul Connect与它的替代品相比并没有提供突出的功能。然而,它的配置和复杂性较低,使得它更容易上手–就像云原生世界中的其他HashiCorp工具一样。
优点 有HashiCorp的支持和企业级支持的可用性,可以与虚拟机和Kubernetes一起工作。
缺点
开源社区有限,缺乏完整和易于理解的文档 。
下面的图表提供了这三大解决方案之间关键差异的概述。
| 对比项 | Istio | Linkerd | Consul Connect |
|---|---|---|---|
| 支持的平台 | Kubernetes 和虚拟机 | Kubernetes | Kubernetes 和虚拟机 |
| 支持的 Ingress 控制器 | Istio ingress | 任意 | Envoy |
| 流量管理功能 | 蓝绿部署、断路和速率控制 | 蓝绿部署 | 蓝绿部署、断路和速率控制 |
| Prometheus 和 Grafana 支持 | 是 | 是 | 否 |
| 混沌测试 | 是 | 是 | 否 |
| 管理复杂度 | 高 | 低 | 中 |
| 原生 GUI | 否 | 是 | 是 |
最佳实践和挑战
服务网格使你的集群和应用中的服务间通信标准化和自动化。然而,由于产品的复杂性和基础设施的不同,服务网格产品并不简单。在使用服务网格时,以下关于挑战和最佳实践的说明将为你提供一些有用的指导。
自动化
服务网格的配置包括流量规则、速率限制和网络设置。该配置可以帮助你从头开始安装,升级版本,以及在集群之间迁移。因此,建议把配置当作代码来处理,并遵循GitOps的方法和持续部署管道。
服务网格产品在拥有大量服务器的少数集群中工作得更好,而不是拥有较少实例的许多集群。因此,建议尽可能地减少冗余集群,使你能够利用简单的操作和集中配置的服务网格方法。
监控和请求跟踪
服务网格产品是复杂的应用,管理着更复杂的分布式应用的流量。因此,指标收集、可视化和仪表板对系统的可观察性至关重要。利用Prometheus或Grafana或您的服务网格提供的任何其他集成点,根据您的要求创建警报。
安全性
大多数服务网格产品,包括前三名,都实现了一套基本的安全功能:mTLS、证书管理、认证和授权。你还可以定义和执行网络策略,以限制集群中运行的应用程序之间的通信。
不过,应该注意的是,定义网络策略不是一项简单的任务。你需要覆盖当前运行的应用程序的所有场景,并考虑未来的可扩展性。因此,利用服务网格的网络策略对用户来说并不友好,容易出现错误和安全漏洞。
然而,利用服务网格来创建安全的网络策略有几个缺点。
首先,用户必须准确定义集群所需要的策略——在微服务激增和不断变化的环境中,这是一项不容易的任务。因此,服务网格的策略需要经常改变,如果一个微服务改变其行为,可能会破坏生产。
其次,根据设计,服务网格使用sidecar代理来控制策略,所以任何从容器中出来的连接都会被自动视为合法流量,如果攻击者闯入一个容器,他们会自动继承该容器的网络身份,从而可以做任何原始容器可以做的事情。
最后,由于每个连接都要经过代理,用户在集群中使用它来加密流量时,会看到明显的性能下降。
总结一下:服务网格解决方案并不关心谁在发送或接收数据。只要网络策略允许,任何恶意的或配置错误的应用程序都可以检索你的敏感数据。因此,考虑开销更少、可操作性更强的整体方法至关重要,而不是盲目地只相信服务网格产品的安全措施。
总结
服务网格以动态、安全和可扩展的方式连接分布式微服务。目前有广泛接受的用例和实现这些用例的顶级产品。然而,由于云基础设施和应用需求高度复杂,服务网格不是银弹。
当涉及到安全问题时,保护应用程序和运行时环境不在服务网格产品的范围内,而且仅仅为了安全而安装一个服务网格是矫枉过正的,因为它在集群中产生了很高的开销。
4 - (2021)Google Cloud 服务网格: Traffic Director 与 Anthos Service Mesh 的左右互搏
Google 同时推出两个 Servcie Mesh 产品的原因是什么?这两个产品的定位有何不同?
内容出处
Google Cloud 服务网格: Traffic Director 与 Anthos Service Mesh 的左右互搏
作为开源 Service Mesh 明星项目 Istio 背后的主要厂商,Google 也在其公有云上推出了 Service Mesh 管理服务。让人迷惑的是 Google Cloud 上有两个 Service Mesh 产品:Traffic Director 与 Anthos Service Mesh。Google 同时推出两个 Servcie Mesh 产品的原因是什么?这两个产品的定位有何不同?
https://cloudnative.to/blog/20200818-google-cloud-mesh/
作者 赵化冰 发表于 2020年8月26日
作为开源 Service Mesh 明星项目 Istio 背后的主要厂商,Google 也在其公有云上推出了 Service Mesh 管理服务。让人迷惑的是 Google Cloud 上有两个 Service Mesh 产品:Traffic Director 与 Anthos Service Mesh。Google Cloud 首先在2019年3月发布了其第一个 Service Mesh 产品 Traffic Director,随后不久在2019 年9月紧接着发布了另一个 Service Mesh 产品 Anthos Service Mesh,随后两个产品独立并行发展,直到如今。
Google Cloud 同时推出两个 Service Mesh 产品的原因是什么?这两个产品的定位有何不同?本文将分别分析这两个产品的架构和功能,以试图解答该疑问。
Traffic Director
Traffic Director 是 Google Cloud 专为服务网格打造的全托管式流量控制平面,用户不需要对 Traffic Director 进行部署,维护和管理。我们可以把 Traffic Director 看作一个托管的 Pilot(备注:并不确定其内部是否使用的 Pilot),其只提供了流量管理能力,不提供 Istio 控制面的其他能力。用户可以使用 Traffic Director 创建跨区域的、同时支持集群和虚拟机实例的服务网格,并对多个集群和虚拟机的工作负载进行统一的流量控制。Traffic Director 托管控制面 提供了跨地域容灾能力,可以保证99.99%的SLA。
总而言之,Traffic Director 的关键特性包括:
- 全托管控制面
- 控制面高可用
- 同时支持 K8s 集群和虚拟机
- 跨地域的流量管理
Traffic Director 架构
Traffic Director 的总体架构和 Istio 类似,也采用了“控制面 + 数据面”的结构,控制面托管在 Google Cloud 中,对用户不可见。用户只需要在创建 project 时启用 Traffic Director API,即可使用 Traffic Director 提供的网格服务。数据面则采用了和 Istio 相同的 Envoy 作为 proxy。 控制面和数据面采用标准的 xDS v2 进行通信。控制面对外采用了一套自定义的 API 来实现流量管理,并不支持 Istio API。Traffic Director 也没有采用 Istio/K8s 的服务发现,而是采用了一套 Google Cloud 自己的服务注册发现机制,该服务注册发现机制以统一的模型同时支持了容器和虚拟机上的服务,并为工作负载提供了健康检测。
Traffic Director 架构

