Servicemesh介绍
- 1: Servicemesh的出处
- 2: Servicemesh的定义
- 2.1: (2017)William Morgan的权威定义
- 2.2: (QCon 2017年演讲)Servicemesh由来和定义
- 2.3: (2021)servicemesh.es网站的servicemesh介绍
- 3: Servicemesh的诞生
- 3.1: (2014)Netflix Prana
- 3.2: (2015)唯品会OSP Local Proxy
- 3.3: (2017)2017年QCon上海的演讲
- 3.4: (2015)微服务:使用Smartstack进行服务发现
- 4: Servicemesh的背景
- 4.1: (2018)令人兴奋微服务的2.0技术栈
- 4.2: (2018)后 Kubernetes时代的微服务
- 4.3: (2020)用Istio进行微服务和服务网格的解释
- 4.4: (2021)分布式系统在 Kubernetes 上的进化
- 5: Servicemesh的演进
- 6: Servicemesh的市场竞争
- 6.1: (2017)2017年Servicemesh年度总结
- 6.2: (2021)服务网格除了 Istio,其实你还可以有其它 8 种选择
- 6.3: (2021)服务网格联网:使用案例、最佳实践和顶级服务网格选择比较
- 6.4: (2021)Google Cloud 服务网格: Traffic Director 与 Anthos Service Mesh 的左右互搏
- 6.5: (2021)服务网格比较: Istio 与 Linkerd
- 7: Servicemesh的问题
- 8: Servicemesh的未来
- 9: Servicemesh介绍推荐阅读
- 9.1: (2017)什么是服务网格以及为什么我们需要服务网格?
- 9.2: (2017)Service Mesh:下一代微服务
- 9.3: (2017)Pattern: Service Mesh
- 9.4: (2021)服务网格:每位软件工程师需要了解的世界上最被过度炒作的技术
- 9.5: (2021)分布式系统在 Kubernetes 上的进化
- 9.6: (2021)服务网格终极指南第二版——下一代微服务开发
- 10: Servicemesh资料收集
1 - Servicemesh的出处
1.1 - (2016)servicemesh第一次使用
https://twitter.com/wm/status/1383061764938469377?s=20
一点点服务网格的历史。发现于2016年9月与 @olix0r @mtrifiro 和 @adlleong 一起进行的我们的 @Linkerd 命名的头脑风暴. 在我的记录中第一次出现了 “service mesh"这个词。

1.2 - (QCon 2017年演讲)Servicemesh由来
Service Mesh是新兴的微服务架构,被誉为下一代微服务,是云原生技术栈的代表技术之一。
Service Mesh的由来
2016年1月,离开Twitter的基础设施工程师William Morgan和Oliver Gould,在github上发布了Linkerd 0.0.7版本,他们同时组建了一个创业小公司Buoyant,业界第一个Service Mesh项目就此诞生。
在2016年初,Service Mesh还只是Buoyant公司的内部词汇,而之后,随着Linkerd的开发和推广,Service Mesh这个名词开始逐步走向社区并被广泛接受、喜爱和推崇:
-
2016年9月29日在SF Microservices上,“Service Mesh"这个词汇第一次在公开场合被使用。这标志着"Service Mesh"这个术语,从Buoyant公司正式走向社区。

-
2016年10月,Alex Leong开始在Buoyant公司的官方博客中开始”A Service Mesh for Kubernetes“系列博客的连载。随着"The services must mesh"口号的喊出,Buoyant和Linkerd开始Service Mesh的布道。
-
2017年1月23日,Linkerd加入CNCF,类型为"Service Mesh”。这是Service Mesh重要的历史事件,代表着CNCF社区对Service Mesh理念的认同。
-
2018年7月,CNCF社区正式发布了Cloud Native的定义1.0版本,非常明确的指出云原生代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API,将Service Mesh技术放在了一个前所未有的高度。
至此,从2016到2018,在两年左右的时间内,Service Mesh这个名词实现了从无到有,再到被社区广泛接受乃至炙手可热的过程。
中文名的小插曲
2017年初,随着Linkerd的传入,Service Mesh进入国内技术社区的视野。早期翻译不统一,有人取字面意义翻译为"服务网格",有人觉得和"Service Grid"无法区分所以翻译为"服务啮合层",有些混乱。
个人觉得"服务啮合层"这个词过于拗口,而根据过往IT届的各种惨痛经历我得出的结论是:一个太生僻的名字会毁了一个大有前途的技术。考虑到"服务网格"简单易懂,朗朗上口,符合英文原语"Service Mesh",容易被理解和记忆。最重要的,网格一词生动的体现了这个技术的内涵,如下图所示(摘自Phil Calçado的经典文章Pattern: Service Mesh):

因此,我大力倡导并坚持使用"服务网格",也得到了很多Service Mesh技术爱好者的认可和赞同。随着Service Mesh中国技术社区的组建和发展,“Service Mesh"一词在社区的推广下,基本统一翻译为"服务网格”,包括各种技术媒体。
有关这个话题,可以浏览InfoQ的这个帖子的留言部分:
http://www.infoq.com/cn/news/2017/05/istio
比较有代表性的是,InfoQ这个文章最初发布的时候名字叫做"Istio:用于微服务的服务啮合层",被大量转载,大家google或者百度可以找到各种历史记录。后来社区统一为"服务网格"之后,InfoQ与时俱进的修改了标题(非常有担当的技术媒体,赞一个!)。
2 - Servicemesh的定义
2.1 - (2017)William Morgan的权威定义
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware. (But there are variations to this idea, as we’ll see.)
服务网是一个专用的基础设施层,用于处理服务间通信。现代云原生应用程序有着复杂的服务拓扑,服务网格负责在这些拓扑中实现请求的可靠传递。在实践中,服务网格通常实现为一组轻量级网络代理,它们与应用程序代码部署在一起,而对应用程序透明。(但这个想法也有变化,我们会看到的)
来源
What’s a service mesh? And why do I need one?
https://buoyant.io/what-is-a-service-mesh
https://linkerd.io/2017/04/25/whats-a-service-mesh-and-why-do-i-need-one/
https://www.infoq.cn/news/2017/11/WHAT-SERVICE-MESH-WHY-NEED/ 中文翻译 by 薛命灯
William Morgan
2.2 - (QCon 2017年演讲)Servicemesh由来和定义
Service Mesh的定义
Service Mesh的定义最早是由出品Linkerd的Buoyant公司CEO William在他的经典博客文章 What’s a service mesh? And why do I need one? 给出来的。Linkerd是业界第一个Service Mesh项目,而Buoyant则创造了Service Mesh这个词汇的。作为Service Mesh全球第一个布道师,William给出的这个定义是非常官方和权威的:
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
服务网格是一个基础设施层,用于处理服务间通讯。现代云原生应用有着复杂的服务拓扑,服务网格负责在这些拓扑中实现请求的可靠传递。在实践中,服务网格通常实现为一组轻量级网络代理,它们与应用程序部署在一起,而对应用程序透明。
我们来深入ServiceMesh具体的部署模型和工作方式,以便更好的理解Service Mesh的含义。
Service Mesh详解
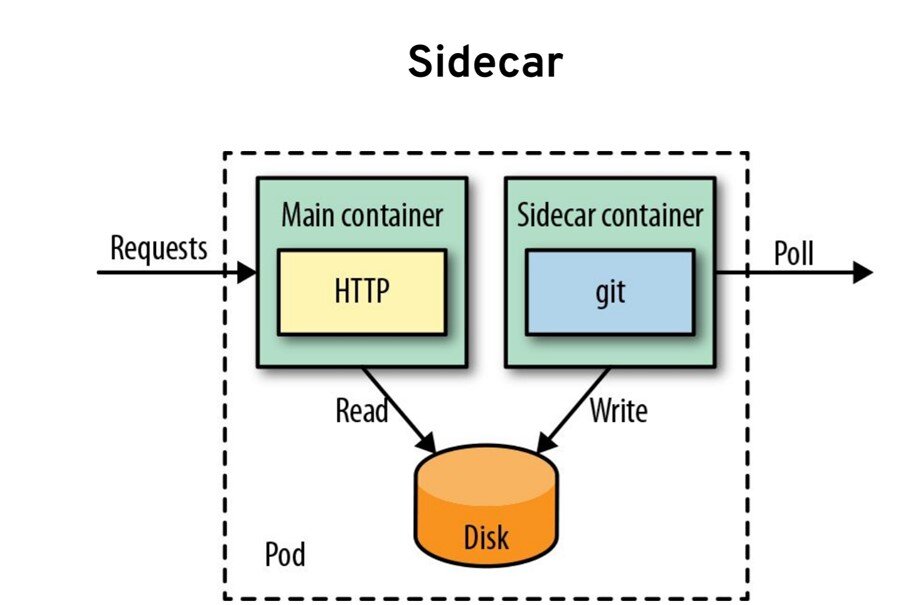
单个服务调用

这是单个服务调用下的Service Mesh部署模型,当发起一个请求时,作为请求发起者的客户端应用实例,会首先用简单方式将请求发送到本地的Service Mesh代理实例。注意此时应用实例和代理是两个独立的进程,他们之间是远程调用,而不是代码层面的方法调用。
然后,Service Mesh的代理会完成完整的服务间通讯的调用流程,如服务发现、负载均衡等基本功能,熔断、限流、重试等容错功能,各种高级路由功,安全方面的认证、授权、鉴权和加密等,最后将请求发送给目标服务。最终表现为Sidecar模式,实现和传统类库类似甚至更完备的功能。
Sidecar这个词中文翻译为"边车",或者"车斗"。Sidecar 模式则早在Service Mesh出现前就在软件开发领域使用,它的灵感来源于实物,通过在原有的两轮摩托的一侧增加一个边车来实现对现有功能的扩展:

Service Mesh通过在请求调用的路径中增加Sidecar,将原本由客户端(通常通过类库)完成的复杂功能,下沉到Sidecar中,实现对客户端的简化和服务间通讯控制权的转移。
多个服务调用

当多个服务依次调用时,Service Mesh表现为一个单独的通讯层。在服务实例之下,Service Mesh接管整个网络,负责所有服务间的请求转发,从而实现让服务只需简单发送请求和处理请求的业务处理,不再负责传递请求的具体逻辑。中间服务间通讯的环节被剥离出来,呈现出一个抽象层,被称为服务间通讯专用基础设施层。
大量服务调用

当系统中存在大量服务时,服务间的调用关系,就会表现为网状。如图所示,左边绿色的是应用程序,右边蓝色的是Service Mesh的Sidecar,蓝色之间的线条是表示服务之间的调用。可以看到Sidecar之间的服务调用关系形成一个网络,这也就是Service Mesh/服务网格名字的由来。
此时Service Mesh体现出来的依然是一个通讯层,只是这个通讯层内部更加复杂,不是简单的顺序调用关系,而是彼此相互调用,形成网状。
Service Mesh定义回顾
回顾Servicemesh的定义:
服务网格是一个基础设施层,用于处理服务间通讯。现代云原生应用有着复杂的服务拓扑,服务网格负责在这些拓扑中实现请求的可靠传递。在实践中,服务网格通常实现为一组轻量级网络代理,它们与应用程序部署在一起,而对应用程序透明。
再来详细理解什么是Service Mesh:
- 抽象:Service Mesh是一个抽象层,负责完成服务间通讯。但是和传统类库方式不同的是,Service Mesh将这些功能从应用中剥离出来,形成了一个单独的通讯层,并将其下沉到基础设施。
- 功能:Service Mesh负责实现请求的可靠传递,从功能上说,和传统的类库方式并无不同,原有的功能都继续提供,甚至可以做的更多更好。
- 部署:Service Mesh在部署上体现为轻量级网络代理,以Sidecar的模式和应用程序一对一部署,两者之间的通讯是远程调用,但是走的是localhost。
- 透明:Service Mesh是应用程序是透明的,其功能实现完全独立于应用程序。应用程序无需关注Service Mesh的具体实现细节,甚至对Service Mesh的存在也可以无感知。带来的一个巨大优势是Service Mesh可以独立的部署升级,扩展功能修复缺陷而不必改动应用程序。

需要注意的是,上面的图中,如果把左边的应用程序去掉,只呈现出来Sidecar和它们之间的调用关系,这个时候Service Mesh的概念就会特别清晰:Sidecar和调用关系形成完整的网络,代表服务间复杂的调用关系,承载着系统内的所有应用。
这是Service Mesh定义中非常重要的一点,和传统的Sidecar模式不同的地方:Service Mesh不再将代理视为单独的组件,而是强调由这些代理连接而形成的网络。Service Mesh非常强调服务间通讯网络的整体,而不是简单的以个体的方式单独看待每个代理。
至此,我们描述了Service Mesh的定义并做了详细的解释,希望可以帮助大家了解到什么是Service Mesh。在下一章中,我们将给大家详细介绍Service Mesh技术的由来和发展历程。
2.3 - (2021)servicemesh.es网站的servicemesh介绍
servicemesh.es 网站的介绍
A service mesh is a dedicated infrastructure layer that adds features to a network between services. It allows to control traffic and gain insights throughout the system. Observability, traffic shifting (for canary releasing), resiliency features (such as circuit breaking and retry/timeout) and automatic mutual TLS can be configured once and enforced in a decentralized fashion. In contrast to libraries, which are used for similar functionality, a service mesh does not require code changes. Instead, it adds a layer of additional containers that implement the features reliably and agnostic to technology or programming language.
服务网格是一个专用的基础设施层,为服务间的网络增加功能。它允许控制流量并获得整个系统的洞察力。可观察性、流量转移(用于金丝雀发布)、弹性功能(如熔断和重试/超时)和自动双向TLS可以一次配置并以非中央化的方式执行。与用于类似功能的类库相比,服务网格不需要修改代码。相反,它增加了一层额外的容器,可靠地实现这些功能,并且和技术或编程语言无关。
The value of a service mesh grows with the number of services an application consists of. Logically, microservices architectures are the most common use cases for a service mesh. However, the specific interaction might be more relevant in regards to how a service mesh can improve the control, reliability, security, and observability of the services. Even a monolith could benefit from a service mesh and some concrete microservice applications might not.
服务网格的价值随着应用程序所包含的服务数量而增长。从逻辑上讲,微服务架构是服务网格最常见的用例。然而,对于服务网格如何改善服务的控制、可靠性、安全性和可观察性,具体的交互可能更有意义。即使是单体也可以从服务网格中受益,而一些具体的微服务应用可能不会。
3 - Servicemesh的诞生
3.1 - (2014)Netflix Prana
内容出处
Prana: A Sidecar Application for Netflix OSS-based Services
https://www.infoq.com/news/2014/12/netflix-prana/
2014年
Netflix已经发布了Prana,这是一个开源的 “sidecar” 应用程序,该公司开发的目的是让异构的微服务应用程序使用基于JVM的NetflixOSS平台支持库。
Prana被部署到每个服务实例上,在概念上与 “父” 服务相连,就像摩托车副驾与摩托车相连一样。它作为第二个进程与服务一起运行,并提供通过HTTP API暴露的平台基础设施功能,如服务发现、动态配置和弹性的服务间通信。
Netflix的博客说,在Netflix内外,特别是在运营和管理一个严重基于微服务的生态系统时,使用 Sidecar 应用已经得到了普及。像Prana这样的边车应用可以为那些在实施和部署技术方面日益异质化的服务提供一个同质化的平台基础设施接口。
通过HTTP与Prana进行跨进程通信,使用其他语言(如Python和Node.js)编写的应用程序或Memcached、Spark和Hadoop等服务能够利用Netflix OSS库提供的功能,而无需为目标语言或平台重新编写库。
Prana为附属于 sidecar 应用程序的父服务提供以下功能:
- 通过Eureka服务进行服务注册和发现。这使得父服务可以被其他基于 Netflix OSS的组件 “发现”,并且还提供了一个健康检查的HTTP端点。
- 动态配置,由Archaius提供。这允许父服务接收动态属性的更新。
- 弹性的服务间通信。Prana sidecar使用 Hystrix/Ribbon 代理对其他微服务的请求,这使得父服务可以利用这些库提供的断路器、批量标题和回退功能来调用其他服务。
- 通过一个嵌入式管理控制台,对服务实例和相应的环境进行运行时的洞察和诊断。
Prana还被设计成允许添加额外的自定义插件以实现可扩展性,尽管这一功能的实现目前在项目的Github页面上被列为一个开放问题。核心的Prana应用是建立在Netflix的微服务模板Karyon和Netflix的异步事件驱动网络应用框架RxNetty的反应式扩展(Rx)适配器上。
Prana 的架构图,来自 Netflix 博客:

在Netflix之外使用sidecar应用程序,也被称为 “大使” 应用程序,包括Andrew Spyker的基于Acme Air Netflix OSS的演示程序,用于动态配置,Docker用于跨容器链接,以及AirBnB的SmartStack应用套件用于服务发现。
Prana sidecar应用可以通过遵循该项目Github “入门 “页面中的说明集成到服务中。
3.2 - (2015)唯品会OSP Local Proxy
唯品会Service Mesh的实践分享
郑德惠 2019.1.6
唯品会微服务架构演进之路
https://www.slidestalk.com/u9632/The_Evolution_Path_of_Microservice_Architecture
杨钦民 (时间未知)
3.3 - (2017)2017年QCon上海的演讲
让我们详细追溯一下Service Mesh技术的起源,发展和一步一步的演进历程。
需要注意的是,虽然Service Mesh这个词汇直到2016年9才出现,但是和Service Mesh一脉相承的技术很早就出现了,经过了长期的发展和演变,才形成了今天的Service Mesh,并且这个演进的过程目前还在继续。
远古时代的案例

远在微服务出现之前,在计算机的"远古时代",在第一代网络计算机系统中,最初的一代开发人员需要在应用代码里处理网络通讯的细节问题,比如说数据包顺序、流量控制等等,导致网络通讯逻辑和业务逻辑混杂在一起。为了解决这个问题,出现了TCP/IP技术,解决了流量控制问题,并将这些功能做成通用能力。从右边的图上可以看到,实际功能没发生变化:所有的功能都在,相应的代码也在。但是,最重要的事情,流程控制,已经从应用程序里面剥离出来。抽出来的这些功能被进一步标准化和通用化,最终统一成操作系统网络层的一部分,这就是TCP/IP协议栈。
这个改动大幅降低了应用程序的复杂度,将业务逻辑和底层网络通讯细节解耦,应用程序的复杂度大为降低,应用程序的开发人员得以解脱并将精力集中在应用程序的业务逻辑实现上。
这个故事非常遥远,发生在大概五十年前。
微服务时代的现状

当时间流转,进入微服务时代后,我们也面临着类似的一些问题:比如在实现微服务的时候要处理一系列的比较基础和通用的事项,如服务发现,在得到服务器实例列表之后再做负载均衡,为了保护服务器要熔断/重试等等。
这些功能所有的微服务都需要,那怎么办呢?如果将这些功能直接在应用程序里面实现,那么又会和刚才TCP/IP出现前一样,应用程序里面又加上了大量的非业务相关的代码。很自然的,为了简化开发避免代码重复,我们选择使用类库,如经典的Netflix OSS套件。这样开发人员的重复编码问题就解决了:只需要写少量代码,就可以借助类库实现这些功能。
因为这个原因,最近这些年大家看到Java社区Spring Cloud的普及程度非常快,几乎成为了微服务的代名词。但这一切都完美了吗?
侵入式框架的痛点
以Spring Cloud/Dubbo为代表的传统微服务框架,是以类库的形式存在,通过重用类库来实现功能和避免代码重复。但在以运行时操作系统进程的角度来看,这些类库还是渗透进了打包部署之后的业务应用程序,和业务应用程序运行在同一进程内。所谓"侵入式框架"的称谓由此而来。
而建立在类库基础上的"侵入式框架",会面临与生俱来的诸多痛点。
痛点1:门槛高

由于追求特性丰富,侵入式框架必然功能繁多,需要学习掌握的内容也比较多,因此入门的门槛会比较高。
从实践上看,简单了解和运行helloworld,是比较简单的。但是如果要到可以熟练掌握,并且能够在真实落地时解决遇到的各种问题,则会需要很长的时间。
而这些知识是需要团队中的每个开发人员都掌握的,对于业务开发团队来说,面临的挑战要更大一些:
- 业务开发团队的强项往往不是技术,而是对业务的理解,对整个业务体系的熟悉程度
- 业务应用的核心价值在于业务实现,微服务是手段而不是目标,在学习和掌握框架上投入太多精力,在业务逻辑的实现上的投入必然受影响。
- 业务团队往往承受极大的业务压力,时间人力永远不足
痛点2:功能不全

和Service Mesh,尤其是新贵Istio相比,传统侵入式框架如Spring Cloud、Dubbo所能提供的功能是很有限的,尤其不像Isito这样形成一个非常完备的生态体系。典型如Content Based Routing和Version Based Routing,Istio借助这两个特性可以实现非常强大而有弹性的服务治理功能,其能力远远超过Spring Cloud等。
当然,也可以选择在Spring Cloud的基础上进行各种补充、扩展、加强,实践中也的确是大家都在各自做定制化,但是如此一来需要投入的时间和精力就会非常可观。
痛点3:跨语言

微服务在面世时,承诺了一个很重要的特性:微服务可以采用最适合的语言来编写。理论上说,不同的团队,不同的微服务,可以根据实际情况选择团队最擅长,或者最适合当前应用的编程语言。
但是,在实践中,这个承诺往往受到极大挑战而沦为空话:微服务的确理论上可以使用不同的语言,但是实际开发时,当需要选择通过框架或者类库来实现代码重用时,就会发现有个绕不开的问题——框架和类库是语言强相关的!
这个问题非常尖锐,为了解决它,通常有两个思路:
- 统一编程语言,整个系统就只使用一种编程语言,也就只需为这一个语言提供框架和类库
- 为要使用的每种编程语言都提供一套解决方案,也就是框架和类库要为每个语言同样开发一份
前者相当于放弃了微服务的跨语言特性,并且面临强行用一种编程语言完成所有不同类型工作的境地,同样会有很多麻烦。后者理论上可行,但是实践中会面临非常大的开发工作量,后期维护代价高昂,还有不同编程语言不同版本之间的兼容性问题,代价极高,往往无法长期坚持。
痛点4:升级困难

即使解决了多语言支持的问题,无论是统一为一种编程语言,还是开发多种编程语言版本,依然还会继续遇到下面这个问题:版本升级。
任何框架不可能一开始就完美无缺,所有功能都齐备,没有任何BUG,以至于分发出去之后就再也不需要改动和升级。这种理想状态是不存在的。必然是1.0、1.2、2.0慢慢版本升级,功能逐渐增加,BUG逐渐被修复。在这期间,一个接一个新版本陆续发布并分发给使用者。但是,当框架分发给使用者之后,使用者会不会总是保持升级到最新发布的版本?
实际上做不到的。任何一家正规的公司,业务应用上线必然是有一个完备的流程,当应用程序发生变更需要重新上线时,必然要走测试和上线的标准流程。类库升级,即使是在完全兼容不需要修改任何业务代码的前提下,也是需要业务应用重新打包发布的,因为"侵入式框架"是需要将框架打包进去业务应用的!
因为这个原因,框架的使用者,在没有特别需求或者遭遇严重bug时,是没有升级框架版本的动机和热情的。导致实际运行时,系统中运行的框架版本,包括服务器端版本和客户端版本,是不一致的,而且随着时间的推移会越来越呈现出版本碎片化的趋势。此时,不同版本之间的兼容性问题就会变得非常的复杂,框架的开发人员需要非常小心的维护兼容性,一旦兼容性出现问题,就会严重打击使用者升级的欲望,造成更大的碎片化,恶性循环。
而维护版本兼容性的复杂度会让任何对框架进行改进的努力都变得小心翼翼甚至举步维艰。当服务端数以百计起,客户端数以千计起时,如果每个应用的版本都有可能不同。再考虑编程语言造成的多个实现,这种情况下的兼容性测试代价过于高昂几乎无法承受!导致开发人员倾向于放弃可能造成兼容性问题的改进,从而让存在的问题长期积累,以至于积重难返。
解决问题的思路
问题是客观存在的,总是需要面对。在解决问题前,先反省问题的来源,想想我们的出发点和目标。

-
问题的根源在哪里?
面临的这些问题,这么多艰巨的挑战,和业务应用,或者说服务本身,有直接关系吗?
答案是:没有。这些问题都属于服务间通讯的范围,和应用本身的实现逻辑无关。
-
我们的目标是什么?
所有的努力,都是为了保证将客户端发出的业务请求,发送到正确的目的地。而"正确"一词,在不同的特性下有不同的语义,如服务发现,负载均衡,灰度,版本控制,蓝绿部署,按照请求内容执行不同的路由策略。服务间通讯的目标,是让请求在满足这些特性要求的前提下,去往请求应该去的目的地服务,而与请求的业务语义无关,和请求的业务处理无关。
-
服务间通讯的本质是什么?
在整个服务间通讯的处理流程中,无论功能有多复杂,请求本身的业务语义和业务内容(非业务内容可能会有变化如传递特殊的header或者对内容加解密)是不发生变化的。对于服务间通讯,实现的是请求的可靠传递,内容是不变的。
-
有什么内容是普适的?
前面遇到的这些问题具有高度的普适性:适用于所有的语言、框架、组织,这些问题对于任何一个微服务都是同样存在的。
回顾前面举出的发生在五十年前的TCP/IP的案例,是否发现,似曾相识?
- TCP/IP解决了什么问题?网络通讯逻辑的代码和业务逻辑代码混杂在一起。
- TCP/IP又是如何解决这些问题的?网络通讯逻辑的代码从业务应用中剥离出来,标准化后下沉到底层。
因此,借鉴当年TCP/IP的思路,对于服务间通讯,在传统的侵入式框架外,出现了另外一种思路:既然我们可以把网络通讯的技术栈剥离并下沉为TCP,我们是否也可以用类似的方式来处理微服务中服务间通讯的技术栈?
Proxy模式的探索

早在微服务出现之前,为了解决客户端和服务器端直接耦合的问题,有一部分先驱者尝试过使用Proxy的方案,来隔离客户端和服务器端。典型如Nginx,HAProxy,Apache等HTTP反向代理。这些Proxy和微服务没有直接联系,但是提供了一个基本思路:在服务器端和客户端之间插入了一个中间层来完成请求转发的功能,避免两者直接通讯。所有流量都经由Proxy转发,而Proxy需要为此实现基本功能如负载均衡。
当然这些Proxy的功能非常简陋,比如服务发现甚至是通过配置文件来实现。功能不够,但是思路和想法很有参考意义:客户端和服务器端应该隔离,部分功能下沉到中间层来实现请求转发。Proxy模式的探索为日后Service Mesh的出现奠定了基础。
Sidecar的出现

为了解决前面列举的侵入式框架遇到的痛点,开始有公司开始尝试Proxy模式。受限于Proxy的功能不足,在参考Proxy模式的基础上,陆陆续续出现了Sidecar模式的一些产品,如Netflix的Prana。
Sidecar模式借鉴了Proxy模式的思路,Sidecar扮演的角色和Proxy很类似,但是在功能实现上就齐全很多。基本思路是对齐原来侵入式框架在客户端实现的各种功能,实现上通常是通过增加一个Proxy实现请求转发,然后直接重用原有的客户端类库。
Sidecar模式和Proxy模式的差异在于功能是否齐全:
- Proxy只具备基本的简单功能
- Sidecar对齐侵入式框架的功能
这种思路下发展出来的Sidecar通常都是有局限性的,表现在为特定的基础设施而设计,通常是和开发Sidecar的公司当时的基础设施和框架直接绑定,在原有体系上搭建出来,有特殊的背景和需求。带来的问题就是这些Sidecar会有很多由原有体系带来的限制,导致无法通用,只能工作在原有体系中,无法对外推广。
第一代Service Mesh

2016年1月,离开Twitter的基础设施工程师William Morgan和Oliver Gould,在github上发布了Linkerd 0.0.7版本,业界第一个Service Mesh项目就此诞生。Linkerd基于Twitter的Finagle开源项目,大量重用了Finagle的类库,但是实现了通用性,成为了业界第一个Service Mesh项目。而Envoy是第二个Service Mesh项目,两者的开发时间差不多,在2017年都相继成为CNCF项目。
Service Mesh和Sidecar的差异在于是否通用:
- Sidecar为特定的基础设施而设计,只能运行在原有环境中
- Service Mesh在Sidecar的基础上解决了通用性问题,可以不受限于原有环境
另外还有一点,Sidecar通常是可选的,容许直连。通常是编写框架的编程语言的客户端维持原有的客户端直连方式,其他编程语言不开发客户端而选择走Sidecar转发的方式,当然也可以选择都走Sidecar。但是,在Service Mesh中,由于要求完全掌控所有流量,所以要求所有请求都必须通过Service Mesh转发,不提供直连方式。
第二代Service Mesh

在2017年之前,Service Mesh的发展和演进可谓按部就班不紧不慢。然后在2017年,突然加速:
- 2017年1月,Linkerd加入CNCF;
- 2017年4月,Linkerd发布1.0版本;
- 同日William Morgan意气风发的发布博文”What’s a service mesh? And why do I need one?“,正式给Service Mesh做了一个权威定义(我们前面看到的),Linkerd。
- 一个月后,2017年5月,Google/IBM/Lyft联手发布Istio 0.1版本。
- 2017年9月,Envoy加入CNCF
在第一代Service Mesh产品如Linkerd、Envoy刚刚发展成熟,正要开始逐渐推广时,以Istio为代表的第二代Service Mesh产品就突然登场,直接改变市场格局。
第二代Service Mesh和第一代Service Mesh的差异在于是否有控制平面:
- 第一代Service Mesh只有数据平面(即Sidecar),所有功能都在Sidecar中实现
- 第二代Service Mesh增加了控制平面,带来了远超第一代的控制力,功能也更加丰富

Istio最大的创新是它为Service Mesh带来了前所未有的控制力:
- 以Sidecar方式部署的Service Mesh控制了服务间所有的流量
- Istio增加了控制面板来控制系统中所有的Sidecar
- 这样Istio就能够控制所有的流量,也就是控制系统中的所有请求的发送
Istio出现之后,Linkerd陷入困境,Envoy则作为Istio的数据平面和Istio一起发展。随后Buoyant公司推出了全新的Conduit应对Istio的强力竞争,我们将在下一章中详细讲述Service Mesh的开源产品和市场竞争。
总结

Service Mesh的演进过程,就是这样一步一步过来的:
- Proxy模式进行探索,隔离客户端和服务器端,部分功能下沉到中间层;但是功能有限
- Sidecar模式弥补Proxy模式功能不足的缺陷,功能对齐传统类库;但是有很大的局限性,无法通用
- 第一代Service Mesh解决Sidecar模式的通用性问题,可以不受限于原有环境;但是控制力不够强大
- 第二代Service Mesh通过增加控制平面来加强控制,并带来更强大的功能
目前第二代的Service Mesh还继续完善中,即将成熟,敬请关注。
3.4 - (2015)微服务:使用Smartstack进行服务发现
内容出处
Microservices: Service Discovery with Smartstack and Docker
https://engineering.poppulo.com/microservices-service-discovery-with-smartstack-and-docker/
2015年8月
在Poppulo,我们在Docker容器中部署我们的微服务。我们的构建产生了Docker镜像,用于在Kubernetes集群上启动容器。Kubernetes使我们能够轻松地管理部署、扩展、滚动更新,并通过复制确保服务的高可用性。
这些服务的外部可用性不应受到它们所组成的底层docker容器的短暂性质的影响。它们应该在单个容器的更新和宕机中幸存下来。在这种情况下,我们要确保请求不再被路由到不可用的容器上,而是由新的容器开始为请求服务。服务发现使这成为可能。
什么是服务发现?
一个基于微服务的系统是由许多负责非常具体任务的小服务组成的。显然,这些服务必须相互通信,这可能不是件容易的事,因为服务实例的寿命很短(更新、故障转移、扩展……)。
服务发现旨在考虑到这些问题,允许服务动态地发现其他服务并与之通信。
保持发现与服务逻辑的解耦
我们从一开始就决定,我们不想在我们的微服务中直接实现服务发现。由于我们的目标是具有单一责任的服务,因此在我们的代码中撒上通用的服务发现逻辑是没有意义的。同样,我们也不希望每次都为我们使用的不同技术编写这种逻辑。
我们的选择:Smartstack
当我们面临服务发现的问题时,我们探索了一些不同的选择,如Smartstack、SkyDNS/Skydock或Kubernetes服务的内置发现功能。我们选择了Smartstack,因为我们非常喜欢它的简单性,而且在我们的技术高峰期,它已经被证明是非常稳定和可靠的。此外,Smartstack所需要的唯一基础设施元素(Zookeeper)已经在我们的堆栈中到位,所以没有额外的设置成本。
Smartstack是一个由Airbnb开发和开源的服务发现框架。它是一个简单而优雅的解决方案,基于两个名为Nerve和Synapse的服务。它依靠Zookeeper来存储发现数据,并依靠HAProxy来进行路由。

Nerve负责注册/取消注册一个微服务;基于健康状态(通常是检查/健康端点)。Nerve通过创建一个包含服务名称和可以访问其API的znode,将微服务发布到Zookeeper。
Synapse是负责查找Microservice实例的服务。使用Zookeeper观察,Synapse会在发生变化时被自动通知,并将更新本地HAProxy配置,以将流量路由(和负载平衡)到所发现的实例。
使用Smartstack与Docker容器
为了在我们的容器中实施这个解决方案,我们建立了包含Nerve和Synapse的基础Docker镜像。然后,我们的服务被构建在这些镜像之上,并从服务发现中受益。
……
总结
当我们开始微服务的旅程时,服务发现对我们来说是一个全新的领域。Smartstack实际上已经使服务发现成为微服务架构难题中最容易解决的部分之一。通过将Synapse和Nerve集成到我们的微服务基础Docker镜像中,我们已经从我们的服务核心中拿走了发现的责任,同时允许它们通过简单的配置轻松地发现和被其他服务所发现。
相关的其他资料
4 - Servicemesh的背景
4.1 - (2018)令人兴奋微服务的2.0技术栈
内容出处
Excited about a ‘2.0’ tech stack for microservices
https://blog.christianposta.com/microservices/microservices-2-0/
作者 Christian Posta 发表于 2017年
4.2 - (2018)后 Kubernetes时代的微服务
内容出处
作者 Bigin Ibryam
后 Kubernetes时代的微服务
在Kubernetes诞生的前几年微服务还是分布式系统最流行的架构风格。但Kubernetes和云原生运动已经改变了应用程序设计和开发的方方面面。在本文中,我要质疑微服务的一些理念,指明它们在后Kubernetes时代不会再像以前那样强大。
https://cloudnative.to/blog/microservices-post-kubernetes/
译者 殷龙飞 发表于 2018年9月7日
关键要点
- 微服务架构仍然是分布式系统最流行的架构风格。 但 Kubernetes 和云原生运动已经在很大程度上重新定义了应用程序的设计和开发。
- 在云原生平台上,服务的可观察性是不够的。更基本的先决条件是通过实施健康检查,对信号做出反应,声明资源消耗等,使微服务自动化。
- 在后 Kubernetes 时代,服务网格技术将完全取代使用库来实现操作网络问题(例如 Hystrix 断路器)。
- 微服务现在必须通过从多个维度实现幂等性来设计用于“恢复”。
- 现代开发人员必须精通编程语言以实现业务功能,并且同样精通云原生技术以满足非功能性基础架构级别要求。
微服务炒作开始于一堆关于组织结构、团队规模、服务规模、重写和抛出服务而不是修复、避免单元测试等的极端想法。根据我的经验,大多数这些想法被证明是错误的,不实用的或者至少不通用。 如今,大多数剩余的原则和实践都是如此通用和松散地定义,以至于它们可能在未来许多年内都会成立,而在实践中却没有多大意义。
在Kubernetes诞生的前几年微服务还是分布式系统最流行的架构风格。但Kubernetes和云原生运动已经改变了应用程序设计和开发的方方面面。在本文中,我要质疑微服务的一些理念,指明它们在后Kubernetes时代不会再像以前那样强大。
不仅可观察,而且还有自动化服务
可观察性从一开始就是微服务的基本原则。 虽然对于一般的分布式系统来说它是正确的,但今天(特别是在 Kubernetes 上),它的很大一部分是平台级别的开箱即用(例如进程运行状况检查、CPU 和内存消耗)。最低要求是应用程序以 JSON 格式登录控制台。 从那时起,平台可以跟踪资源消耗、请求跟踪、收集所有类型的指标、错误率等,而无需太多的服务级别开发工作。
在云原生平台上,可观察性是不够的。更基本的先决条件是通过实施健康检查,对信号做出反应,声明资源消耗等使微服务自动化 。可以将几乎任何应用程序放入容器中运行。但是要创建一个容器化的应用程序,可以通过云原生平台自动化和协调编排,需要遵循一定的规则。遵循这些 原则和模式 ,将确保生成的容器在大多数容器编排引擎中表现得像一个优秀的云原生公民,允许以自动方式对它们进行调度、扩展和监控。
我们希望平台不必观察服务中发生的情况,而是希望平台检测异常情况并按照声明进行协调。无论是通过停止将流量导向服务实例、重启、向上和向下扩展,还是将服务迁移到另一个健康主机,重试失败的请求或其他,这都无关紧要。如果服务是自动化的,则所有纠正措施都会自动发生,我们只需要描述所需的状态,而不是观察和反应。服务应该是可观察的,但也可以在没有人为干预的情况下通过平台自动进行整改。
智能平台和智能服务,但有正确的责任
在从 SOA 转向微服务世界的过程中, “智能端点和哑管”的概念是服务交互的另一个根本转变。在微服务领域,服务不依赖于集中式智能路由层的存在,而是依赖于拥有某些平台级功能的智能端点。这是通过在每个微服务中嵌入传统 ESB 的一些功能并转换到没有业务逻辑元素的轻量级协议来实现的。
虽然这仍然是在不可靠的网络层(使用 Hystrix 等库 ) 实现服务交互的流行方式 ,但现在,在后 Kubernetes 时代,它已经完全被服务网格技术所取代 。有趣的是,服务网格甚至比传统的 ESB 更智能。网格可以执行动态路由、服务发现、基于延迟的负载平衡、响应类型、指标和分布式跟踪、重试、超时,你能想到的这里都有。
与 ESB 的不同之处在于,与服务网格不同的是,只有一个集中路由层,每个微服务通常都有自己的路由器—— 一个带有附加中央管理层的代理逻辑的 sidecar 容器。 更重要的是,管道(平台和服务网格)没有任何业务逻辑;它们完全专注于基础架构方面,使服务专注于业务逻辑。 如图所示,这代表了 ESB 和微服务学习的演变,以适应云环境的动态和不可靠特性。