服务注册发现机制
Traffic Director 采用了 Google Cloud 的一种称为 Backend Service 的服务注册机制。通过 Backend Service 支持了 GKE 集群中容器工作负载和虚拟机工作负载两种方式的服务注册发现,不过和 Istio 不同的是,Traffic Director 并不支持 K8s 原生的服务注册发现机制。
服务注册发现资源模型
Traffic Director 的服务注册发现资源模型如下图所示,图中蓝色的图形为 Traffic Director 中使用的资源,桔色的图形为这些资源对应在 K8s 中的概念。Backend Service 是一个逻辑服务,可以看作 K8s 中的 Service,Backend Service 中可以包含 GKE 集群中的 NEG (Network Endpoint Group),GCE 虚拟机 的 MIG (Managed Instance Group),或者无服务的 NEG 。NEG 中则是具体的一个个工作负载,即服务实例。
Traffic Director 服务发现资源模型

Google Cloud 的这一套服务注册的机制并不只是为 Traffic Director 而定制的,还可以和 Google Cloud 上的各种负载均衡服务一起使用,作为负载均衡的后端。熟悉 K8s 的同学应该清楚,进入 K8s 集群的流量经过 Load Balancer 后会被首先发送到一个 node 的 nodeport 上,然后再通过 DNAT 转发到 Service 后端的一个 Pod IP 上。Google Cloud 在 cluster 上提供了一个 VPC native 的网络特性,可以在 VPC 中直接路由 Pod ,在打开 VPC native 特性的集群中,通过将 NEG 而不是 K8s service 放到 Load balancer 后端,可以跳过 Kubeproxy iptables 转发这一跳,直接将流量发送到 Pod,降低转发延迟,并可以应用更灵活的 LB 和路由算法。
虽然 Backend Service 已经支持了无服务 NEG,但目前 Traffic Director 还不支持,但从资源模型的角度来看,应该很容易扩展目前的功能,以将无服务工作负载加入到服务网格中。
下面举例说明如何创建 Backend Service,并将 GKE 和 VM 中运行的服务实例加入到 Backend Service中,以了解相关资源的内部结构。
注册 GKE 集群中的容器服务
1、 创建 GKE NEG:在 K8s Service 的 yaml 定义中通过 annotation 创建 NEG

2、 创建防火墙规则:需要创建一条防火墙规则,以允许 gcloud 对 GKE NEG 中的服务实例进行健康检查
gcloud compute firewall-rules create fw-allow-health-checks \
--action ALLOW \
--direction INGRESS \
--source-ranges 35.191.0.0/16,130.211.0.0/22 \
--rules tcp
3、创建健康检查
gcloud compute health-checks create http td-gke-health-check \
--use-serving-port
4、创建 Backend Service,创建时需要指定上一步创建的健康检查
gcloud compute backend-services create td-gke-service \
--global \
--health-checks td-gke-health-check \
--load-balancing-scheme INTERNAL_SELF_MANAGED
5、将 GKE NEG 加入到上一步创建的 Backend service 中
NEG_NAME=$(gcloud beta compute network-endpoint-groups list \
| grep service-test | awk '{print $1}')
gcloud compute backend-services add-backend td-gke-service \
--global \
--network-endpoint-group ${NEG_NAME} \
--network-endpoint-group-zone us-central1-a \
--balancing-mode RATE \
--max-rate-per-endpoint 5
注册 GCE 虚拟机服务
1、 创建虚机模版:在创建模版时可以通过命令参数 –service-proxy=enabled 声明使用该模版创建的虚拟机需要安装 Envoy sidecar 代理
gcloud beta compute instance-templates create td-vm-template-auto \
--service-proxy=enabled
2、 创建 MIG:使用虚拟机模版创建一个 managed instance group,该 group 中的实例数为2
gcloud compute instance-groups managed create td-vm-mig-us-central1 \
--zone us-central1-a
--size=2
--template=td-vm-template-auto
3、 创建防火墙规则
gcloud compute firewall-rules create fw-allow-health-checks \
--action ALLOW \
--direction INGRESS \
--source-ranges 35.191.0.0/16,130.211.0.0/22 \
--target-tags td-http-server \
--rules tcp:80
4、 创建健康检查
gcloud compute health-checks create http td-vm-health-check
5、 创建 Backend Service,创建时需要指定上一步创建的健康检查
gcloud compute backend-services create td-vm-service \
--global \
--load-balancing-scheme=INTERNAL_SELF_MANAGED \
--connection-draining-timeout=30s \
--health-checks td-vm-health-check
6、 将 MIG 加入到上一步创建的 Backend service 中
gcloud compute backend-services add-backend td-vm-service \
--instance-group td-demo-hello-world-mig \
--instance-group-zone us-central1-a \
--global
流量管理实现原理
Traffic Diretor 的主要功能就是跨地域的全局流量管理能力,该能力是建立在 Google Cloud 强大的 VPC 机制基础上的, Google Cloud 的 VPC 可以跨越多个 Region,因此一个 VPC 中的服务网格中可以有来自多个 Region 的服务。另外 Traffic Director 并未直接采用 Istio 的 API,而是自定义了一套 API 来对网格中的流量进行管理。
控制面流量规则定义
Traffic Director 流量规则相关的控制面资源模型如下图所示,图中下半部分是 Istio 中和这些资源对应的 CRD。
- Forwarding Rule:定义服务的入口 VIP 和 Port。
- Target Proxy:用于关联 Forwarding Rule 和 URL Map,可以看作网格中代理的一个资源抽象。
- URL Map:用于设置路由规则,包括规则匹配条件和规则动作两部分。匹配条件支持按照 HTTP 的 Host、Path、Header进行匹配。匹配后可以执行 Traffic Splitting、Redirects、URL Rewrites、Traffic Mirroring、Fault Injection、Header Transformation 等动作。
- Backend Service:前面在服务发现中已经介绍了 Backend Service 用于服务发现,其实还可以在 Backen Service 上设置流量策略,包括LB策略,断路器配置,实例离线检测等。可以看到 Backend Service 在 Traffic Director 的流量管理模型中同时承担了 Istio 中的 ServiceEntry 和 Destionation Rule 两个资源等功能。
客户端直接通过 VIP 访问服务其实是一个不太友好的方式,因此我们还需要通过一个 DNS 服务将 Forwarding Rule 中的 VIP 和一个 DNS record 关联起来,在 Google Cloud 中可以采用 Cloud DNS 来将 Forwarding Rule 的 VIP 关联到一个内部的全局 DNS 名称上。
Traffic Director 流量管理资源模型

下面举例说明这些资源的定义,以及它们是如何相互作用,以实现Service Mesh中的流量管理。
下图中的forwarding rule定义了一个暴露在 10.0.0.1:80 上的服务,该服务对应的url map 定义了两条路由规则,对应的主机名分别为 * 和 hello-worold,请求将被路由到后端的 td-vm-service backend service 中的服务实例。

Forwarding Rule 定义

Target Proxy 定义

URL Map 定义

Backend Service 定义

Managed Instance Group 定义

数据面 Sidecar 配置
Traffic Director 将服务发现信息和路由规则转换为 Envoy 配置,通过 xDS 下发到 Envoy sidecar,控制面规则和数据面配置的对应关系下:
Forwarding Rule -> Envoy Listener
URL Map -> Envoy Route
Backend Service -> Envoy Cluster
NEG/MIG -> Envoy endpoint
Listener 配置
Listener 中的 Http Connection Manager filter 配置定义了 IP+Port 层面的入口,这里只接受 Forwarding Rule 中指定的 VIP 10.0.0.1。我们也可以在 Forwarding Rule 中将 VIP 设置为 0.0.0.0,这样的话任何目的 IP 的请求都可以处理。

Route 配置

Cluster 配置

高级流量规则
在 URL Map 中设置 Traffic Splitting
hostRules:
- description: ''
hosts:
- '*'
pathMatcher: matcher1
pathMatchers:
- defaultService: global/backendServices/review1
name: matcher1
routeRules:
- priority: 2
matchRules:
- prefixMatch: ''
routeAction:
weightedBackendServices:
- backendService: global/backendServices/review1
weight: 95
- backendService: global/backendServices/review2
weight: 5
在 Backend Service 中设置 Circuit Breaker
affinityCookieTtlSec: 0
backends:
- balancingMode: UTILIZATION
capacityScaler: 1.0
group:https://www.googleapis.com/compute/v1/projects/<var>PROJECT_ID</var>/zones/<var>ZONE</var>/instanceGroups/<var>INSTANCE_GROUP_NAME</var>
maxUtilization: 0.8
circuitBreakers:
maxConnections: 1000
maxPendingRequests: 200
maxRequests: 1000
maxRequestsPerConnection: 100
maxRetries: 3
connectionDraining:
drainingTimeoutSec: 300
healthChecks:
- https://www.googleapis.com/compute/v1/projects/<var>PROJECT_ID</var>/global/healthChecks/<var>HEALTH_CHECK_NAME</var>
loadBalancingScheme: INTERNAL_SELF_MANAGED
localityLbPolicy: ROUND_ROBIN
name: <var>BACKEND_SERVICE_NAME</var>
port: 80
portName: http
protocol: HTTP
sessionAffinity: NONE
timeoutSec: 30
从这两个规则的定义可以看出,虽然文件结构有所差异,但实际上 Traffic Director yaml 路由规则的定义和 Istio 非常相似。
与 Istio 相比,Traffic Director 的流量管理机制更为灵活,可以在 Mesh 中同时接入 K8s 集群和虚拟机中的工作负载。但 Traffic Director 需要手动进行较多的配置才能对服务进行管理,包括 backend service,forwarding rule,url map 和 DNS,而在 Istio 中,如果不需要进行特殊的路由和流量策略,这些配置都是不需要手动进行的,pilot 会自动创建默认配置。
Sidecar Proxy 部署机制
Traffic Director 数据面采用了和 Istio 相同的机制,通过 Iptables 规则将应用服务的出入流量重定向到 Envoy sidecar,由 Envoy 进行流量路由。Traffic Director 采用了下面的方式来在 K8s 集群的 Pod 或者虚拟机中安装数据面组件。
VM 手动部署
通过脚本从 gcloud 上下载 envoy 二机制,并安装 iptables 流量拦截规则,启动envoy。
# Add a system user to run Envoy binaries. Login is disabled for this user
sudo adduser --system --disabled-login envoy
# Download and extract the Traffic Director tar.gz file
# 下载traffic director相关文件
sudo wget -P /home/envoy https://storage.googleapis.com/traffic-director/traffic-director.tar.gz
sudo tar -xzf /home/envoy/traffic-director.tar.gz -C /home/envoy
#下载 Envoy 的初始化配置,配置中包含了控制面traffic director的地址
sudo wget -O - https://storage.googleapis.com/traffic-director/demo/observability/envoy_stackdriver_trace_config.yaml >> /home/envoy/traffic-director/bootstrap_template.yaml
# 设置iptables流量拦截规则的相关参数
sudo cat << END > /home/envoy/traffic-director/sidecar.env
ENVOY_USER=envoy
# Exclude the proxy user from redirection so that traffic doesn't loop back
# to the proxy
EXCLUDE_ENVOY_USER_FROM_INTERCEPT='true'
# Intercept all traffic by default
SERVICE_CIDR='10.10.10.0/24'
GCP_PROJECT_NUMBER='${GCP_PROJECT_NUMBER}'
VPC_NETWORK_NAME=''
ENVOY_PORT='15001'
ENVOY_ADMIN_PORT='15000'
LOG_DIR='/var/log/envoy/'