SOA vs MSA 与 CNA
查看服务的其他方面,我们注意到云原生不仅影响端点和服务交互。Kubernetes 平台(包含所有其他技术)还负责资源管理、调度、部署、配置管理、扩展、服务交互等。而不是再次将其称为“智能代理和哑管”,我认为它更好地描述作为一个具有正确职责的智能平台和智能服务。这不仅仅是关于端点;它是一个完整的平台,可以自动化业务功能服务的所有基础架构方面。
不要面向失败而设计,要面向恢复设计
在基础架构和网络本身不可靠的云原生环境中运行的微服务必须针对故障进行设计。 这毫无疑问。 但是平台检测到并处理了越来越多的故障,并且从微服务中捕获故障的量较少。相反,考虑通过从多个维度实现幂等性来设计您的恢复服务。
容器技术、容器编排器和服务网络可以检测并从许多故障中恢复:无限循环——CPU 分配、内存泄漏和 OOM——运行状况检查、磁盘占用——配额、fork 炸弹——进程限制、批量处理和进程隔离——内存限制、延迟和基于响应的服务发现、重试、超时、自动扩展等等。更不用说,过渡到无服务器模型,服务只需要在几毫秒内处理一个请求,而垃圾收集、线程池、资源泄漏也越来越不需要关心。
通过平台处理所有这些以及更多内容,将您的服务视为一个密封的黑盒子,它将多次启动和停止,使服务能够重新启动。您的服务将按比例放大和缩小倍数,通过使其无状态,使其可以安全地进行扩展。假设许多传入请求最终会超时,使端点具有幂等性。假设许多传出请求将暂时失败,平台将为您重试它们,确保您使用幂等服务。
为了适合云原生环境中的自动化,服务必须是:
- 幂等重启(服务可以被杀死并多次启动)。
- 幂等扩展/缩小(服务可以自动扩展到多个实例)。
- 幂等服务生产者(其他服务可能会重试调用)。
- 幂等服务使用者(服务或网状网可以重试传出调用)。
如果您执行上述操作一次或多次时服务的行为始终相同,那么平台将能够在没有人为干预的情况下从故障中恢复您的服务。
最后,请记住,平台提供的所有恢复只是本地优化。正如 Christian Posta 所说的那样 ,分布式系统中的应用程序安全性和正确性仍然是应用程序的责任。 整个业务流程范围的思维模式(可能跨越多个服务)对于设计整体稳定的系统是必要的。
混合开发职责
越来越多的微服务原则被 Kubernetes 及其补充项目实施和提供。因此,开发人员必须精通编程语言以实现业务功能,并且同样精通云原生技术以满足非功能性基础架构级别要求,同时完全实现功能。
业务需求和基础架构(操作或跨功能需求或系统质量属性)之间的界限总是模糊不清,并且不可能采取一个方面并期望其他人做另一个方面。 例如,如果在服务网格层中实现重试逻辑,则必须使服务中的业务逻辑或数据库层使用的服务具有幂等性。 如果在服务网格级别使用超时,则必须同步服务中的服务使用者超时。如果必须实现服务的重复执行,则必须配置 Kubernetes 作业执行。
展望未来,一些服务功能将作为业务逻辑在服务中实现,而其他服务功能则作为平台功能提供。虽然使用正确的工具来完成正确的任务是一个很好的责任分离,但技术的激增极大地增加了整体的复杂性。在业务逻辑方面实现简单的服务需要很好地理解分布式技术堆栈,因为责任分散在每一层。
据 证实 Kubernetes 是可以扩展到数千个节点、数万个 pod 和数百万的 TPS。您的应用程序大小、复杂性,或者说是引入“云原生”复杂性的关键性因素,我还不清楚。
结论
有趣的是,微服务运动如何为采用 Docker 和 Kubernetes 等容器技术提供了如此大的动力。 虽然最初是推动这些技术发展的微服务实践,但现在 Kubernetes 定义了微服务架构的原则和实践。
最近的一个例子,我们距离接受函数模型作为有效的微服务原语并不远,而不是将其视为纳米服务的反模式。我们并没有充分的理由质疑云原生技术对于中小型案例的实用性和适用性,而是因为兴奋而有些不经意地跳了起来。
Kubernetes 拥有 ESB 和微服务的许多知识,因此,它是最终的分布式系统平台。 它是架构风格的技术,而不是相反的方式。无论好坏,时间会证明一切。
关于作者

Bilgin Ibryam (@bibryam)是 Red Hat 的首席架构师,提交者和 ASF 成员。 他是一名开源传播者,博客作者,《Camel Design Patterns》 和 《Kubernetes Patterns》 书籍的作者。 在他的日常工作中,Bilgin 喜欢指导编码和领导开发人员成功构建云原生解决方案。 他目前的工作重点是应用程序集成、分布式系统、消息传递、微服务、devops 和一般的云原生挑战。 你可以在 Twitter、Linkedin 或他的 博客 上找到他 。
4.3 - (2020)用Istio进行微服务和服务网格的解释
内容出处
Microservices and Service Mesh with Istio, Explained
https://hackernoon.com/microservices-and-service-mesh-with-istio-explained-eo1e3u7s
作者 Sudip Sengupta 发表于2020年7月
4.4 - (2021)分布式系统在 Kubernetes 上的进化
内容出处
The Evolution of Distributed Systems on Kubernetes
https://www.infoq.com/articles/distributed-systems-kubernetes/
分布式系统在 Kubernetes 上的进化
本文翻译自 Bilgin Ibryam 的文章 The Evolution of Distributed Systems on Kubernetes。
https://cloudnative.to/blog/distributed-systems-kubernetes/
备注:内容有删减,只摘抄了分布式系统发展和servicemesh关系的部分内容
在 3 月份的 QCon 上,我做了一个关于 Kubernetes 的分布式系统进化的演讲。首先,我想先问一个问题,微服务之后是什么?我相信大家都有各自的答案,我也有我的答案。你会在最后发现我的想法是什么。为了达到这个目的,我建议大家看看分布式系统的需求是什么?以及这些需求在过去是如何发展的,从单体应用开始到 Kubernetes,再到最近的 Dapr、Istio、Knative 等项目,它们是如何改变我们做分布式系统的方式。我们将尝试对未来做一些预测。
现代分布式应用
为了给这个话题提供更多的背景信息,我认为的分布式系统是由数百个组件组成的系统。这些组件可以是有状态的、无状态的或者无服务器的。此外,这些组件可以用不同的语言创建,运行在混合环境上,并开发开源技术、开放标准和互操作性。我相信你可以使用闭源软件来构建这样的系统,也可以在 AWS 和其他地方构建。具体到这次演讲,我将关注 Kubernetes 生态系统,以及你如何在 Kubernetes 平台上构建这样一个系统。
我们从分布式系统的需求讲起。我认为是我们要创建一个应用或者服务,并写一些业务逻辑。那从运行时的平台到构建分布式系统,我们还需要什么呢?在底层,最开始是我们要一些生命周期的能力。当你用任一语言开发你的应用时,我们希望有能力把这个应用可靠地打包和部署、回滚、健康检查。并且能够把应用部署到不同的节点上,并实现资源隔离、扩展、配置管理,以及所有这些。这些都是你创建分布式应用所需要的第一点。
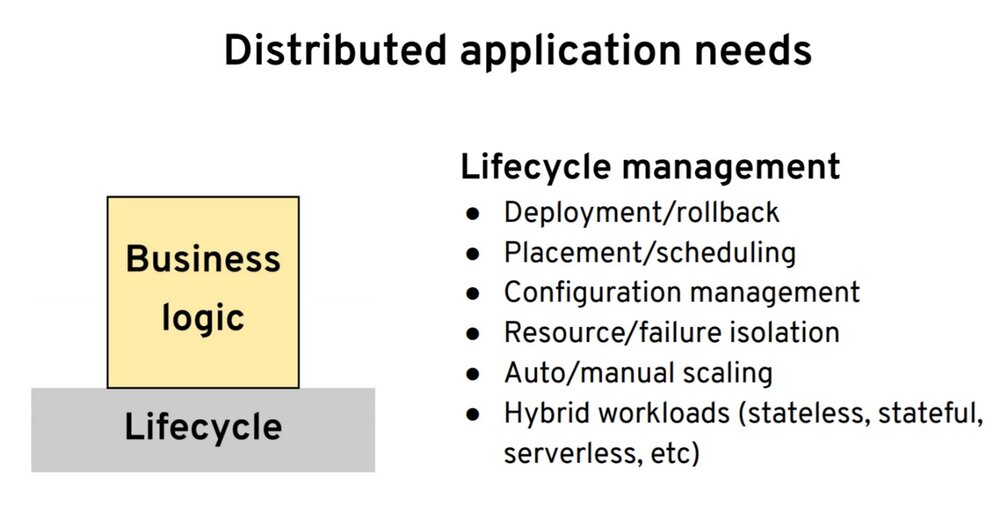
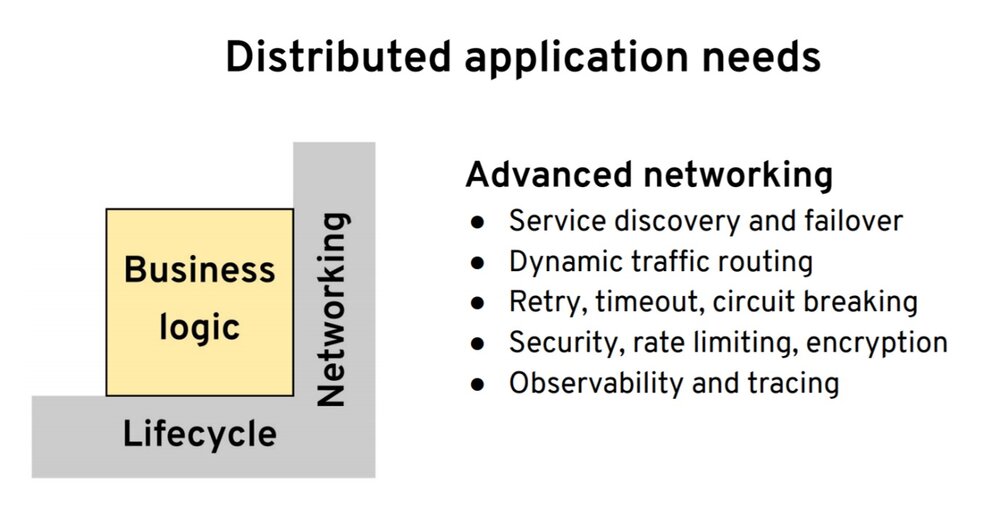
第二点是围绕网络。我们有了应用之后,我们希望它能够可靠地连接到其他服务,无论该服务是在集群内部还是在外部。我们希望其具有服务发现、负载均衡的能力。为了不同的发布策略或是其他的一些原因的我们希望有流量转移的能力。然后我们还希望其具有与其他系统进行弹性通信的能力,无论是通过重试、超时还是断路器。要有适当的安全保障,并且要有足够的监控、追踪、可观察性等等。
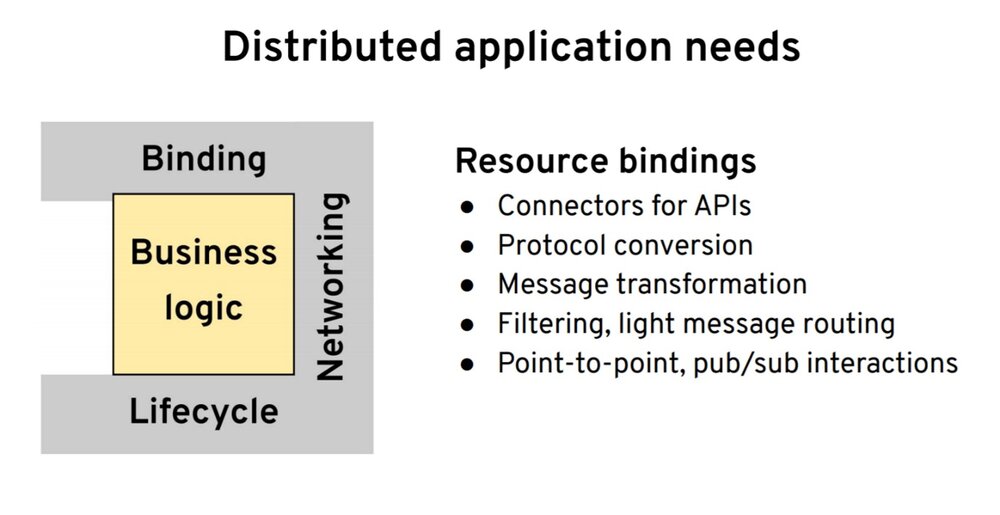
我们有了网络之后,接下来就是我们希望有能力与不同的 API 和端点交互,即资源绑定–与其他协议和不同的数据格式交互。甚至能够从一种数据格式转换成另一种数据格式。我还会在这里加入诸如过滤功能,也就是说,当我们订阅一个主题时,我们也许只对某些事件感兴趣。
你认为最后一类是什么?是状态。当我在说状态和有状态的抽象时,我并不是在谈论实际的状态管理,比如数据库或者文件系统的功能。我要说的更多是有关幕后依赖状态的开发人员抽象。可能,你需要具有工作流管理的能力。也许你想管理运行时间长的进程或者做临时调度或者某些定时任务来定期运行服务。也许你还想进行分布式缓存,具有幂等性或者支持回滚。所有这些都是开发人员级的原语,但在幕后,它们依赖于具有某种状态。你想随意使用这些抽象来创建完善的分布式系统。
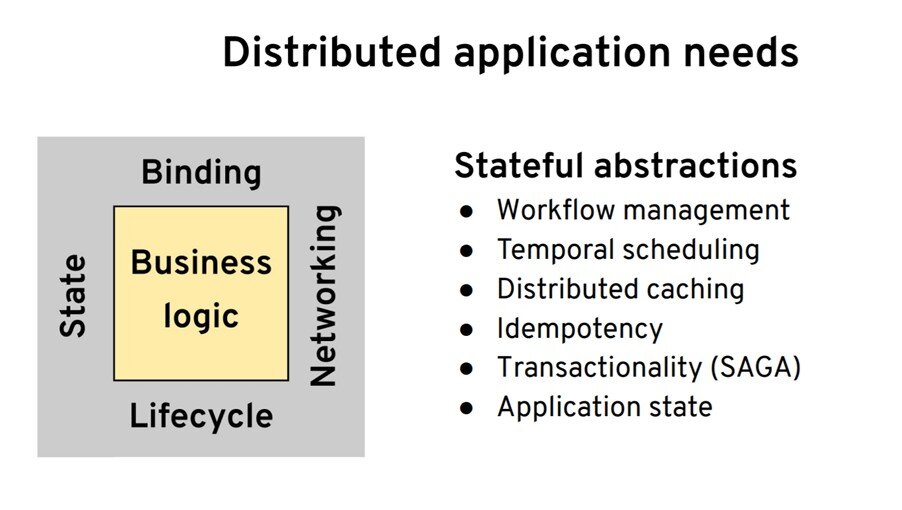
我们将使用这个分布式系统原语的框架来评估它们在 Kubernetes 和其他项目上的变化情况。
单体架构——传统中间件功能
假设我们从单体架构以及如何获得这些能力开始。在那种情况下,首先是当我说单体的时候,在分布式应用的情况下我想到的是 ESB。ESB 是相当强大的,当我们检查我们的需求列表时,我们会说 ESB 对所有有状态的抽象有很好的支持。
使用 ESB,你可以进行长时间运行的流程的编排、分布式事务、回滚和幂等。此外,ESB 还提供了出色的资源绑定能力,并且有数百个连接器,支持转换、编排,甚至有联网功能。最后,ESB 甚至可以做服务发现和负载均衡。
它具有围绕网络连接的弹性的所有功能,因此它可以进行重试。可能 ESB 本质上不是很分布式,所以它不需要非常高级的网络和发布能力。ESB 欠缺的主要是生命周期管理。因为它是单一运行时,所以第一件事就是你只能使用一种语言。通常是创建实际运行时的语言,Java、.NET 或者其他的语言。然后,因为是单一运行时,我们不能轻松地进行声明式的部署或者自动调配。部署是相当大且非常重的,所以它通常涉及到人机交互。这种单体架构的另一个难点是扩展:“我们无法扩展单个组件。”
最后却并非最不重要的一点是,围绕隔离,无论是资源隔离还是故障隔离。使用单体架构无法完成所有这些工作。从我们的需求框架来看,ESB 的单体架构不符合条件。