LOG_LEVEL='info'
XDS_SERVER_CERT='/etc/ssl/certs/ca-certificates.crt'
TRACING_ENABLED='true'
ACCESSLOG_PATH='/var/log/envoy/access.log'
END
sudo apt-get update -y
sudo apt-get install apt-transport-https ca-certificates curl gnupg2 software-properties-common -y
sudo curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add -
sudo add-apt-repository 'deb [arch=amd64] https://download.docker.com/linux/debian stretch stable' -y
sudo apt-get update -y
sudo apt-get install docker-ce -y
#下载envoy二机制
sudo /home/envoy/traffic-director/pull_envoy.sh
#设置iptables规则,启动envoy
sudo /home/envoy/traffic-director/run.sh start"
VM 自动部署
在创建虚拟机模版时添加注入proxy的参数,可以在VM中自动部署Envoy sidecar。
gcloud beta compute instance-templates create td-vm-template-auto \
--service-proxy=enabled
gcloud compute instance-groups managed create td-vm-mig-us-central1 \
--zone us-central1-a --size=2 --template=td-vm-template-auto
GKE 通过 deployment 部署
GKE 提供 yaml 模版,需要修改 deployment 文件,在 yaml 中增加 sidecar 相关的镜像。未提供 webhook,参见 Traffic Director 的示例文件。
VM和GKE混合部署示例
下面我们创建一个示例程序,将 V 和 GKE 中的服务同时加入到 traffic director 管理的 service mesh 中,以展示 traffic director 的对 VM 和容器服务流量统一管理能力。 该程序的组成如下图所示。程序中部署了三个服务,在 us-central1-a 中部署了两个 VM MIG 服务,在 us-west1-a 中部署了一个 GKE NEG 服务,这三个服务处于同一个 VPC 中,因此网络是互通的。

通过 us-central1-a region 上的客户端向三个服务分别发送请求。
echo Access service in VM managed instance group td-demo-hello-world-mig
echo
for i in {1..4}
do
curl http://10.0.0.1
sleep 1
done
echo
echo Access service in VM managed instance group td-observability-service-vm-mig
echo
for i in {1..4}
do
curl http://10.10.10.10
sleep 1
done
echo
echo Access service in GKE network endpoint group k8s1-e403ff53-default-service-test-80-e849f707
echo
for i in {1..4}
do
curl http://10.0.0.2
echo
sleep 1
done
服务端会在请求响应消息中打印自身的 host name。我们从客户端循环访问三个服务,从命令结果可见每次的输出是不同的,这是因为 envoy 会通过缺省 lb 算法将请求分发到不同的服务实例上。
Access service in VM managed instance group td-demo-hello-world-mig
<!doctype html><html><body><h1>td-demo-hello-world-mig-ccx4</h1></body></html>
<!doctype html><html><body><h1>td-demo-hello-world-mig-658w</h1></body></html>
<!doctype html><html><body><h1>td-demo-hello-world-mig-ccx4</h1></body></html>
<!doctype html><html><body><h1>td-demo-hello-world-mig-658w</h1></body></html>
Access service in VM managed instance group td-observability-service-vm-mig
<!doctype html><html><body><h1>td-observability-service-vm-mig-50tq</h1></body></html>
<!doctype html><html><body><h1>td-observability-service-vm-mig-16pr</h1></body></html>
<!doctype html><html><body><h1>td-observability-service-vm-mig-50tq</h1></body></html>
<!doctype html><html><body><h1>td-observability-service-vm-mig-16pr</h1></body></html>
Access service in GKE network endpoint group k8s1-e403ff53-default-service-test-80-e849f707
app1-84996668df-dlccn
app1-84996668df-t4qmn
app1-84996668df-dlccn
app1-84996668df-t4qmn
Anthos Service Mesh
Anthos Service Mesh 是 Google 混合云和多云解决方案 Anthos 中负责服务管理的部分。和 Traffic Director 的主要区别是,Anthos Service Mesh 直接采用了开源 Istio, 并且未对控制面进行托管,而是将 Istio 控制面部署在了用户集群中,只是将遥测信息接入了 Google Cloud,并在 Google cloud console 的 Anthos Service Mesh 界面中提供了服务网格的查看和监控界面。 Anthos Service Mesh关键特性包括:
- 原生Istio多集群方案
- 支持多云/混合云(不支持虚机)
- 集中的服务监控控制台。
Anthos 的整体架构
Google Cloud Anthos 旨在提供一个跨越 Google Cloud、私有云和其他公有云的统一解决方案,为客户在混合云/多云环境下的集群和应用管理提供一致的体验。Anthos 包含了统一的 GKE 集群管理,服务管理和配置管理三大部分功能。其中 Anthos Service Mesh 负责其中统一的服务管理部分,可以将部署在多个不同云环境中的 Istio 集群在 Anthos Service Mesh 控制台中进行统一的管理和监控。
Anthos 架构