云原生架构——微服务和 Kubernetes
接下来,我建议我们研究一下云原生架构以及这些需求是如何变化的。如果我们从一个非常高的层面来看,这些架构是如何发生变化的,云原生可能始于微服务运动。微服务使我们可以按业务领域进行拆分单体应用。事实证明,容器和 Kubernetes 实际上是管理这些微服务的优秀平台。让我们来看一下 Kubernetes 对于微服务特别有吸引力的一些具体特性和功能。
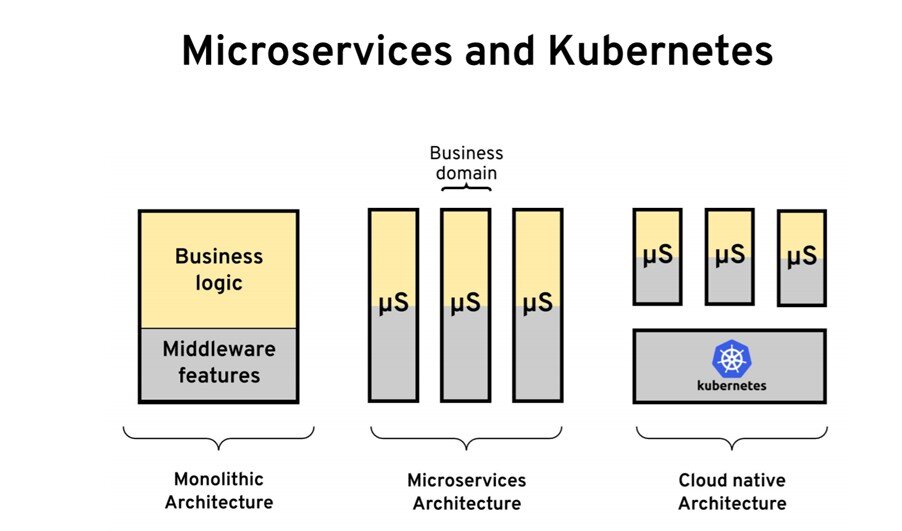
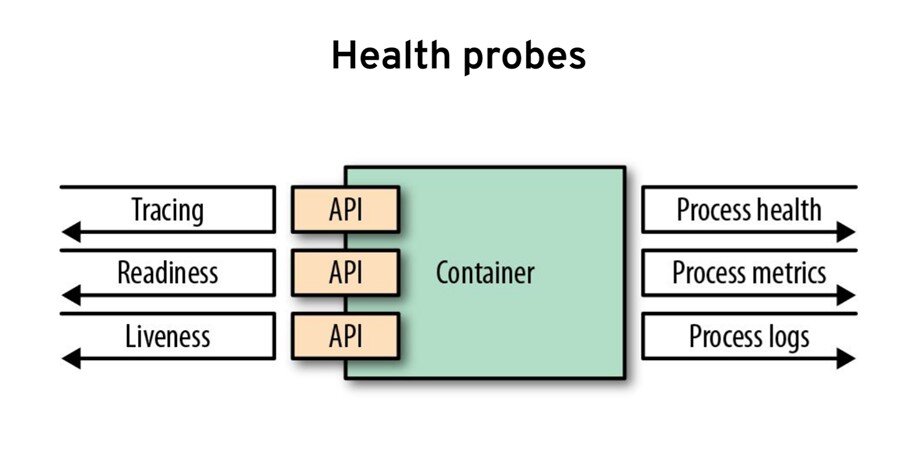
从一开始,进行健康状况探测的能力就是 Kubernetes 受欢迎的原因。在实践中,这意味着当你将容器部署到 Pod 中时,Kubernetes 会检查进程的运行状况。通常情况下,该过程模型还不够好。你可能仍然有一个已启动并正在运行的进程,但是它并不健康。这就是为什么还可以使用就绪度和存活度检查的原因。Kubernetes 会做一个就绪度检查,以确定你的应用在启动期间何时准备接受流量。它将进行活跃度检查,以检查服务的运行状况。在 Kubernetes 之前,这并不是很流行,但今天几乎所有语言、所有框架、所有运行时都有健康检查功能,你可以在其中快速启动端点。
Kubernetes 引入的下一个特性是围绕应用程序的托管生命周期——我的意思是,你不再控制何时启动、何时关闭服务。你相信平台可以做到这一点。Kubernetes 可以启动你的应用;它可以将其关闭,然后在不同的节点上移动它。为此,你必须正确执行平台在应用启动和关闭期间告诉你的事件。
Kubernetes 流行的另一件特性是围绕着声明式部署。这意味着你不再需要启动服务;检查日志是否已经启动。你不必手动升级实例——支持声明式部署的 Kubernetes 可以为你做到这一点。根据你选择的策略,它可以停止旧实例并启动新实例。此外,如果出现问题,可以进行回滚。
另外就是声明你的资源需求。创建服务时,将其容器化。最好告诉平台该服务将需要多少 CPU 和内存。Kubernetes 利用这些信息为你的工作负载找到最佳节点。在使用 Kubernetes 之前,我们必须根据我们的标准将实例手动放置到一个节点上。现在,我们可以根据自己的偏好来指导 Kubernetes,它将为我们做出最佳的决策。
如今,在 Kubernetes 上,你可以进行多语言配置管理。无需在应用程序运行时进行配置查找就可以进行任何操作。Kubernetes 会确保配置最终在工作负载所在的同一节点上。这些配置被映射为卷或环境变量,以供你的应用程序使用。
事实证明,我刚才谈到的那些特定功能也是相关的。比如说,如果要进行自动放置,则必须告诉 Kubernetes 服务的资源需求。然后,你必须告诉它要使用的部署策略。为了让策略正确运行,你的应用程序必须执行来自环境的事件。它必须执行健康检查。一旦采用了所有这些最佳实践并使用所有这些功能,你的应用就会成为出色的云原生公民,并且可以在 Kubernetes 上实现自动化了(这是在 Kubernetes 上运行工作负载的基本模式)。最后,还有围绕着构建 Pod 中的容器、配置管理和行为,还有其他模式。
我要简要介绍的下一个主题是工作负载。从生命周期的角度来看,我们希望能够运行不同的工作负载。我们也可以在 Kubernetes 上做到这一点。运行十二要素应用程序和无状态微服务非常简单。Kubernetes 可以做到这一点。这不是你将要承担的唯一工作量。可能你还有有状态的工作负载,你可以使用有状态集在 Kubernetes 上完成此工作。
你可能还有的另一个工作负载是单例。也许你希望某个应用程序的实例是整个集群中应用程序的唯一一个实例–你希望它成为可靠的单例。如果失败,则重新启动。因此,你可以根据需求以及是否希望单例至少具有一种或最多一种语义来在有状态集和副本集之间进行选择。你可能还有的另一个工作负载是围绕作业和定时作业–有了 Kubernetes,你也可以实现这些。
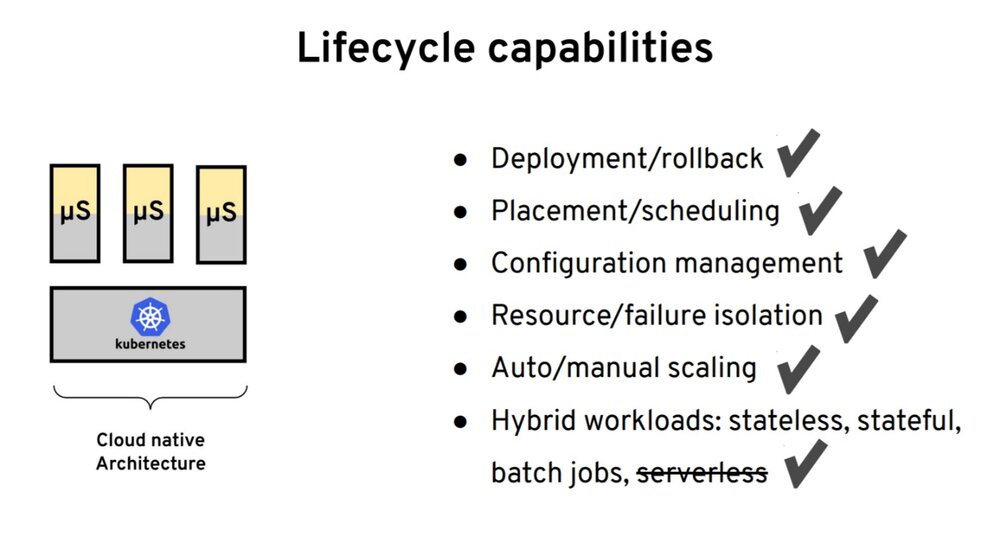
如果我们将所有这些 Kubernetes 功能映射到我们的需求,则 Kubernetes 可以满足生命周期需求。我通常创建的需求列表主要是由 Kubernetes 今天提供给我们的。这些是任何平台上的预期功能,而 Kubernetes 可以为你的部署做的是配置管理、资源隔离和故障隔离。此外,除了无服务器本身之外,它还支持其他工作负载。
然后,如果这就是 Kubernetes 给开发者提供的全部功能,那么我们该如何扩展 Kubernetes 呢?以及如何使它具有更多功能?因此,我想描述当今使用的两种常用方法。
进程外扩展机制
首先是 Pod 的概念,Pod 是用于在节点上部署容器的抽象。此外,Pod 给我们提供了两组保证:
- 第一组是部署保证 – Pod 中的所有容器始终位于同一个节点上。这意味着它们可以通过 localhost 相互通信,也可以使用文件系统或通过其他 IPC 机制进行异步通信。
- Pod 给我们的另一组保证是围绕生命周期的。Pod 中的所有容器并非都相等。
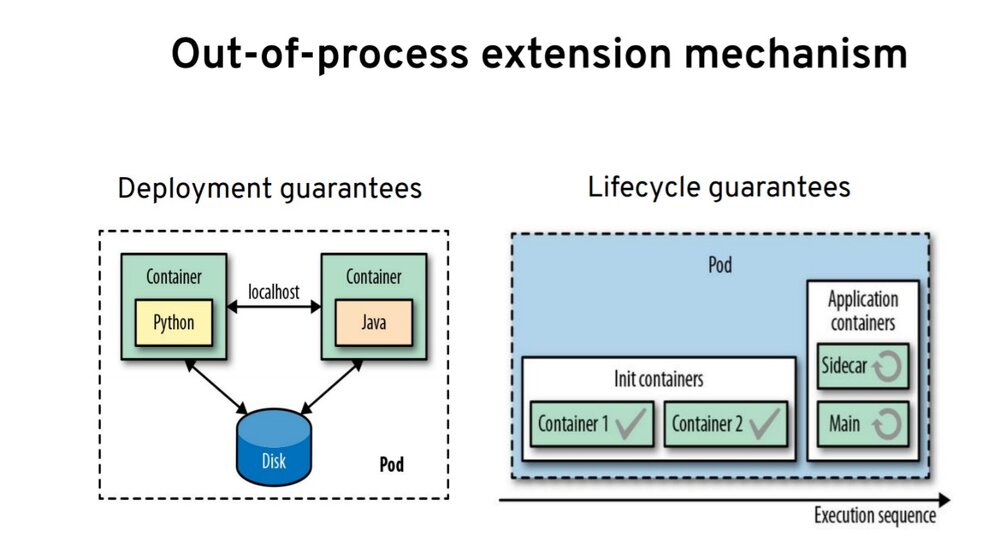
根据使用的是 init 容器还是应用程序容器,你会获得不同的保证。例如,init 容器在开始时运行;当 Pod 启动时,它按顺序一个接一个地运行。他们仅在之前的容器已成功完成时运行。它们有助于实现由容器驱动的类似工作流的逻辑。
另一方面,应用程序容器是并行运行的。它们在整个 Pod 的生命周期中运行,这也是 sidecar 模式的基础。sidecar 可以运行多个容器,这些容器可以协作并共同为用户提供价值。这也是当今我们看到的扩展 Kubernetes 附加功能的主要机制之一。
为了解释以下功能,我必须简要地告诉你 Kubernetes 内部的工作方式。它是基于调谐循环的。调谐循环的思想是将期望状态驱动到实际状态。在 Kubernetes 中,很多功能都是靠这个来实现的。例如,当你说我要两个 Pod 实例,这系统的期望状态。有一个控制循环不断地运行,并检查你的 Pod 是否有两个实例。如果不存在两个实例,它将计算差值。它将确保存在两个实例。
这方面的例子有很多。一些是副本集或有状态集。资源定义映射到控制器是什么,并且每个资源定义都有一个控制器。该控制器确保现实世界与所需控制器相匹配,你甚至可以编写自己的自定义控制器。
当在 Pod 中运行应用程序时,你将无法在运行时加载任何配置文件更改。然而,你可以编写一个自定义控制器,检测 config map 的变化,重新启动 Pod 和应用程序–从而获取配置更改。
事实证明,即使 Kubernetes 拥有丰富的资源集合,但它们并不能满足你的所有不同需求。Kubernetes 引入了自定义资源定义的概念。这意味着你可以对需求进行建模并定义适用于 Kubernetes 的 API。它与其他 Kubernetes 原生资源共存。你可以用能理解模型的任何语言编写自己的控制器。你可以设计一个用 Java 实现的 ConfigWatcher,描述我们前面所解释的内容。这就是 operator 模式,即与自定义资源定义一起使用的控制器。如今,我们看到很多 operator 加入,这就是第二种扩展 Kubernetes 附加功能的方式。
接下来,我想简单介绍一下基于 Kubernetes 构建的一些平台,这些平台大量使用 sidecar 和 operator 来给开发者提供额外的功能。
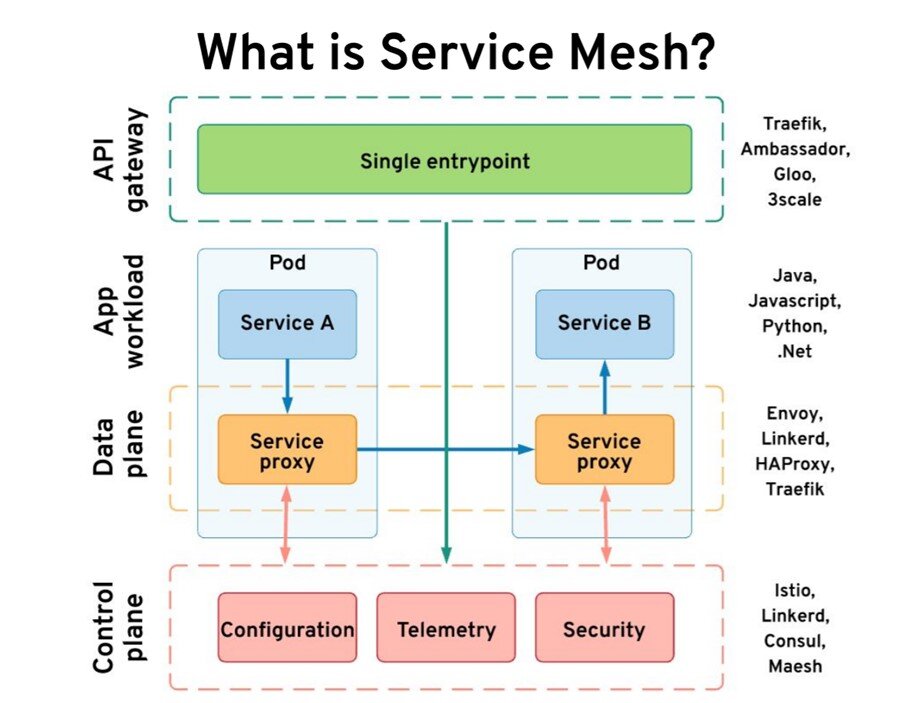
什么是服务网格?
让我们从服务网格开始,什么是服务网格?
我们有两个服务,服务 A 要调用服务 B,并且可以用任何语言。把这个当做是我们的应用工作负载。服务网格使用 sidecar 控制器,并在我们的服务旁边注入一个代理。你最终会在 Pod 中得到两个容器。代理是一个透明的代理,你的应用对这个代理完全无感知–它拦截所有传入和传出的流量。此外,代理还充当数据防火墙。
这些服务代理的集合代表了你的数据平面,并且很小且无状态。为了获得所有状态和配置,它们依赖于控制平面。控制平面是保持所有配置,收集指标,做出决定并与数据平面进行交互的有状态部分。此外,它们是不同控制平面和数据平面的正确选择。事实证明,我们还需要一个组件-一个 API 网关,以将数据获取到我们的集群中。一些服务网格具有自己的 API 网关,而某些使用第三方。如果你研究下所有这些组件,它们将提供我们所需的功能。
API 网关主要专注于抽象我们服务的实现。它隐藏细节并提供边界功能。服务网格则相反。在某种程度上,它增强了服务内的可见性和可靠性。可以说,API 网关和服务网格共同提供了所有网络需求。要在 Kubernetes 上获得网络功能,仅使用服务是不够的:“你需要一些服务网格。”
未来云原生趋势–生命周期趋势
在接下来的部分,我列出了一些我认为在这些领域正在发生令人振奋的发展的项目。
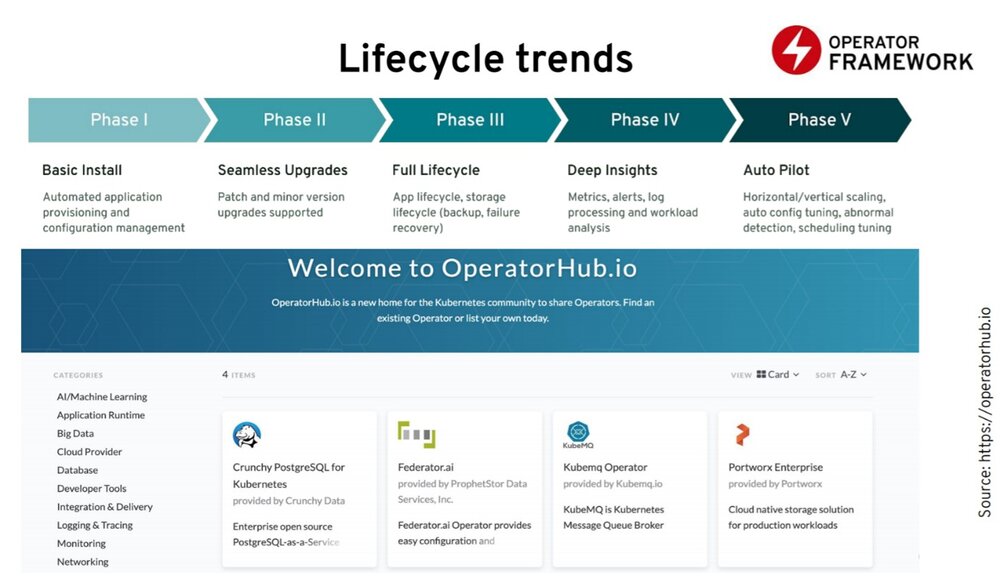
我想从生命周期开始。通过 Kubernetes,我们可以为应用程序提供一个有用的生命周期,这可能不足以进行更复杂的生命周期管理。比如,如果你有一个更复杂的有状态应用,则可能会有这样的场景,其中 Kubernetes 中的部署原语不足以为应用提供支持。
在这些场景下,你可以使用 operator 模式。你可以使用一个 operator 来进行部署和升级,还可以将 S3 作为服务备份的存储介质。此外,你可能还会发现 Kubernetes 的实际健康检查机制不够好。假设存活检查和就绪检查不够好。在这种情况下,你可以使用 operator 对你的应用进行更智能的存活和就绪检查,然后在此基础上进行恢复。
第三个领域就是自动伸缩和调整。你可以让 operator 更好的了解你的应用,并在平台上进行自动调整。目前,编写 operator 的框架主要有两个,一个是 Kubernetes 特别兴趣小组的 Kubebuilder,另一个是红帽创建的 operator 框架的一部分–operator SDK。它有以下几个方面的内容:
Operator SDK 让你可以编写 operator – operator 生命周期管理器来管理 operator 的生命周期,以及可以发布你的 operator 到 OperatorHub。如今在 OperatorHub,你会看到 100 多个 operator 用于管理数据库、消息队列和监控工具。从生命周期空间来看,operator 可能是 Kubernetes 生态系统中发展最活跃的领域。
网络趋势 - Envoy
我选的另一个项目是 Envoy。服务网格接口规范的引入将使你更轻松地切换不同的服务网格实现。在部署上 Istio 对架构进行了一些整合。你不再需要为控制平面部署 7 个 Pod;现在,你只需要部署一次就可以了。更有趣的是在 Envoy 项目的数据平面上所正在发生的:越来越多的第 7 层协议被添加到 Envoy 中。