Anthos GKE 集群管理
Anthos 对 On-Perm 和多云的 K8s 集群的管理采用了代理的方式,Anthos 会在每个加入 Anthos 的集群中安装一个 agent,由 agent 主动建立一个到 Anthos 控制面的连接,以穿透 NAT,连接建立后,Anthos 控制面会连接集群的 API Server,对集群进查看和行管理。
Anthos 采用 agent 接入 K8s 集群

Anthos Service Mesh 的混合云/多云解决方案
由于采用了开源 Istio,因此 Anthos Service Mesh 的混合云/多云解决方案实际上采用的是 Istio 的多集群方案。Istio 自身的多集群方案是非常灵活的,根据网络模式和控制面的安装模式,可以有多种灵活的搭配组合。Anthos Service Mesh 中推荐使用的是多控制面方案。
多网络多控制平面
该方案中多个集群在不同网络中,不同集群中的 Pod IP 之间是不能通过路由互通的,只能通过网关进行访问。即使在不同集群中部署相同的服务,对远端集群中服务的访问方式也和本地服务不同,即不能采用同一服务名来访问不同集群中的相同服务,因此无法实现跨集群/地域的负载均衡或容灾。
由于上诉特点,多网络多控制平面的部署方案一般用于需要隔离不同服务的场景,如下图所示,通常会在不同集群中部署不同的服务,跨集群进行服务调用时通过 Ingress Gateway 进行。
Anthos Service Mesh 多集群管理-多网络多控制平面

单网络多控制平面
在该方案中,多个集群处于同一个扁平三层网络之中,各个集群中的服务可以直接相互访问。如下图所示,两个集群中的 Istio 控制面都通过访问对方的 API server 拿到了对方的服务信息。在这种场景中,通常会在不同集群中部署相同的服务,以实现跨地域的负载均衡和容灾。
如图中箭头所示,在正常情况下,每个 region 中的服务只会访问自己 region 中的其他服务,以避免跨 region 调用导致时延较长,影响用户体验。当左边 region 中的 ratings 服务由于故障不能访问时,reviews 服务会通过 Istio 提供的 Locality Load Balancing 能力访问右侧 region 中的 ratings 服务,以实现跨 region 的容灾,避免服务中断。
Anthos Service Mesh 多集群管理-单网络多控制平面