服务网格增加了对更多协议的支持,比如 MongoDB、ZooKeeper、MySQL、Redis,而最新的协议是 Kafka。我看到 Kafka 社区现在正在进一步改进他们的协议,使其对服务网格更加友好。我们可以预料将会有更紧密的集成、更多的功能。最有可能的是,会有一些桥接的能力。你可以从服务中在你的应用本地做一个 HTTP 调用,而代理将在后台使用 Kafka。你可以在应用外部,在 sidecar 中针对 Kafka 协议进行转换和加密。
另一个令人兴奋的发展是引入了 HTTP 缓存。现在 Envoy 可以进行 HTTP 缓存。你不必在你的应用中使用缓存客户端。所有这些都是在 sidecar 中透明地完成的。有了 tap 过滤器,你可以 tap 流量并获得流量的副本。最近,WebAssembly 的引入,意味着如果你要为 Envoy 编写一些自定义的过滤器,你不必用 C++ 编写,也不必编译整个 Envoy 运行时。你可以用 WebAssembly 写你的过滤器,然后在运行时进行部署。这些大多数还在进行中。它们不存在,说明数据平面和服务网格无意停止,仅支持 HTTP 和 gRPC。他们有兴趣支持更多的应用层协议,为你提供更多的功能,以实现更多的用例。最主要的是,随着 WebAssembly 的引入,你现在可以在 sidecar 中编写自定义逻辑。只要你没有在其中添加一些业务逻辑就可以了。
智能的 sidecar 和愚蠢的管道
如果更深入地看,那可能是什么样的,你可以使用一些高级语言编写业务逻辑。是什么并不重要,不必仅是 Java,因为你可以使用任何其他语言并在内部开发自定义逻辑。
你的业务逻辑与外部世界的所有交互都是通过 sidecar 发生的,并与平台集成进行生命周期管理。它为外部系统执行网络抽象,为你提供高级的绑定功能和状态抽象。sidecar 是你不需要开发的东西。你可以从货架上拿到它。你用一点 YAML 或 JSON 配置它,然后就可以使用它。这意味着你可以轻松地更新 sidecar,因为它不再被嵌入到你的运行时。这使得打补丁、更新变得更加更容易。它为我们的业务逻辑启用了多语言运行时。
微服务之后是什么?
这让我想到了最初的问题,微服务之后是什么?
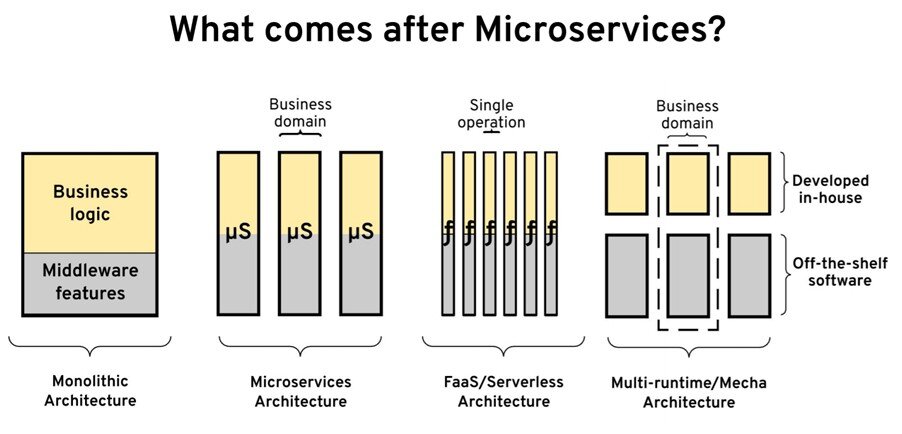
如果我们看下架构的发展历程,应用架构在很高的层面上是从单体应用开始的。然而微服务给我们提供了如何把一个单体应用拆分成独立的业务域的指导原则。之后又出现了无服务器和功能即服务(FaaS),我们说过可以按操作将其进一步拆分,从而实现极高的可扩展性-因为我们可以分别扩展每个操作。
我想说的是 FaaS 并不是最好的模式 – 因为功能并不是实现合理的复杂服务的最佳模式,在这种情况下,当多个操作必须与同一个数据集进行交互时,你希望它们驻留在一起。可能是多运行时(我把它称为 Mecha 架构),在该架构中你将业务逻辑放在一个容器中,而所有与基础设施相关的关注点作为一个单独的容器存在。它们共同代表多运行时微服务。也许这是一个更合适的模型,因为它有更好的属性。
你可以获得微服务的所有好处。仍然将所有域和所有限界上下文放在一处。你将所有的基础设施和分布式应用需求放在一个单独的容器中,并在运行时将它们组合在一起。大概,现在最接近这种模型的是 Dapr。他们正在遵循这种模型。如果你仅对网络方面感兴趣,那么可能使用 Envoy 也会接近这种模型。
5 - Servicemesh的演进
6 - Servicemesh的市场竞争
Linkerd、Consul、Istio、Kuma、Traefik、AWS App服务网格全方位对比
6.1 - (2017)2017年Servicemesh年度总结
在过去的几年中,微服务技术得以迅猛普及,和容器技术一起成为这两年中最吸引眼球的技术热点。而以Spring Cloud为代表的传统侵入式开发框架,占据着微服务市场的主流地位,甚至一度成为微服务的代名词。
直到2017年年底,当非侵入式的Service Mesh技术终于从萌芽到走向了成熟,当Istio横空出世,人们才惊觉:微服务并非只有侵入式一种玩法,微服务更不是Spring Cloud的独角戏!
这一次的新生力量,完全不按照常理出牌,出场就霸道地掀翻桌子,直接摆出新的玩法:Service Mesh,下一代微服务!让我们一起来回顾这一场起于2017年的Service Mesh大战,一起领略各家产品的风采。
Service Mesh的萌芽期
在我们正式开始之前,我们将时间回到2016年:有些故事背景需要预交交代一下。
虽然直到2017年底,Service Mesh才开始较大规模被世人了解,这场微服务市场之争也才显现,但是其实Service Mesh这股微服务的新势力,早在 2016年初就开始萌芽:
-
2016年1月15日,离开Twitter的基础设施工程师William Morgan和Oliver Gould,在github上发布了Linkerd 0.0.7版本,他们同时组建了一个创业小公司Buoyant,业界第一个Service Mesh项目诞生。
-
2016年,Matt Klein在Lyft默默的进行Envoy的开发。Envoy诞生的时间其实要比Linkerd更早一些,只是在Lyft内部不为人所知。
在2016年初,Service Mesh还只是Buoyant公司的内部词汇,而之后,随着Linkerd的开发和推广,Service Mesh这个名词开始逐步走向社区并被广泛接受,喜爱和推崇:
- 2016年9月29日在SF Microservices上,“Service Mesh”这个词汇第一次在公开场合被使用。这标志着“Service Mesh”这个词,从Buoyant公司走向社区。
- 2016年10月,Alex Leong开始在buoyant公司的官方Blog中开始”A Service Mesh for Kubernetes”系列博客的连载。随着”The services must mesh”口号的喊出,buoyant和Linkerd开始service mesh概念的布道。
在2016年,第一代的Service Mesh产品稳步推进:
- 2016年9月13日,Matt Klein宣布Envoy在github开源,直接发布1.0.0版本
- 2016年下半年,Linkerd陆续发布了0.8和0.9版本,开始支持HTTP/2 和gRPC,1.0发布在即;同时,借助Service Mesh在社区的认可度,Linkerd在年底开始申请加入CNCF。
而在这个世界的另外一个角落,Google和IBM两位巨人,握手开始合作,他们联合Lyft,启动了Istio项目。这样,在第一代Service Mesh还未走向市场主流时,以Istio为代表的第二代Service Mesh就迫不及待地准备上路。
现在我们可以进入主题,开始2017和2018年Service Mesh市场竞争的回顾。
急转而下的Linkerd
2017年,Linkerd迎来了一个梦幻般的开局,喜讯连连:
- 2017年1月23日,Linkerd加入CNCF
- 2017年3月7日,Linkerd宣布完成千亿次产品请求
- 2017年4月25日,Linkerd 1.0版本发布
可谓各条战线都进展顺利:产品完成1.0 release,达成最重要的里程碑;被客户接受并在生产线上成功大规模应用,这代表着市场的认可;进入CNCF更是意义重大,是对Linkerd的极大认可,也使得Linkerd声名大噪。一时风光无量,可谓”春风得意马蹄疾,一日看尽长安花”。
需要特别指出的是,Linkerd加入CNCF,对于Service Mesh技术是一个非常重要的历史事件:这代表着社区对Service Mesh理念的认同和赞赏,Service Mesh也因此得到社区更大范围的关注。
趁热打铁,就在Linkerd 1.0版本发布的同一天,Service Mesh的前驱继续Service Mesh的布道:
- 2017年4月25日,William Morgan发布博文”What’s a service mesh? And why do I need one?“。正式给Service Mesh做了一个权威定义。
然而现实总是那么残酷,这个美好的开局,未能延续多久就被击碎:
- 2017年5月24日,Istio 0.1 release版本发布,google和IBM高调宣讲,社区反响热烈,很多公司在这时就纷纷站队表示支持Istio。
Linkerd的风光瞬间被盖过,从意气风发的少年一夜之间变成过气网红。当然,从产品成熟度上来说,linkerd作为业界仅有的两个生产级Service Mesh实现之一,暂时还可以在Istio成熟前继续保持市场。但是,随着Istio的稳步推进和日益成熟,外加第二代Service Mesh的天然优势,Istio取代第一代的Linkerd只是个时间问题。
面对Google和IBM加持的Istio,linkerd实在难有胜算:
- Istio作为第二代Service Mesh,通过控制平面带来了前所未有的控制力,远超Linkerd。
- Istio通过收编和Linkerd同为第一代Service Mesh的Envoy,直接拥有了一个功能和稳定性与Linkerd在一个水准的数据平面。
- 基于c++的Envoy在性能和资源消耗上本来就强过基于Scala/Jvm的Linkerd
- Google和IBM在人力,资源和社区影响力方面远非Buoyant公司可以比拟
Linkerd的发展态势顿时急转而下,未来陷入一片黑暗。出路在哪里?
在一个多月后,Linkerd给出一个答案:和Istio集成,成为Istio的数据面板。
- 2017年7月11日,Linkerd发布版本1.1.1,宣布和Istio项目集成。Buoyant发表博文”Linkerd and Istio: like peanut butter and jelly”。
这个方案在意料之中,毕竟面对Google和IBM的联手威胁,选择低头和妥协是可以理解的。只是存在两个疑问:
- 和Envoy相比,Linkerd并没有特别优势。考虑编程语言的天生劣势,Linkerd想替代Envoy难度非常之大。
- 即使替代成功,在Istio的架构下,只是作为一个数据平面存在的Linkerd,可以发挥的空间有限。这种境地的Linkerd,是远远无法承载起Buoyant的未来的。
Linkerd的这个谜团,直到2017年即将结束的12月,在Conduit发布之后才被解开。
波澜不惊的Envoy
自从在2016年决定委身于Istio之后,Envoy就开始了一条波澜不惊的平稳发展之路,和Linkerd的跌宕起伏完全不同。
在功能方面,由于定位在数据平面,因此Envoy无需考虑太多,很多工作在Istio的控制平面完成就好,Envoy从此专心于将数据平面做好,完善各种细节。在市场方面,Envoy和Linkerd性质不同,不存在生存和发展的战略选择,也没有正面对抗生死大敌的巨大压力。Envoy在2017年有条不紊地陆续发布了1.2、1.3、1.4和1.5版本,在2018年发布了1.6、1.7、1.8版本,稳步地完善自身,表现非常稳健。
稳打稳扎的Envoy一方面继续收获独立客户,一方面伴随Istio一起成长。作为业界仅有的两个生产级Service Mesh实现之一,Envoy在2017年中收获了属于它的殊荣:
- 2017年9月14日,Envoy加入CNCF,成为CNCF的第二个Service Mesh项目
可谓名至实归,水到渠成。作为一个无需承载一家公司未来的开源项目,Envoy在2017和2018年的表现,无可挑剔。
背负使命的Istio
从Google和IBM联手决定推出Istio开始,Istio就注定永远处于风头浪尖,无论成败。
Istio背负了太多的使命:
- 建立Google和IBM在微服务市场的统治地位
- 为Google和IBM的公有云打造杀手锏级特性
- 在k8s的基础上,延续Google的战略布局
Google在企业市场的战略布局,是从底层开始,一步一步向上,一步一步靠近应用。刚刚大获全胜的K8s为Istio准备了一个非常好的基石,而Istio的历史使命,就是继k8s拿下容器之后,更进一步,拿下微服务!
2017年,Istio稳步向前,先后发布0.1 / 0.2 / 0.3 / 0.4 四个版本,在2018年初,Istio的发布周期修改为每月一次。
在社区方面,Istio借助Google和IBM的大旗,外加自身过硬的实力、先进的理念,很快获得了社区的积极响应和广泛支持。包括Oracle和Red Hat在内的业界大佬都明确表示对支持Istio,而Isito背后,还有日渐强大的Kubernetes和CNCF社区。
在平台支持方面,Istio的初期版本只支持k8s平台,从0.3版本开始提供对非k8s平台的支持。从策略上说,Istio借助了k8s,但是没有强行绑定在k8s上。
Istio面世之后,赞誉不断,尤其是Service Mesh技术的爱好者,可以说是为之一振:以新一代Service Mesh之名横空出世的Istio,对比Linkerd,优势明显。同时产品路线图上有一大堆令人眼花缭乱的功能。假以时日,如果Istio能顺利地完成开发,稳定可靠,那么这会是一个非常美好、值得憧憬的大事件,它的意义重大:
- 重新定义微服务开发方式,让Service Mesh成为主流技术
- 大幅降低微服务开发的入门门槛,让更多的企业和开发人员可以落地微服务
- 统一微服务的开发流程,标准化开发/运维方式
2018年上半年的Istio,在万众瞩目充满期待之时,突然陷入困境长达数月:开发进度放缓,代码质量下降,经常犯低级错误。表现令人惊讶和迷惑,好在这个状态在年中开始好转,进入下半年之后Istio开始稳打稳扎:
- 2018年6月1日,发布0.8.0 LTS版本,这是Istio第一个长期支持版本
- 2018年7月31日,发布令整个社区期待已久的1.0.0版本
- 2018年10月,预计发布1.1.0版本
从目前发展态势看,Istio慢慢的完善产品,表现相对2017年要成熟很多,虽然依然存在诸多问题,虽然依然缺乏大规模的落地实践。但相信随着时间的推移,Google和Istio社区应该能够继续向前推进。
背水一战的Buoyant
2017年底的KubeConf,在Service Mesh成为大会热点、Istio备受瞩目时,Buoyant公司出人意料地给了踌躇满志又稍显拖沓的Istio重重一击:
- 2017年12月5日,Conduit 0.1.0版本发布,Istio的强力竞争对手亮相KubeConf。
Conduit的整体架构和Istio一致,借鉴了Istio数据平面+控制平面的设计,同时别出心裁地选择了Rust编程语言来实现数据平面,以达成Conduit 宣称的更轻、更快和超低资源占用。
继Isito之后,业界第二款第二代Service Mesh产品就此诞生,一场大战就此浮出水面。Buoyant在Linkerd不敌Istio的恶劣情况下,绝地反击,祭出全新设计的Conduit作为对抗Istio的武器。
需要额外指出的是,作为一家初创型企业,在第一款主力产品Linkerd被Istio强力阻击之后,Buoyant已经身陷绝境,到了生死存亡之秋,作为背负公司期望,担负和Istio正面抗衡职责的Conduit,可谓压力巨大。
从目前得到的信息分析,Conduit明显是有备而来,针对Istio当前状况,针锋相对的:
- 编程语言:为了达成更轻、更快和更低资源消耗的目标,考虑到Istio的数据面板用的是基于C++语言的Envoy,Conduit跳过了Golang,直接选择了Rust,颇有些剑走偏锋的意味。不过,单纯以编程语言而言,在能够完全掌握的前提下,Rust的确是做Proxy的最佳选择。考虑到Envoy在性能方面的良好表现,Conduit要想更进一步,选择Rust也是可以理解。
- 架构设计:在借鉴Istio整体架构的同时,Conduit做了一些改进。首先Conduit控制平面的各个组件是以服务的方式提供功能的,极富弹性。另外,控制平面特意为定制化需求进行了可扩展设计,可以通过编写gPRC插件来扩展Conduit的功能而无需直接修改Conduit,这对于有定制化需求的客户是非常便利的。
然而,要抗衡Istio和其身后的Google与IBM,谈何容易。尤其控制平面选择Rust,成为一把双刃剑,固然Rust的上佳表现让Conduit在性能和资源消耗方面有不小的亮点,但是Rust毕竟是小众语言,普及程度远远不能和Java/C++/Golang相比,导致Conduit很难从社区借力,体现在Conduit的contributor数量长期停滞在20人上下。Conduit几乎是凭Buoyant以一家之力在独立支撑对抗Istio庞大的社区,终于难以为继:
- 2018年7月,Conduit 0.5发布,同时宣布这是 Conduit 最后一个版本,Conduit未来将作为Linkerd2.0的基础继续存在。随后Conduit的github仓库被从
runconduit/conduit更名为linkerd/linkerd2
在2017年5月Istio发布0.1版本之后,在巨大的生存压力下,Buoyant就一直在苦苦寻找出路,尝试过多种思路:
- 用Linkerd做数据平面,和Istio集成,替代Envoy。但Linkerd终究是Scala编写,做数据平面和Envoy比毫无优势,Istio官方也没有任何正面回应,不了了之
- 2017年底启动Conduit项目,剑走偏锋选择Rust做数据平面,但控制平面和Istio相比相去甚远,最终在2018年5月停止发展,转为Linkerd2.0。
- 2018年5月尝试在GraalVM上运行Linkerd,试图通过将Linkerd提前编译为本地可执行文件,以换取更快的启动时间和更少的内存占用。但后续未见有进一步的信息。
- 2018年5月启动Linkerd2.0,在Conduit的基础上(也许应该称为改名?)继续发展,定位为k8s平台上的轻量级Service Mesh。
作为Service Mesh先驱,Buoyant这两年中的发展道路,充满挑战,面对Istio和背后的Google,艰难险阻可想而知,期待他们在后面能有更好的表现。
其他参与者
Service Mesh市场,除了业界先驱Linkerd/Envoy,和后起之秀Istio/Conduit,还有一些其它的竞争者陆陆续续在2017和2018年进入这个市场。
Nginmesh
首先是nginmesh,来自大名鼎鼎的Nginx,定位为"Istio compatible service mesh using NGINX":
- 2017年9月,在美国波特兰举行的nginx.conf大会上,nginx宣布了nginmesh。随即在github上发布了0.1.6版本。
- 2017年12月6日,nginmesh 0.2.12版本发布
- 2017年12月25日,nginmesh 0.3.0版本发布
之后沉寂过一段时间,后来又突然持续更新,接连发布了几个版本。但是,在2018年7月发布0.7.1版本之后,就停止提交代码。
Aspen Mesh
来自大名鼎鼎的F5 Networks公司,基于Istio构建,定位企业服务网格,口号是"Service MeshMade Easy"。Aspen Mesh项目据说启动非常之早,在2017年5月Istio发布0.1版本不久之后就开始组件团队进行开发,但是一直以来都非常低调,外界了解到的信息不多。
在2018年9月,Aspen Mesh 1.0发布,基于Istio 1.0。注意这不是一个开源项目,但是可以在Aspen Mesh的官方网站上申请免费试用。
Consul Connect
Consul是来自HashiCorp公司的产品,主要功能是服务注册和服务发现,基于Golang和Raft协议。
在2018年6月26日发布的Consul 1.2版本中,提供了新的Connect功能,能够将现有的Consul集群自动转变为Service Mesh。Connect 通过自动TLS加密和基于鉴权的授权机制支持服务和服务之间的安全通信。
Kong
Kong是被广泛使用的开源API Gateway,在2018年9月18号,kong宣布1.0版本准备发布(实际为9月26日在github上发布了1.0.0rc1版本,GA版本即将发布),而在1.0发布之后kong将转型为服务控制平台,支持Service Mesh。
比较有意思的是,Kong CTO Marco Palladino 撰文提出"Service Mesh Pattern"的概念,即Service Mesh是一种新的模式,而不是一种新的技术。
Maistra
2018年9月,Red Hat的OpenShift Service Mesh技术预览版上线,基于Istio。
Red Hat是Istio项目的早期采用者和贡献者,希望将Istio正式成为OpenShift平台的一部分。Red Hat为OpenShift上的Istio开始了一个技术预览计划,为现有的OpenShift Container Platform客户提供在其OpenShift集群上部署和使用Istio平台的能力。
Red Hat正在与上游Istio社区合作,以帮助推进Istio框架,按照Red Hat的惯例,围绕Istio的工作也是开源的。为此Red Hat创建了一个名为Maistra的社区项目。
Service Mesh国内发展
2017年,随着Service Mesh的发展,国内技术社区也开始通过新闻报道/技术文章等开始接触Service Mesh,但是传播范围和影响力都非常有限。直到2017年底才剧烈升温,开始被国内技术社区关注:
- 2017年10月QCon上海站,来自敖小剑的名为”Service Mesh:下一代微服务”的演讲,成为Service Mesh技术在国内大型技术峰会上的第一次亮相。
- 2017年12月,在全球架构师峰会(ArchSummit)2017北京站上,华为田晓亮分享了”Service Mesh在华为云的实践”。
- 2017年12月,新浪微博周晶分享Service Mesh在微博的落地情况。
- 2018年6月,Service Mesh中国技术社区成立,网站servicemesher.com开通,并开始在杭州,北京,深圳组织多场线下Meetup,同时组织翻译Envoy,Istio官方文档和各种博客文章,大力推动了Service Mesh在国内的交流与发展。
- 2018年7月,Istio核心开发团队成员Lin Sun在ArchSummit2018深圳站进行了名为"Istio-构造、守护、监控微服务的守护神"的演讲,这是Istio官方在国内第一次亮相。
之后,作为Service Mesh国内最早的开发和实践者,以下公司相继宣布和开源了自己的Service Mesh产品:
- 2017年底,新浪微博Service Mesh的核心实现,跨语言通信和服务治理已经在Motan系列项目中提供
- 2018年6月,蚂蚁金服对外宣布Service Mesh类产品SOFAMesh,这是一个基于Istio的增强扩展版本,并使用基于Golang开发的SOFAMosn作为数据平面替代Envoy。
- 2018年8月,华为开源了基于Golang的Service Mesh产品——Mesher。
从2017年底开始,国内技术社区就对Service Mesh保持密切关注,尤其在Servicemesher社区成立后,社区内的分享和讨论非常密切,形成了良好的技术交流氛围。以蚂蚁金服、新浪微博、华为为代表的前锋力量相继开源为国内Service Mesh社区的繁荣注入了活力,以InfoQ为代表的技术媒体也一直保持对Service Mesh这种前沿技术的关注。
总结
Service Mesh在过去的两年间,迅猛发展,涌现出多个产品,市场竞争激烈。而目前看,Istio借助k8s和云原生的大潮,依托Google在社区的巨大号召力,发展势头良好,有望成为这一轮大战的赢家。
在下一章,我们将详细介绍Istio的架构和功能。
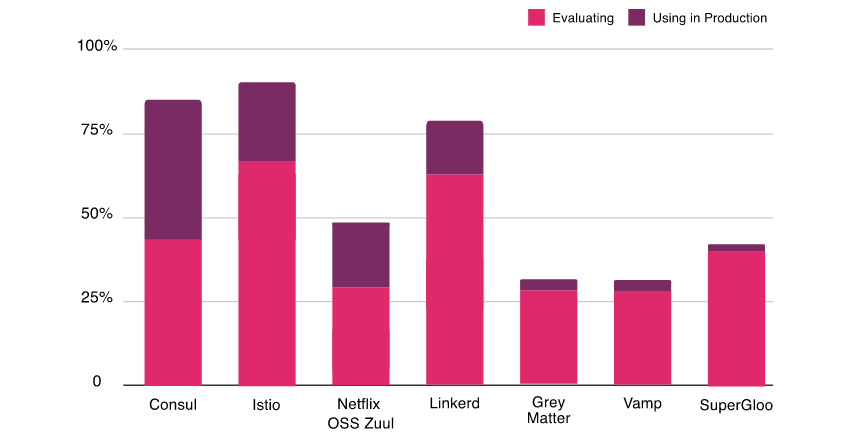
6.2 - (2021)服务网格除了 Istio,其实你还可以有其它 8 种选择
前言
9 open-source service meshes compared
Bill Doerrfeld, Consultant, Doerrfeld.io
https://techbeacon.com/app-dev-testing/9-open-source-service-meshes-compared
服务网格除了 Istio,其实你还可以有其它 8 种选择
https://z.itpub.net/article/detail/91AA8B3895CE8F037D73675116731CED
哪种服务网格最适合你的企业?近年来,Kubernetes 服务网格框架数量增加迅速,使得这成为一个棘手的问题。
下面将介绍 9 种较受欢迎的用以支撑微服务开发的服务网格框架,每种方案都给出了其适用场景。
什么是服务网格
服务网格近年来有很高的话题度,背后的原因是什么?
微服务已经成为一种灵活快速的开发方式。然而,随着微服务数量成倍数地增长,开发团队开始遇到了部署和扩展性上的问题。
容器和 Kubernetes 这样的容器编排系统 ,将运行时和服务一起打包进镜像,调度容器到合适的节点,运行容器。这个方案可以解决开发团队遇到的不少问题[1]。然而,在这个操作流程中仍存在短板:如何管理服务间的通信。
在采用服务网格的场景下,以一种和应用代码解耦的方式,增强了应用间统一的网络通信能力。服务网格扩展了集群的管理能力,增强可观测性、服务发现、负载均衡、IT 运维监控及应用故障恢复等功能。
服务网格概览
服务网格一直有很高的热度。正如 Linkerd 的作者 William Morgan 所提到[2]的:“服务网格本质上无非就是和应用捆绑在一起的用户空间代理。” 此说法相当简洁,他还补充道,“如果你能透过噪音看清本质,服务网格能给你带来实实在在的重要价值。”
Envoy 是许多服务网格框架的核心组件,是一个通用的开源代理,常被用于 Pod 内的 sidecar 以拦截流量。也有服务网格使用另外的代理方案。
若论具体服务网格方案的普及程度,Istio 和 Linkerd 获得了更多的认可。也有其它可选项,包括 Consul Connect,Kuma,AWS App Mesh和OpenShift。下文会阐述9种服务网格提供的关键特性。
Istio
Istio 是基于 Envoy 构建的一个可扩展的开源服务网格。开发团队可以通过它连接、加密、管控和观察应用服务。Istio 于 2017 年开源,目前 IBM、Google、Lyft 仍在对其进行持续维护升级。Lyft 在 2017 年把 Envoy 捐赠给了 CNCF。
Istio 花了不少时间去完善增强它的功能特性。Istio 的关键特性包括负载均衡、流量路由、策略创建、可度量性及服务间认证。
Istio 有两个部分组成:数据平面和控制平面。数据平面负责处理流量管理,通过 Envoy 的 sidecar 代理来实现流量路由和服务间调用。控制平面是主要由开发者用来配置路由规则和观测指标。
Istio 观测指标是细粒度的属性,其中包含和服务行为相关的特定数据值。下面是个样例:
request.path: xyz/abc
request.size: 234
request.time: 12:34:56.789 04/17/2017
source.ip: [192 168 0 1]
destination.service.name: example
与其他服务网格相比,Istio 胜在其平台成熟度以及通过其 Dashbaord
着重突出的服务行为观测和业务管理功能,然而也因为这些高级特性和复杂的配置流程,Istio 可能并不如其它一些替代方案那样容易上手。
Linkerd
按照官网的说法,Linkerd 是一个轻量级、安全优先的 Kubernetes 服务网格。它的创建流程快到让人难以置信(据称在 Kubernetes 安装只需要 60 秒),这是大多数开发者喜闻乐见的。Linkerd 并没有采用基于 Envoy 的构建方案。而是使用了一个基于 Rust 的高性能代理 linkerd2-proxy,这个代理是专门为 Linkerd 服务网格编写的。
Linkerd 由社区驱动,是 100% 的 Apache 许可开源项目。它还是 CNCF 孵化项目。Linkerd 始于 2016 年,维护者也花了不少时间去解决其中的缺陷。
使用 Linkerd 服务网格,应用服务可以增强其可靠性、可观测性及其在 Kubernetes 上部署的安全性。举个例子,可观测性的增强可以帮助用户解决服务间的延迟问题。使用 Linkerd 不要求用户做很多代码调整或是花费大量时间写 YAML 配置文件。可靠的产品特性和正向的开发者使用回馈,使得 Linkerd 成为服务网格中一个强有力的竞争者。
Consul Connect
Consul Connect 是来自 HashiCorp 的服务网格,专注于路由和分段,通过应用级的 sidecar 代理来提供服务间的网络特性。Consult Connect 侧重于应用安全,提供应用间的双向 TLS 连接以实现授权和加密。
Consult Connect 独特的一点是提供了两种代理模式。一种是它内建的代理,同时它还支持 Envoy 方案。Connect 强调可观测性,集成了例如 Prometheus 这样的工具来监控来自 sidecar 代理的数据。Consul Connect 可以灵活地满足开发者使用需求。比如,它提供了多种方式注册服务:可以从编排系统注册,可以通过配置文件,通过 API 调用,或是命令行工具。
Kuma
Kuma 来源于 Kong,自称是一个非常好用的服务网格替代方案。Kuma 是一个基于 Envoy 的平台无关的控制平面。Kuma 提供了安全、观测、路由等网络特性,同时增强了服务间的连通性。Kuma 同时支持 Kubernetes 和虚拟机。
Kuma 让人感兴趣的一点是,它的企业版可以通过一个统一控制面板来运维管理多个互相隔离独立的服务网格。这项能力可以满足安全要求高的使用场景。既符合隔离的要求,又实现集中控制。
Kuma 也是相对容易安装的一个方案。因为它预先内置了不少策略。这些策略覆盖了常见需求,例如路由,双向 TLS,故障注入,流量控制,加密等场景。
Kuma 原生兼容 Kong,对于那些已经采用 Kong API 管理的企业组织,Kuma 是个非常自然而然的候选方案。
Maesh
Maesh 是来自 Containous 的容器原生的服务网格,标榜自己是比市场其它服务网格更轻量级更易用的方案。和很多基于 Envoy 构建的服务网格不同,Maesh 采用了 Traefik, 一个开源的反向代理和负载均衡器。
Maesh 并没有采用 sidecar 的方式进行代理,而是在每个节点部署一个代理终端。这样做的好处是不需要去编辑 Kubernetes 对象,同时可以让用户有选择性地修改流量,Maesh 相比其他服务网格侵入性更低。Maesh 支持的配置方式:在用户服务对象上添加注解或是在服务网格对象上添加注解来实现配置。
实际上,SMI 是一种新的服务网格规范格式,对 SMI 的支持 Maesh 独有的一大亮点。随着 SMI 在业界逐渐被采用,可以提高可扩展性和减缓供应商绑定的担忧。
Maesh 要求 Kubernetes 1.11 以上的版本,同时集群里安装了 CoreDNS/KubeDNS。这篇安装指南[3]演示了如何通过 Helm v3 快速安装 Maesh。
$ helm repo add maesh https://containous.github.io/maesh/charts
$ helm repo update
$ helm install maesh maesh/maesh
ServiceComb-mesher
Apache 软件基金会形容旗下的 ServiceComb-mesher “是一款用 Go 语言实现的高性能服务网格”。Mesher 基于一个非常受欢迎的 Go 语言微服务开发框架 Go Chassis[4] 来设计实现。因此,它沿袭了 Go Chassis 的一些特性如服务发现、负载均衡、错误容忍、路由管理和分布式追踪等特性。
Mesher 采用了 sidecar 方式;每个服务有一个 Mesher sidecar 代理。开发人员通过 Admin API 和 Mesher 交互,查看运行时信息。Mesher 同时支持 HTTP 和 gRPC,可快速移植到不同的基础设施环境,包括 Docker、Kubernetes、虚拟机和裸金属机环境。
Network Service Mesh(NSM)
Network Service Mesh(NSM)是一款专门为 telcos 和 ISPs 设计的服务网格。它提供了一层级用以增强服务在 Kubernetes 的低层级网络能力。NSM 目前是 CNCF 的沙箱项目。
根据 NSM 的文档说明,“经常接触 L2/L3 层的网络运维人员抱怨说,适合他们的下一代架构的容器网络解决方案几乎没有”。
因此,NSM 在设计时就考虑到一些不同使用场景,尤其是网络协议不同和网络配置混杂的场景。这使得 NSM 对某些特殊场景具备相当吸引力,例如边缘计算、5G 网络和 IOT 设备等场景。NSM 使用简单直接的 API 接口去实现容器和外部端点的之间的通信。
和其他服务网格相比,NSM 工作在另一个不同的网络层。VMware 形容 NSM“专注于连接”。GitHub 的文档[5]演示了 NSM 是如何与 Envoy协同工作的。
AWS App Mesh
AWS APP Mesh 为开发者提供了“适用于不同服务的应用层的网络”。它接管了服务的所有网络流量,使用开源的 Envoy 代理去控制容器的流量出入。AWS App Mesh 支持 HTTP/2 gRPC。
AWS App Mesh 对于那些已经将容器平台深度绑定 AWS 的公司而言,会是相当不错的服务网格方案。AWS 平台包括 AWS Fargate,Amazon Elastic Container Service,Amazon Elastic Kubernetes Service(EKS),Amazon Elastic Compute Cloud(EC2),Kubernetes on EC2,包括 AWS App Mesh 不需要付额外费用。
AWS App Mesh 和 AWS 生态内的监控工具无缝兼容。这些工具包括 CloudWatch 和 AWS X-Ray,以及一些来自第三方供应商的工具。因为 AWS 计算服务支持 AWS Outposts,AWS App Mesh 可以和混合云和已经部署的应用良好兼容。
AWS App Mesh 的缺点可能是使得开发者深度绑定了单一供应商方案,相对闭源,可扩展性缺失。
OpenShift Service Mesh by Red Hat
OpenShift 是来自红帽的一款帮助用户“连接、管理、观测微服务应用”的容器管理平台。OpenShift 预装了不少提升企业能力的组件,也被形容为企业级的混合云 Kubernetes 平台。
OpenShift Service Mesh 基于开源的 Istio 构建,具备 Isito 的控制平面和数据平面等特性。OpenShift 利用两款开源工具来增强 Isito 的追踪能力和可观测性。OpenShift 使用 Jaeger 实现分布式追踪,更好地跟踪请求是如何在服务间调用处理的。
另一方面,OpenShift 使用了 Kiali 来增强微服务配置、流量监控、跟踪分析等方面的可观测性。
如何选择
正如文中所提到的,可供选择的服务网格方案[6]有很多,同时还有新的方案在涌现。当然,每一种方案在技术实现上都略有不同。选择一款合适的服务网格,主要考虑的因素包括,你能接受它带来多大的侵入性,它的安全性如何,以及平台成熟度等。
以下几点可以帮助 DevOps 团队选择一款适合他们场景的服务网格:
- 是否依赖Envoy。Envoy 有一个活跃的社区生态。开源,同时是许多服务网格的底座。Envoy 具备的丰富特性使得其成为一个很难绕过的因素。
- 具体使用场景。服务网格为微服务而生。如果你的应用是一个单体的庞然大物,那你在服务网格上的投入可能达不到预期的收益。如果不是所有应用都部署在 Kubernetes,则应该优先考虑平台无关的方案。
- 现有容器管理平台。有些企业已经使用了特定供应商的生态来解决容器编排问题,例如 AWS 的 EKS,红帽的 OpenShift,Consul。沿袭原有的生态,可以继承并拓展原有的特性。而这些可能是开源方案所不能提供的。
- 所在行业。许多服务网格不是为特定行业专门设计的。Kuma 统一管理多个隔离服务网格的能力可能更适用于收到高度管制的金融行业。底层网络 telcos 和 ISPs 则更应该考虑 Network Service Mesh。
- 对可视化的要求。可观测性是服务网格的核心能力之一。考虑进一步定制和更深度能力的团队应该优先考虑 Istio 或 Consul。
- 是否遵循开发标准。遵循开发标准使得你的平台更具备前瞻性和可扩展性。这使得企业会倾向于采用支持 SMI 的方案,Maesh 或其他基金会孵化的项目如 Linkerd。
- 是否重视用户体验。考虑运维人员的易用性是评判新工具的关键指标。这方 Linkerd 似乎在开发者中间口碑不错。
- 团队准备。评估你的团队所具备的资源和技术储备,在技术选型时决定你们适合用基于 Envoy 的 Istio,或是供应商抽象封装的方案,例如 OpenShift。
这些考虑因素没有覆盖到全部场景。此处仅是抛砖引玉,引起读者的思考。希望读完上面所列的服务网格清单,和相关的决策因素之后,你们的团队能找到新的方法去改善微服务应用的网络特性。
相关链接:
- https://techbeacon.com/app-dev-testing/3-reasons-why-you-should-always-run-microservices-apps-containers
- https://buoyant.io/service-mesh-manifesto/
- https://docs.mae.sh/quickstart/
- https://github.com/go-chassis/go-chassis
- https://github.com/networkservicemesh/examples/tree/master/examples/envoy_interceptor
- https://techbeacon.com/app-dev-testing/make-your-app-architecture-cloud-native-service-mesh
6.3 - (2021)服务网格联网:使用案例、最佳实践和顶级服务网格选择比较
前言
Networking with a service mesh: use cases, best practices, and comparison of top mesh options
作者 Amir Kaushansky
服务网格联网:使用案例、最佳实践和顶级服务网格选择比较
https://cloudnative.to/blog/top-service-mesh-pk/
译者 宋净超(Jimmy Song) 发表于 2021年7月19日
本文译自在 CNCF 官网上发布的博客 Networking with a service mesh: use cases, best practices, and comparison of top mesh options,有删节。作者是 Amir Kaushansky,ARMO 公司的产品 VP。
服务网格技术是随着微服务结构的普及而出现的。由于服务网格促进了网络与业务逻辑的分离,它使你能够专注于你的应用程序的核心竞争力。
微服务应用程序分布在多个服务器、数据中心或大陆上,使它们高度依赖网络。服务网格通过用路由规则和服务间包的动态方向控制流量来管理服务间的网络流量。
在这篇文章中,我们将研究使用案例,比较顶级网格选项,并讨论最佳做法。
让我们从使用服务网格的最常见场景开始。
使用案例
服务网格是一种连接微服务和管理它们之间流量的架构方法。它们在一个组织的许多层面上被大量用于生产。因此,有一些标准化的、被广泛接受的用例。
可观察性
假设你有一个后端服务的实例响应缓慢,在你的整个堆栈中造成了一个瓶颈。然后,来自前端服务的请求将超时,并重新尝试连接到缓慢的服务实例。在服务网格的帮助下,你可以使用一个断路器,确保前端实例只与健康的后端实例连接。因此,使用服务网格可以提高堆栈的可见性,并帮助你排除问题。
部署策略
部署策略(蓝/绿部署、金丝雀等)正在成为发布云原生应用升级的规范。服务网格允许部署策略,因为大多数部署策略都是基于将流量转移到特定实例。例如,你可以在服务网格中创建流量规则,以便只有一小部分用户(比如10%)会接触到新版本。
如果一切按预期进行,你可以将所有流量转移到最新版本,完成你的金丝雀部署。也建议检查Kubernetes的内部部署策略,并与你的应用程序的要求相匹配。
测试
为了保持你的生产堆栈的安全性,最好通过测试延迟、超时和灾难恢复来加固它们。
服务网格允许你通过延迟和不正确的响应在系统中制造混乱来测试其稳健性。例如,通过在服务网格流量规则中注入延迟,你可以测试当你的数据库对其查询响应缓慢时,前端和后端将如何表现。
API网关
API网关是server-client的设计模式,它使得从一个单一的入口点管理API成为可能。在服务网格的帮助下,你可以使用同样的方法进行服务间的通信,并在你的集群中创建复杂的API管理方案。建议你查看Gateway API,以便在即将到来的Kubernetes版本中把这些想法纳入本地Kubernetes资源。
服务网格作为 “智能 “胶水,通过流量策略、限制和测试功能动态地连接微服务。随着服务网格的日益普及,许多新的、被广泛接受的用例将加入上述的用例。
现在让我们来看看现有的顶级服务网格软件的优点和缺点。
顶级网格选项的比较
虽然每次会议上总有一些初创公司推出花哨的服务网格产品,但在云原生世界中,只有三个顶级网格选项被广泛使用。Istio、Linkerd和Consul Connect。它们都是拥有活跃社区的开源产品。基于他们的愿景和实施,他们也都有各自的优点和缺点。
Istio
Istio是一个Kubernetes原生的服务网格,最初由Lyft开发,并在业界被广泛采用。领先的云Kubernetes供应商,如谷歌、IBM和微软,都将Istio作为其服务的默认服务网格。Istio提供了一套强大的功能来创建服务之间的连接,包括请求路由、超时、断路和故障注入。此外,Istio通过延迟、流量和错误等指标对应用程序进行深入了解。
优点
最活跃的社区,业界采用率高,与Kubernetes和虚拟机一起使用。
缺点
学习曲线陡峭,对集群有很大的开销,没有本地管理仪表板。
Linkerd
Linkerd是第二大流行的服务网格,是云原生计算基金会(CNCF)的一部分。
从架构的角度来看,Linkerd类似于Istio,但有更多的灵活性。这种灵活性来自于可插拔架构的多个维度。例如,在连接方面,Linkerd与最流行的入口控制器一起工作,如Nginx、Traefik或Kong。同样,除了它自己的GUI,它还与Grafana、Prometheus和Jaeger合作,以实现可观察性。
优点
文档和简单的安装,在行业中得到采用,和企业支持。
缺点
只适用于Kubernetes,不支持虚拟机缺少一些网络路由功能,如断路或速率限制。
Consul Connect
Consul是分布式应用中最流行的服务发现和键/值存储,直到其母公司HashiCorp以Consul Connect的名义转换为服务网格。
因此,Consul Connect有一个混合架构,在应用程序旁边有Envoy sidecar,其控制平面和键/值存储是用Go开发的。从连接性和安全性的角度来看,Consul Connect与它的替代品相比并没有提供突出的功能。然而,它的配置和复杂性较低,使得它更容易上手–就像云原生世界中的其他HashiCorp工具一样。
优点 有HashiCorp的支持和企业级支持的可用性,可以与虚拟机和Kubernetes一起工作。
缺点
开源社区有限,缺乏完整和易于理解的文档 。
下面的图表提供了这三大解决方案之间关键差异的概述。
| 对比项 | Istio | Linkerd | Consul Connect |
|---|---|---|---|
| 支持的平台 | Kubernetes 和虚拟机 | Kubernetes | Kubernetes 和虚拟机 |
| 支持的 Ingress 控制器 | Istio ingress | 任意 | Envoy |
| 流量管理功能 | 蓝绿部署、断路和速率控制 | 蓝绿部署 | 蓝绿部署、断路和速率控制 |
| Prometheus 和 Grafana 支持 | 是 | 是 | 否 |
| 混沌测试 | 是 | 是 | 否 |
| 管理复杂度 | 高 | 低 | 中 |
| 原生 GUI | 否 | 是 | 是 |
最佳实践和挑战
服务网格使你的集群和应用中的服务间通信标准化和自动化。然而,由于产品的复杂性和基础设施的不同,服务网格产品并不简单。在使用服务网格时,以下关于挑战和最佳实践的说明将为你提供一些有用的指导。
自动化
服务网格的配置包括流量规则、速率限制和网络设置。该配置可以帮助你从头开始安装,升级版本,以及在集群之间迁移。因此,建议把配置当作代码来处理,并遵循GitOps的方法和持续部署管道。
服务网格产品在拥有大量服务器的少数集群中工作得更好,而不是拥有较少实例的许多集群。因此,建议尽可能地减少冗余集群,使你能够利用简单的操作和集中配置的服务网格方法。
监控和请求跟踪
服务网格产品是复杂的应用,管理着更复杂的分布式应用的流量。因此,指标收集、可视化和仪表板对系统的可观察性至关重要。利用Prometheus或Grafana或您的服务网格提供的任何其他集成点,根据您的要求创建警报。
安全性
大多数服务网格产品,包括前三名,都实现了一套基本的安全功能:mTLS、证书管理、认证和授权。你还可以定义和执行网络策略,以限制集群中运行的应用程序之间的通信。
不过,应该注意的是,定义网络策略不是一项简单的任务。你需要覆盖当前运行的应用程序的所有场景,并考虑未来的可扩展性。因此,利用服务网格的网络策略对用户来说并不友好,容易出现错误和安全漏洞。
然而,利用服务网格来创建安全的网络策略有几个缺点。
首先,用户必须准确定义集群所需要的策略——在微服务激增和不断变化的环境中,这是一项不容易的任务。因此,服务网格的策略需要经常改变,如果一个微服务改变其行为,可能会破坏生产。
其次,根据设计,服务网格使用sidecar代理来控制策略,所以任何从容器中出来的连接都会被自动视为合法流量,如果攻击者闯入一个容器,他们会自动继承该容器的网络身份,从而可以做任何原始容器可以做的事情。
最后,由于每个连接都要经过代理,用户在集群中使用它来加密流量时,会看到明显的性能下降。
总结一下:服务网格解决方案并不关心谁在发送或接收数据。只要网络策略允许,任何恶意的或配置错误的应用程序都可以检索你的敏感数据。因此,考虑开销更少、可操作性更强的整体方法至关重要,而不是盲目地只相信服务网格产品的安全措施。
总结
服务网格以动态、安全和可扩展的方式连接分布式微服务。目前有广泛接受的用例和实现这些用例的顶级产品。然而,由于云基础设施和应用需求高度复杂,服务网格不是银弹。
当涉及到安全问题时,保护应用程序和运行时环境不在服务网格产品的范围内,而且仅仅为了安全而安装一个服务网格是矫枉过正的,因为它在集群中产生了很高的开销。
6.4 - (2021)Google Cloud 服务网格: Traffic Director 与 Anthos Service Mesh 的左右互搏
内容出处
Google Cloud 服务网格: Traffic Director 与 Anthos Service Mesh 的左右互搏
作为开源 Service Mesh 明星项目 Istio 背后的主要厂商,Google 也在其公有云上推出了 Service Mesh 管理服务。让人迷惑的是 Google Cloud 上有两个 Service Mesh 产品:Traffic Director 与 Anthos Service Mesh。Google 同时推出两个 Servcie Mesh 产品的原因是什么?这两个产品的定位有何不同?
https://cloudnative.to/blog/20200818-google-cloud-mesh/
作者 赵化冰 发表于 2020年8月26日
作为开源 Service Mesh 明星项目 Istio 背后的主要厂商,Google 也在其公有云上推出了 Service Mesh 管理服务。让人迷惑的是 Google Cloud 上有两个 Service Mesh 产品:Traffic Director 与 Anthos Service Mesh。Google Cloud 首先在2019年3月发布了其第一个 Service Mesh 产品 Traffic Director,随后不久在2019 年9月紧接着发布了另一个 Service Mesh 产品 Anthos Service Mesh,随后两个产品独立并行发展,直到如今。
Google Cloud 同时推出两个 Service Mesh 产品的原因是什么?这两个产品的定位有何不同?本文将分别分析这两个产品的架构和功能,以试图解答该疑问。
Traffic Director
Traffic Director 是 Google Cloud 专为服务网格打造的全托管式流量控制平面,用户不需要对 Traffic Director 进行部署,维护和管理。我们可以把 Traffic Director 看作一个托管的 Pilot(备注:并不确定其内部是否使用的 Pilot),其只提供了流量管理能力,不提供 Istio 控制面的其他能力。用户可以使用 Traffic Director 创建跨区域的、同时支持集群和虚拟机实例的服务网格,并对多个集群和虚拟机的工作负载进行统一的流量控制。Traffic Director 托管控制面 提供了跨地域容灾能力,可以保证99.99%的SLA。
总而言之,Traffic Director 的关键特性包括:
- 全托管控制面
- 控制面高可用
- 同时支持 K8s 集群和虚拟机
- 跨地域的流量管理
Traffic Director 架构
Traffic Director 的总体架构和 Istio 类似,也采用了“控制面 + 数据面”的结构,控制面托管在 Google Cloud 中,对用户不可见。用户只需要在创建 project 时启用 Traffic Director API,即可使用 Traffic Director 提供的网格服务。数据面则采用了和 Istio 相同的 Envoy 作为 proxy。 控制面和数据面采用标准的 xDS v2 进行通信。控制面对外采用了一套自定义的 API 来实现流量管理,并不支持 Istio API。Traffic Director 也没有采用 Istio/K8s 的服务发现,而是采用了一套 Google Cloud 自己的服务注册发现机制,该服务注册发现机制以统一的模型同时支持了容器和虚拟机上的服务,并为工作负载提供了健康检测。
Traffic Director 架构