Anthos Service Mesh 多集群部署示例
对于 Istio 来讲,其管理的 Mesh 中的多个集群是否跨云/混合云并不影响集群管理的部署方案,因为本质上都是同一网络/多个网络两种情况下的多集群管理。本示例的两个集群都使用了 GKE 的 Cluster。但只要把网络打通,本示例也适用于跨云/混合云的情况。
本示例的部署如图“单网络多控制面“所示,在同一个 VPC 中的两个 region 中部署了两个 GKE cluster。部署时需要注意几点:
- 需要将 cluster 的网络方案设置为 vpc-native,这样 pod ip 在 vpc 中就是可以路由的,以让两个 cluster 的网络可以互通。
- 需要为两个 cluster 中部署的 Istio 控制面设置对方 api server 的 remote secret,以使 stio 获取对方的 Service 信息。
具体的安装步骤可以参见 Anthos Service Mesh 的帮助文档。
从导出的 Envoy sidecar 配置可以看到,其连接的 xds server 为本地集群中的 istiod。
"cluster_name": "xds-grpc",
"endpoints": [
{
"lb_endpoints": [
{
"endpoint": {
"address": {
"socket_address": {
"address": "istiod.istio-system.svc",
"port_value": 15012
}
}
}
}
]
}
]
Metric,Access log和 tracing 过 Envoy stackdriver http filter 上报到 Google Cloud,以便通过 Anthos Service Mesh 控制台统一查看。
"name": "istio.stackdriver",
"typed_config": {
"@type": "type.googleapis.com/udpa.type.v1.TypedStruct",
"type_url": "type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm",
"value": {
"config": {
"root_id": "stackdriver_outbound",
"vm_config": {
"vm_id": "stackdriver_outbound",
"runtime": "envoy.wasm.runtime.null",
"code": {
"local": {
"inline_string": "envoy.wasm.null.stackdriver"
}
}
},
"configuration": "{\"enable_mesh_edges_reporting\": true, \"disable_server_access_logging\": false, \"meshEdgesReportingDuration\": \"600s\"}\n"
}
}
}
尝试从位于 west1-a Region 集群的 sleep pod 中访问 helloworld 服务,可以看到缺省会访问本集群中的 helloword v1 版本的服务实例,不会跨地域访问。
g********@cloudshell:~ (huabingzhao-anthos)$
export CTX1=gke_huabingzhao-anthos_us-west1-a_anthos-mesh-cluster-1
for i in {1..4}
> do
> kubectl exec --context=${CTX1} -it -n sample -c sleep \
> $(kubectl get pod --context=${CTX1} -n sample -l \
> app=sleep -o jsonpath='{.items[0].metadata.name}') \
> -- curl helloworld.sample:5000/hello
> done
Hello version: v1, instance: helloworld-v1-578dd69f69-c2fmz
Hello version: v1, instance: helloworld-v1-578dd69f69-c2fmz
Hello version: v1, instance: helloworld-v1-578dd69f69-c2fmz
Hello version: v1, instance: helloworld-v1-578dd69f69-c2fmz
将 west1-a 集群中 helloworld deployment 的副本数设置为0,再进行访问,由于本地没有可用实例,会访问到部署在 east1-b region 的 helloworld v2,实现了跨地域的容灾。这里需要注意一点:虽然两个集群的 IP 是可路由的,但 Google cloud 的防火墙缺省并不允许集群之间相互访问,需要先创建相应的防火墙规则,以允许跨集群的网格访问流量。
kubectl edit deployment helloworld-v1 -nsample --context=${CTX1}
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2020-08-14T12:00:32Z"
generation: 2
labels:
version: v1
name: helloworld-v1
namespace: sample
resourceVersion: "54763"
selfLink: /apis/apps/v1/namespaces/sample/deployments/helloworld-v1
uid: d6c79e00-e62d-411a-8986-25513d805eeb
spec:
progressDeadlineSeconds: 600
replicas: 0
revisionHistoryLimit: 10
selector:
matchLabels:
app: helloworld
version: v1