服务注册发现机制
Traffic Director 采用了 Google Cloud 的一种称为 Backend Service 的服务注册机制。通过 Backend Service 支持了 GKE 集群中容器工作负载和虚拟机工作负载两种方式的服务注册发现,不过和 Istio 不同的是,Traffic Director 并不支持 K8s 原生的服务注册发现机制。
服务注册发现资源模型
Traffic Director 的服务注册发现资源模型如下图所示,图中蓝色的图形为 Traffic Director 中使用的资源,桔色的图形为这些资源对应在 K8s 中的概念。Backend Service 是一个逻辑服务,可以看作 K8s 中的 Service,Backend Service 中可以包含 GKE 集群中的 NEG (Network Endpoint Group),GCE 虚拟机 的 MIG (Managed Instance Group),或者无服务的 NEG 。NEG 中则是具体的一个个工作负载,即服务实例。
Traffic Director 服务发现资源模型

Google Cloud 的这一套服务注册的机制并不只是为 Traffic Director 而定制的,还可以和 Google Cloud 上的各种负载均衡服务一起使用,作为负载均衡的后端。熟悉 K8s 的同学应该清楚,进入 K8s 集群的流量经过 Load Balancer 后会被首先发送到一个 node 的 nodeport 上,然后再通过 DNAT 转发到 Service 后端的一个 Pod IP 上。Google Cloud 在 cluster 上提供了一个 VPC native 的网络特性,可以在 VPC 中直接路由 Pod ,在打开 VPC native 特性的集群中,通过将 NEG 而不是 K8s service 放到 Load balancer 后端,可以跳过 Kubeproxy iptables 转发这一跳,直接将流量发送到 Pod,降低转发延迟,并可以应用更灵活的 LB 和路由算法。
虽然 Backend Service 已经支持了无服务 NEG,但目前 Traffic Director 还不支持,但从资源模型的角度来看,应该很容易扩展目前的功能,以将无服务工作负载加入到服务网格中。
下面举例说明如何创建 Backend Service,并将 GKE 和 VM 中运行的服务实例加入到 Backend Service中,以了解相关资源的内部结构。
注册 GKE 集群中的容器服务
1、 创建 GKE NEG:在 K8s Service 的 yaml 定义中通过 annotation 创建 NEG

2、 创建防火墙规则:需要创建一条防火墙规则,以允许 gcloud 对 GKE NEG 中的服务实例进行健康检查
gcloud compute firewall-rules create fw-allow-health-checks \
--action ALLOW \
--direction INGRESS \
--source-ranges 35.191.0.0/16,130.211.0.0/22 \
--rules tcp
3、创建健康检查
gcloud compute health-checks create http td-gke-health-check \
--use-serving-port
4、创建 Backend Service,创建时需要指定上一步创建的健康检查
gcloud compute backend-services create td-gke-service \
--global \
--health-checks td-gke-health-check \
--load-balancing-scheme INTERNAL_SELF_MANAGED
5、将 GKE NEG 加入到上一步创建的 Backend service 中
NEG_NAME=$(gcloud beta compute network-endpoint-groups list \
| grep service-test | awk '{print $1}')
gcloud compute backend-services add-backend td-gke-service \
--global \
--network-endpoint-group ${NEG_NAME} \
--network-endpoint-group-zone us-central1-a \
--balancing-mode RATE \
--max-rate-per-endpoint 5
注册 GCE 虚拟机服务
1、 创建虚机模版:在创建模版时可以通过命令参数 –service-proxy=enabled 声明使用该模版创建的虚拟机需要安装 Envoy sidecar 代理
gcloud beta compute instance-templates create td-vm-template-auto \
--service-proxy=enabled
2、 创建 MIG:使用虚拟机模版创建一个 managed instance group,该 group 中的实例数为2
gcloud compute instance-groups managed create td-vm-mig-us-central1 \
--zone us-central1-a
--size=2
--template=td-vm-template-auto
3、 创建防火墙规则
gcloud compute firewall-rules create fw-allow-health-checks \
--action ALLOW \
--direction INGRESS \
--source-ranges 35.191.0.0/16,130.211.0.0/22 \
--target-tags td-http-server \
--rules tcp:80
4、 创建健康检查
gcloud compute health-checks create http td-vm-health-check
5、 创建 Backend Service,创建时需要指定上一步创建的健康检查
gcloud compute backend-services create td-vm-service \
--global \
--load-balancing-scheme=INTERNAL_SELF_MANAGED \
--connection-draining-timeout=30s \
--health-checks td-vm-health-check
6、 将 MIG 加入到上一步创建的 Backend service 中
gcloud compute backend-services add-backend td-vm-service \
--instance-group td-demo-hello-world-mig \
--instance-group-zone us-central1-a \
--global
流量管理实现原理
Traffic Diretor 的主要功能就是跨地域的全局流量管理能力,该能力是建立在 Google Cloud 强大的 VPC 机制基础上的, Google Cloud 的 VPC 可以跨越多个 Region,因此一个 VPC 中的服务网格中可以有来自多个 Region 的服务。另外 Traffic Director 并未直接采用 Istio 的 API,而是自定义了一套 API 来对网格中的流量进行管理。
控制面流量规则定义
Traffic Director 流量规则相关的控制面资源模型如下图所示,图中下半部分是 Istio 中和这些资源对应的 CRD。
- Forwarding Rule:定义服务的入口 VIP 和 Port。
- Target Proxy:用于关联 Forwarding Rule 和 URL Map,可以看作网格中代理的一个资源抽象。
- URL Map:用于设置路由规则,包括规则匹配条件和规则动作两部分。匹配条件支持按照 HTTP 的 Host、Path、Header进行匹配。匹配后可以执行 Traffic Splitting、Redirects、URL Rewrites、Traffic Mirroring、Fault Injection、Header Transformation 等动作。
- Backend Service:前面在服务发现中已经介绍了 Backend Service 用于服务发现,其实还可以在 Backen Service 上设置流量策略,包括LB策略,断路器配置,实例离线检测等。可以看到 Backend Service 在 Traffic Director 的流量管理模型中同时承担了 Istio 中的 ServiceEntry 和 Destionation Rule 两个资源等功能。
客户端直接通过 VIP 访问服务其实是一个不太友好的方式,因此我们还需要通过一个 DNS 服务将 Forwarding Rule 中的 VIP 和一个 DNS record 关联起来,在 Google Cloud 中可以采用 Cloud DNS 来将 Forwarding Rule 的 VIP 关联到一个内部的全局 DNS 名称上。
Traffic Director 流量管理资源模型

下面举例说明这些资源的定义,以及它们是如何相互作用,以实现Service Mesh中的流量管理。
下图中的forwarding rule定义了一个暴露在 10.0.0.1:80 上的服务,该服务对应的url map 定义了两条路由规则,对应的主机名分别为 * 和 hello-worold,请求将被路由到后端的 td-vm-service backend service 中的服务实例。