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
......
g********@cloudshell:~ (huabingzhao-anthos)$ for i in {1..4}
> do
> kubectl exec --context=${CTX1} -it -n sample -c sleep \
> $(kubectl get pod --context=${CTX1} -n sample -l \
> app=sleep -o jsonpath='{.items[0].metadata.name}') \
> -- curl helloworld.sample:5000/hello
> done
Hello version: v2, instance: helloworld-v2-776f74c475-jws5r
Hello version: v2, instance: helloworld-v2-776f74c475-jws5r
Hello version: v2, instance: helloworld-v2-776f74c475-jws5r
Hello version: v2, instance: helloworld-v2-776f74c475-jws5r
相互竞争还是优势互补?
从前面的分析可以看出, Google Cloud 推出的 Traffic Director 和 Anthos Service Mesh 这两个服务网格的产品各有侧重点:
- Traffic Director 关注重点为流量管理。依靠 Google Cloud 强大的网络能力提供了跨区域的 Mesh 流量管理,支持本地服务出现问题时将流量导向另一个地域的相同服务,以避免用户业务中断;并且通过统一的服务发现机制实现了 K8s 集群和虚拟机的混合部署。
- Anthos Service Mesh 关注重点为跨云/多云的统一管理。这是出于用户业务部署的实际环境和业务向云迁移的较长过程的实际考虑,但目前未支持虚拟机,并且其对于 Mesh 中全局流量的管理能力不如 Traffic Director 这样强大。
由于目的不同,两者在控制面也采用不同的实现方案。由于 Traffic Director 只需要支持 Google Cloud,处于一个可控的网络环境中,因此采用托管的自定义控制面实现,并对接了 Google Cloud 上的服务发现机制;而 Anthos Service Mesh 考虑到多云/混合云场景下复杂的网络环境和部署限制,采用了开源 Istio 的多控制面方案,在每个集群中都单独安装了一个 Istio,只是接入了 Google Cloud 的遥测数据,以对网格中的服务进行统一监控。
虽然 Traffic Director 和 Anthos Service Mesh 两者都是 Google Cloud 上的 Service Mesh 产品,似乎存在竞争关系,但从两者的功能和定位可以看出,这两个产品其实是互补的,可以结合两者以形成一个比较完善的 Service Mesh 托管解决方案。因此 Google Cloud 会对两个产品持续进行整合。下图为 Traffic Director Road Map 中 Anthos 和 Istio 的整合计划。

参考文档
5 - (2021)服务网格比较: Istio 与 Linkerd
研究使用案例,比较顶级网格选项,并讨论最佳做法。
内容出处
Service Mesh Comparison: Istio vs Linkerd
https://dzone.com/articles/service-mesh-comparison-istio-vs-linkerd
作者 Anjul Sahu 服务网格比较: Istio 与 Linkerd
https://cloudnative.to/blog/service-mesh-comparison-istio-vs-linkerd/
译者 张晓辉 发表于 2021年1月25日
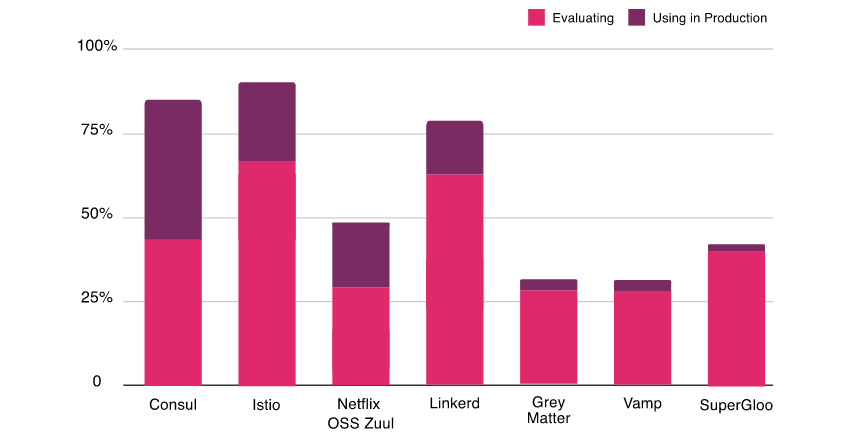
根据 CNCF 的最新年度调查,很明显,很多人对在他们的项目中使用服务网格表现出了极大的兴趣,并且许多人已经在他们的生产中使用它们。将近 69% 的人正在评估 Istio,64% 的人正在研究 Linkerd。Linkerd 是市场上第一个服务网格,但是 Istio 的服务网格更受欢迎。这两个项目都是最前沿的,而且竞争非常激烈,因此选择哪一个是一个艰难的选择。在此博客文章中,我们将了解有关 Istio 和 Linkerd 的架构,其及组件的更多信息,并比较其特性以帮你做出明智的决定。
服务网格简介
在过去的几年中,微服务架构已经成为设计软件应用程序的流行风格。在这种架构中,我们将应用程序分解为可独立部署的服务。这些服务通常是轻量级的、多语言的,并且通常由各种职能团队进行管理。直到这些服务的数量变得庞大且难以管理之前,这种架构风格效果很好。突然之间,它们不再简单了。这在管理各个方面(例如安全性、网络流量控制和可观察性)带来了挑战。服务网格可以帮助应对这些挑战。
术语服务网格用于描述组成此类应用程序的微服务网络及其之间的交互。随着服务数量和复杂性的增加,其扩展和管理变得越来越困难。服务通常提供服务发现、负载均衡、故障恢复、指标和监控。服务网格通常还具有更复杂的操作要求,例如A/B测试、金丝雀发布、限流、访问控制和端到端身份验证。服务网格为负载均衡、服务到服务的身份验证、监控等提供了一种创建服务网络的简单方法,同时对服务代码的更改很少或没有更改。
让我们看一下 Istio 和 Linkerd 的架构。请注意,这两个项目都在快速演进,并且本文基于 Istio 1.6 版本和 Linkerd 2.7 版本。
Istio
Istio 是一个提供了作为服务网格的整套解决方案的开源平台,提供了安全、连接和监控微服务的统一方法。它得到了 IBM、Google 和 Lyft 等行业领军者的支持。Istio 是最流行、最完善的解决方案之一,其高级特性适用于各种规模的企业。它是 Kubernetes 的一等公民,被设计成模块化、平台无关的系统。有关 Istio 的快速演示,请参考我们以前的文章。
架构

Istio架构来源:istio.io
组件
Envoy 是由 Lyft 用 C++ 编写的高性能代理,它可以协调服务网格中所有服务的所有入站和出站流量。它作为 Sidecar 代理与服务一起部署。
Envoy提供以下功能:
- 动态服务发现
- 负载均衡
- TLS 终止
- HTTP/2 和 gRPC 代理
- 断路器
- 健康检查
- 按百分比分配流量实现的分阶段发布
- 故障注入
- 丰富的指标
在较新的 Istio 版本中,Sidecar 代理对 Mixer 的工作承担了额外的责任。在早期版本的 Istio(<1.6)中,使用 Mixer 从网格收集遥测信息。
Pilot 为 Sidecar 代理提供服务发现、流量管理功能和弹性。它将控制流量行为的高级路由规则转换为 Envoy 的特定配置。
Citadel 通过内置的身份和凭证管理实现了强大的服务到服务和最终用户身份验证。它可以在网格中启用授权和零信任安全性。
Galley 是 Istio 配置验证、提取、处理和分发组件。
核心功能
- 流量管理 — 智能流量路由规则、流量控制和服务级别属性(如断路器、超时和重试)的管理。它使我们能够轻松设置 A/B测试、金丝雀发布和并按比例分配流量的分阶段发布。
- 安全性 — 在服务之间提供安全的通信通道,并管理大规模身份验证、授权和加密。
- 可观察性 — 强大的链路跟踪、监控和日志功能提供了深度洞察(deep insights)和可见性。它有助于有效地检测和解决问题。
Istio 还具有一个附加组件基础结构服务,该服务支持对微服务的监控。Istio 与 Prometheus、Grafana、Jaeger 和服务网格仪表盘 Kiali 等应用程序集成。
Linkerd
Linkerd 是 Buoyant 为 Kubernetes 设计的开源超轻量级的服务网格。用 Rust 完全重写以使其超轻量级和高性能,它提供运行时调试、可观察性、可靠性和安全性,而无需在分布式应用中更改代码。
架构
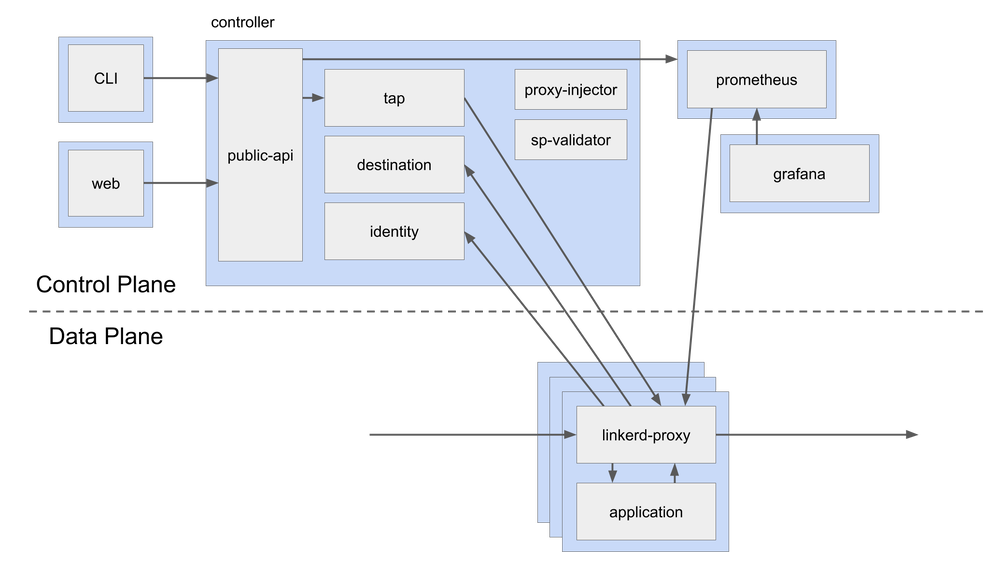
Linkerd 具有三个组件 — UI、数据平面和控制平面。它通过在每个服务实例旁边安装轻量级透明代理来工作。
控制平面
Linkerd 的控制平面是一组提供了服务网格的核心功能的服务。它聚合了遥测数据、提供面向用户的 API,并为数据平面代理提供控制数据。以下是控制平面的组件:
- 控制器 — 它包含一个公共 API 容器,该容器为 CLI 和仪表盘提供 API。
- 目标 — 数据平面中的每个代理都将访问此组件以查找将请求发送到的位置。它有用于每个路由指标、重试和超时的服务描述信息。
- 身份 — 它提供了一个证书颁发机构,该证书颁发机构接受来自代理的 CSR 并返回以正确身份签发的证书。它提供了 mTLS 功能。
- 代理注入器 — 它是一个准入控制器,用于查找注解(
linkerd.io/inject: enabled)并更改 pod 规范以添加initContainer和包含代理本身的 sidecar。 - 服务配置文件验证器 — 这也是一个准入控制器,用于在保存新服务描述之前对其进行验证。
- Tap — 它从 CLI 或仪表盘接收实时监控请求和响应的指令,以在应用程序中提供可观察性。
- Web — 提供 Web 仪表盘。
- Grafana — Linkerd 通过 Grafana 提供开箱即用的仪表盘。
- Prometheus — 通过
/metrics在端口 4191 上代理的断点来收集和存储所有 Linkerd 指标。
数据平面
Linkerd 数据平面由轻量级代理组成,这些轻量级代理作为边车容器与服务容器的每个实例一起部署。在具有特定注解的 Pod 的初始化阶段,将代理注入(请参见上面的代理注入器)。自从 2.x 由 Rust 中完全重写以来,该代理一直非常轻量级和高性能。这些代理拦截与每个 Pod 之间的通信,以提供检测和加密(TLS),而无需更改应用程序代码。
代理功能:
- HTTP、HTTP/2和任意 TCP 协议的透明、零配置代理。
- 自动为 HTTP 和 TCP 流量导出 Prometheus 指标。
- 透明的零配置 WebSocket 代理。
- 自动的、可感知延迟的 7 层负载均衡。
- 非 HTTP 流量的自动的 4 层负载均衡。
- 按需诊断 tap API。
比较
| 特点 | Istio | Linkerd |
|---|---|---|
| 易于安装 | 由于各种配置选项和灵活性,对于团队来说可能不堪重负。 | 因为有内置和开箱即用的配置,适配起来是相对容易的 |
| 平台 | Kubernetes、虚拟机 | Kubernetes |
| 支持的协议 | gRPC、HTTP/2、HTTP/1.x、Websocket 和所有 TCP 流量。 | gRPC、HTTP/2、HTTP/1.x、Websocket 和所有 TCP 流量。 |
| 入口控制器 | Envoy,Istio 网关本身。 | 任何 – Linkerd 本身不提供入口功能。 |
| 多集群网格和扩展支持 | 通过各种配置选项以及在 Kubernetes 集群外部扩展网格的稳定版本支持多集群部署。 | 2.7 版本,多群集部署仍处于试验阶段。根据最新版本 2.8,多群集部署是稳定的。 |
| 服务网格接口(SMI)兼容性 | 通过第三方 CRD。 | 原生的流量拆分和指标,而不用于流量访问控制。 |
| 监控功能 | 功能丰富 | 功能丰富 |
| 追踪支持 | Jaeger、Zipkin | 所有支持 OpenCensus 的后端 |
| 路由功能 | 各种负载均衡算法(轮训、随机最少连接),支持基于百分比的流量拆分,支持基于标头和路径的流量拆分。 | 支持 EWMA(指数加权移动平均)负载均衡算法,通过 SNI 支持基于百分比的流量拆分。 |
| 弹性 | 断路、重试和超时、故障注入、延迟注入。 | 无断路、无延迟注入支持。 |
| 安全 | mTLS支持所有协议、可以使用外部 CA 证书/密钥、支持授权规则。 | 除了 TCP 之外,还支持 mTLS,可以使用外部 CA/密钥,但尚不支持授权规则。 |
| 性能 | 在最新的 1.6 版本中,Istio 的资源占用越来越好并且延迟得到了改善。 | Linkerd 的设计非常轻巧 - 根据第三方基准测试,它比 Istio 快 3-5 倍。 |
| 企业支援 | 不适用于 OSS 版本。如果您将 Google 的 GKE 与 Istio 一起使用,或者将 Red Hat OpenShift 与 Istio 作为服务网格使用,则可能会得到各个供应商的支持。 | 开发了 Linkerd OSS 版本的 Buoyant 提供了完整的企业级工程、支持和培训。 |
结论
服务网格正成为云原生解决方案和微服务架构中必不可少的组成部分。它完成了所有繁重的工作,例如流量管理、弹性和可观察性,让开发人员专注于业务逻辑。Istio 和 Linkerd 都已经成熟,并已被多家企业用于生产。对需求的计划和分析对于选择要使用哪个服务网格至关重要。请在分析阶段投入足够的时间,因为在游戏的后期从一个迁移到另一个很复杂。
选择与服务网格一样复杂和关键的技术时,不仅要考虑技术,还要考虑使用技术的背景。缺少背景,很难说 A 是否比 B 好,因为答案确实是“取决于”。我喜欢 Linkerd 的简单,包括入门和以后管理服务网格。此外,多年来,Linkerd 与来自企业公司的用户一起得到了加强。
一个中可能有一些功能看起来不错,但请确保检查另一个是否计划在不久的将来发布该功能,并基于不仅是理论上的评估,而且还要在概念验证沙箱中对它们进行尝试,做出明智的决定。这种概念验证应集中在易用性、功能匹配以及更重要的是技术的操作方面。引入技术相对容易,最困难的部分是在其生命周期中运行和管理它。
请让我们知道你的想法和意见。