Forwarding Rule 定义

Target Proxy 定义

URL Map 定义

Backend Service 定义

Managed Instance Group 定义

数据面 Sidecar 配置
Traffic Director 将服务发现信息和路由规则转换为 Envoy 配置,通过 xDS 下发到 Envoy sidecar,控制面规则和数据面配置的对应关系下:
Forwarding Rule -> Envoy Listener
URL Map -> Envoy Route
Backend Service -> Envoy Cluster
NEG/MIG -> Envoy endpoint
Listener 配置
Listener 中的 Http Connection Manager filter 配置定义了 IP+Port 层面的入口,这里只接受 Forwarding Rule 中指定的 VIP 10.0.0.1。我们也可以在 Forwarding Rule 中将 VIP 设置为 0.0.0.0,这样的话任何目的 IP 的请求都可以处理。

Route 配置

Cluster 配置

高级流量规则
在 URL Map 中设置 Traffic Splitting
hostRules:
- description: ''
hosts:
- '*'
pathMatcher: matcher1
pathMatchers:
- defaultService: global/backendServices/review1
name: matcher1
routeRules:
- priority: 2
matchRules:
- prefixMatch: ''
routeAction:
weightedBackendServices:
- backendService: global/backendServices/review1
weight: 95
- backendService: global/backendServices/review2
weight: 5
在 Backend Service 中设置 Circuit Breaker
affinityCookieTtlSec: 0
backends:
- balancingMode: UTILIZATION
capacityScaler: 1.0
group:https://www.googleapis.com/compute/v1/projects/<var>PROJECT_ID</var>/zones/<var>ZONE</var>/instanceGroups/<var>INSTANCE_GROUP_NAME</var>
maxUtilization: 0.8
circuitBreakers:
maxConnections: 1000
maxPendingRequests: 200
maxRequests: 1000
maxRequestsPerConnection: 100
maxRetries: 3
connectionDraining:
drainingTimeoutSec: 300
healthChecks:
- https://www.googleapis.com/compute/v1/projects/<var>PROJECT_ID</var>/global/healthChecks/<var>HEALTH_CHECK_NAME</var>
loadBalancingScheme: INTERNAL_SELF_MANAGED
localityLbPolicy: ROUND_ROBIN
name: <var>BACKEND_SERVICE_NAME</var>
port: 80
portName: http
protocol: HTTP
sessionAffinity: NONE
timeoutSec: 30
从这两个规则的定义可以看出,虽然文件结构有所差异,但实际上 Traffic Director yaml 路由规则的定义和 Istio 非常相似。
与 Istio 相比,Traffic Director 的流量管理机制更为灵活,可以在 Mesh 中同时接入 K8s 集群和虚拟机中的工作负载。但 Traffic Director 需要手动进行较多的配置才能对服务进行管理,包括 backend service,forwarding rule,url map 和 DNS,而在 Istio 中,如果不需要进行特殊的路由和流量策略,这些配置都是不需要手动进行的,pilot 会自动创建默认配置。
Sidecar Proxy 部署机制
Traffic Director 数据面采用了和 Istio 相同的机制,通过 Iptables 规则将应用服务的出入流量重定向到 Envoy sidecar,由 Envoy 进行流量路由。Traffic Director 采用了下面的方式来在 K8s 集群的 Pod 或者虚拟机中安装数据面组件。
VM 手动部署
通过脚本从 gcloud 上下载 envoy 二机制,并安装 iptables 流量拦截规则,启动envoy。
# Add a system user to run Envoy binaries. Login is disabled for this user
sudo adduser --system --disabled-login envoy
# Download and extract the Traffic Director tar.gz file
# 下载traffic director相关文件
sudo wget -P /home/envoy https://storage.googleapis.com/traffic-director/traffic-director.tar.gz
sudo tar -xzf /home/envoy/traffic-director.tar.gz -C /home/envoy
#下载 Envoy 的初始化配置,配置中包含了控制面traffic director的地址
sudo wget -O - https://storage.googleapis.com/traffic-director/demo/observability/envoy_stackdriver_trace_config.yaml >> /home/envoy/traffic-director/bootstrap_template.yaml
# 设置iptables流量拦截规则的相关参数
sudo cat << END > /home/envoy/traffic-director/sidecar.env
ENVOY_USER=envoy
# Exclude the proxy user from redirection so that traffic doesn't loop back
# to the proxy
EXCLUDE_ENVOY_USER_FROM_INTERCEPT='true'
# Intercept all traffic by default
SERVICE_CIDR='10.10.10.0/24'
GCP_PROJECT_NUMBER='${GCP_PROJECT_NUMBER}'
VPC_NETWORK_NAME=''
ENVOY_PORT='15001'
ENVOY_ADMIN_PORT='15000'
LOG_DIR='/var/log/envoy/'
LOG_LEVEL='info'
XDS_SERVER_CERT='/etc/ssl/certs/ca-certificates.crt'
TRACING_ENABLED='true'
ACCESSLOG_PATH='/var/log/envoy/access.log'
END
sudo apt-get update -y
sudo apt-get install apt-transport-https ca-certificates curl gnupg2 software-properties-common -y
sudo curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add -
sudo add-apt-repository 'deb [arch=amd64] https://download.docker.com/linux/debian stretch stable' -y
sudo apt-get update -y
sudo apt-get install docker-ce -y
#下载envoy二机制
sudo /home/envoy/traffic-director/pull_envoy.sh
#设置iptables规则,启动envoy
sudo /home/envoy/traffic-director/run.sh start"
VM 自动部署
在创建虚拟机模版时添加注入proxy的参数,可以在VM中自动部署Envoy sidecar。
gcloud beta compute instance-templates create td-vm-template-auto \
--service-proxy=enabled
gcloud compute instance-groups managed create td-vm-mig-us-central1 \
--zone us-central1-a --size=2 --template=td-vm-template-auto
GKE 通过 deployment 部署
GKE 提供 yaml 模版,需要修改 deployment 文件,在 yaml 中增加 sidecar 相关的镜像。未提供 webhook,参见 Traffic Director 的示例文件。
VM和GKE混合部署示例
下面我们创建一个示例程序,将 V 和 GKE 中的服务同时加入到 traffic director 管理的 service mesh 中,以展示 traffic director 的对 VM 和容器服务流量统一管理能力。 该程序的组成如下图所示。程序中部署了三个服务,在 us-central1-a 中部署了两个 VM MIG 服务,在 us-west1-a 中部署了一个 GKE NEG 服务,这三个服务处于同一个 VPC 中,因此网络是互通的。

通过 us-central1-a region 上的客户端向三个服务分别发送请求。
echo Access service in VM managed instance group td-demo-hello-world-mig
echo
for i in {1..4}
do
curl http://10.0.0.1
sleep 1
done
echo
echo Access service in VM managed instance group td-observability-service-vm-mig
echo
for i in {1..4}
do
curl http://10.10.10.10
sleep 1
done
echo
echo Access service in GKE network endpoint group k8s1-e403ff53-default-service-test-80-e849f707
echo
for i in {1..4}
do
curl http://10.0.0.2
echo
sleep 1
done
服务端会在请求响应消息中打印自身的 host name。我们从客户端循环访问三个服务,从命令结果可见每次的输出是不同的,这是因为 envoy 会通过缺省 lb 算法将请求分发到不同的服务实例上。
Access service in VM managed instance group td-demo-hello-world-mig
<!doctype html><html><body><h1>td-demo-hello-world-mig-ccx4</h1></body></html>
<!doctype html><html><body><h1>td-demo-hello-world-mig-658w</h1></body></html>
<!doctype html><html><body><h1>td-demo-hello-world-mig-ccx4</h1></body></html>
<!doctype html><html><body><h1>td-demo-hello-world-mig-658w</h1></body></html>
Access service in VM managed instance group td-observability-service-vm-mig
<!doctype html><html><body><h1>td-observability-service-vm-mig-50tq</h1></body></html>
<!doctype html><html><body><h1>td-observability-service-vm-mig-16pr</h1></body></html>
<!doctype html><html><body><h1>td-observability-service-vm-mig-50tq</h1></body></html>
<!doctype html><html><body><h1>td-observability-service-vm-mig-16pr</h1></body></html>
Access service in GKE network endpoint group k8s1-e403ff53-default-service-test-80-e849f707
app1-84996668df-dlccn
app1-84996668df-t4qmn
app1-84996668df-dlccn
app1-84996668df-t4qmn
Anthos Service Mesh
Anthos Service Mesh 是 Google 混合云和多云解决方案 Anthos 中负责服务管理的部分。和 Traffic Director 的主要区别是,Anthos Service Mesh 直接采用了开源 Istio, 并且未对控制面进行托管,而是将 Istio 控制面部署在了用户集群中,只是将遥测信息接入了 Google Cloud,并在 Google cloud console 的 Anthos Service Mesh 界面中提供了服务网格的查看和监控界面。 Anthos Service Mesh关键特性包括:
- 原生Istio多集群方案
- 支持多云/混合云(不支持虚机)
- 集中的服务监控控制台。
Anthos 的整体架构
Google Cloud Anthos 旨在提供一个跨越 Google Cloud、私有云和其他公有云的统一解决方案,为客户在混合云/多云环境下的集群和应用管理提供一致的体验。Anthos 包含了统一的 GKE 集群管理,服务管理和配置管理三大部分功能。其中 Anthos Service Mesh 负责其中统一的服务管理部分,可以将部署在多个不同云环境中的 Istio 集群在 Anthos Service Mesh 控制台中进行统一的管理和监控。
Anthos 架构

Anthos GKE 集群管理
Anthos 对 On-Perm 和多云的 K8s 集群的管理采用了代理的方式,Anthos 会在每个加入 Anthos 的集群中安装一个 agent,由 agent 主动建立一个到 Anthos 控制面的连接,以穿透 NAT,连接建立后,Anthos 控制面会连接集群的 API Server,对集群进查看和行管理。
Anthos 采用 agent 接入 K8s 集群

Anthos Service Mesh 的混合云/多云解决方案
由于采用了开源 Istio,因此 Anthos Service Mesh 的混合云/多云解决方案实际上采用的是 Istio 的多集群方案。Istio 自身的多集群方案是非常灵活的,根据网络模式和控制面的安装模式,可以有多种灵活的搭配组合。Anthos Service Mesh 中推荐使用的是多控制面方案。
多网络多控制平面
该方案中多个集群在不同网络中,不同集群中的 Pod IP 之间是不能通过路由互通的,只能通过网关进行访问。即使在不同集群中部署相同的服务,对远端集群中服务的访问方式也和本地服务不同,即不能采用同一服务名来访问不同集群中的相同服务,因此无法实现跨集群/地域的负载均衡或容灾。
由于上诉特点,多网络多控制平面的部署方案一般用于需要隔离不同服务的场景,如下图所示,通常会在不同集群中部署不同的服务,跨集群进行服务调用时通过 Ingress Gateway 进行。
Anthos Service Mesh 多集群管理-多网络多控制平面

单网络多控制平面
在该方案中,多个集群处于同一个扁平三层网络之中,各个集群中的服务可以直接相互访问。如下图所示,两个集群中的 Istio 控制面都通过访问对方的 API server 拿到了对方的服务信息。在这种场景中,通常会在不同集群中部署相同的服务,以实现跨地域的负载均衡和容灾。
如图中箭头所示,在正常情况下,每个 region 中的服务只会访问自己 region 中的其他服务,以避免跨 region 调用导致时延较长,影响用户体验。当左边 region 中的 ratings 服务由于故障不能访问时,reviews 服务会通过 Istio 提供的 Locality Load Balancing 能力访问右侧 region 中的 ratings 服务,以实现跨 region 的容灾,避免服务中断。
Anthos Service Mesh 多集群管理-单网络多控制平面

Anthos Service Mesh 多集群部署示例
对于 Istio 来讲,其管理的 Mesh 中的多个集群是否跨云/混合云并不影响集群管理的部署方案,因为本质上都是同一网络/多个网络两种情况下的多集群管理。本示例的两个集群都使用了 GKE 的 Cluster。但只要把网络打通,本示例也适用于跨云/混合云的情况。
本示例的部署如图“单网络多控制面“所示,在同一个 VPC 中的两个 region 中部署了两个 GKE cluster。部署时需要注意几点:
- 需要将 cluster 的网络方案设置为 vpc-native,这样 pod ip 在 vpc 中就是可以路由的,以让两个 cluster 的网络可以互通。
- 需要为两个 cluster 中部署的 Istio 控制面设置对方 api server 的 remote secret,以使 stio 获取对方的 Service 信息。
具体的安装步骤可以参见 Anthos Service Mesh 的帮助文档。
从导出的 Envoy sidecar 配置可以看到,其连接的 xds server 为本地集群中的 istiod。
"cluster_name": "xds-grpc",
"endpoints": [
{
"lb_endpoints": [
{
"endpoint": {
"address": {
"socket_address": {
"address": "istiod.istio-system.svc",
"port_value": 15012
}
}
}
}
]
}
]
Metric,Access log和 tracing 过 Envoy stackdriver http filter 上报到 Google Cloud,以便通过 Anthos Service Mesh 控制台统一查看。
"name": "istio.stackdriver",
"typed_config": {
"@type": "type.googleapis.com/udpa.type.v1.TypedStruct",
"type_url": "type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm",
"value": {
"config": {
"root_id": "stackdriver_outbound",
"vm_config": {
"vm_id": "stackdriver_outbound",
"runtime": "envoy.wasm.runtime.null",
"code": {
"local": {
"inline_string": "envoy.wasm.null.stackdriver"
}
}
},
"configuration": "{\"enable_mesh_edges_reporting\": true, \"disable_server_access_logging\": false, \"meshEdgesReportingDuration\": \"600s\"}\n"
}
}
}
尝试从位于 west1-a Region 集群的 sleep pod 中访问 helloworld 服务,可以看到缺省会访问本集群中的 helloword v1 版本的服务实例,不会跨地域访问。
g********@cloudshell:~ (huabingzhao-anthos)$
export CTX1=gke_huabingzhao-anthos_us-west1-a_anthos-mesh-cluster-1
for i in {1..4}
> do
> kubectl exec --context=${CTX1} -it -n sample -c sleep \
> $(kubectl get pod --context=${CTX1} -n sample -l \
> app=sleep -o jsonpath='{.items[0].metadata.name}') \
> -- curl helloworld.sample:5000/hello
> done
Hello version: v1, instance: helloworld-v1-578dd69f69-c2fmz
Hello version: v1, instance: helloworld-v1-578dd69f69-c2fmz
Hello version: v1, instance: helloworld-v1-578dd69f69-c2fmz
Hello version: v1, instance: helloworld-v1-578dd69f69-c2fmz
将 west1-a 集群中 helloworld deployment 的副本数设置为0,再进行访问,由于本地没有可用实例,会访问到部署在 east1-b region 的 helloworld v2,实现了跨地域的容灾。这里需要注意一点:虽然两个集群的 IP 是可路由的,但 Google cloud 的防火墙缺省并不允许集群之间相互访问,需要先创建相应的防火墙规则,以允许跨集群的网格访问流量。
kubectl edit deployment helloworld-v1 -nsample --context=${CTX1}
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2020-08-14T12:00:32Z"
generation: 2
labels:
version: v1
name: helloworld-v1
namespace: sample
resourceVersion: "54763"
selfLink: /apis/apps/v1/namespaces/sample/deployments/helloworld-v1
uid: d6c79e00-e62d-411a-8986-25513d805eeb
spec:
progressDeadlineSeconds: 600
replicas: 0
revisionHistoryLimit: 10
selector:
matchLabels:
app: helloworld
version: v1
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
......
g********@cloudshell:~ (huabingzhao-anthos)$ for i in {1..4}
> do
> kubectl exec --context=${CTX1} -it -n sample -c sleep \
> $(kubectl get pod --context=${CTX1} -n sample -l \
> app=sleep -o jsonpath='{.items[0].metadata.name}') \
> -- curl helloworld.sample:5000/hello
> done
Hello version: v2, instance: helloworld-v2-776f74c475-jws5r
Hello version: v2, instance: helloworld-v2-776f74c475-jws5r
Hello version: v2, instance: helloworld-v2-776f74c475-jws5r
Hello version: v2, instance: helloworld-v2-776f74c475-jws5r
相互竞争还是优势互补?
从前面的分析可以看出, Google Cloud 推出的 Traffic Director 和 Anthos Service Mesh 这两个服务网格的产品各有侧重点:
- Traffic Director 关注重点为流量管理。依靠 Google Cloud 强大的网络能力提供了跨区域的 Mesh 流量管理,支持本地服务出现问题时将流量导向另一个地域的相同服务,以避免用户业务中断;并且通过统一的服务发现机制实现了 K8s 集群和虚拟机的混合部署。
- Anthos Service Mesh 关注重点为跨云/多云的统一管理。这是出于用户业务部署的实际环境和业务向云迁移的较长过程的实际考虑,但目前未支持虚拟机,并且其对于 Mesh 中全局流量的管理能力不如 Traffic Director 这样强大。
由于目的不同,两者在控制面也采用不同的实现方案。由于 Traffic Director 只需要支持 Google Cloud,处于一个可控的网络环境中,因此采用托管的自定义控制面实现,并对接了 Google Cloud 上的服务发现机制;而 Anthos Service Mesh 考虑到多云/混合云场景下复杂的网络环境和部署限制,采用了开源 Istio 的多控制面方案,在每个集群中都单独安装了一个 Istio,只是接入了 Google Cloud 的遥测数据,以对网格中的服务进行统一监控。
虽然 Traffic Director 和 Anthos Service Mesh 两者都是 Google Cloud 上的 Service Mesh 产品,似乎存在竞争关系,但从两者的功能和定位可以看出,这两个产品其实是互补的,可以结合两者以形成一个比较完善的 Service Mesh 托管解决方案。因此 Google Cloud 会对两个产品持续进行整合。下图为 Traffic Director Road Map 中 Anthos 和 Istio 的整合计划。

参考文档
6.5 - (2021)服务网格比较: Istio 与 Linkerd
内容出处
Service Mesh Comparison: Istio vs Linkerd
https://dzone.com/articles/service-mesh-comparison-istio-vs-linkerd
作者 Anjul Sahu 服务网格比较: Istio 与 Linkerd
https://cloudnative.to/blog/service-mesh-comparison-istio-vs-linkerd/
译者 张晓辉 发表于 2021年1月25日
根据 CNCF 的最新年度调查,很明显,很多人对在他们的项目中使用服务网格表现出了极大的兴趣,并且许多人已经在他们的生产中使用它们。将近 69% 的人正在评估 Istio,64% 的人正在研究 Linkerd。Linkerd 是市场上第一个服务网格,但是 Istio 的服务网格更受欢迎。这两个项目都是最前沿的,而且竞争非常激烈,因此选择哪一个是一个艰难的选择。在此博客文章中,我们将了解有关 Istio 和 Linkerd 的架构,其及组件的更多信息,并比较其特性以帮你做出明智的决定。
服务网格简介
在过去的几年中,微服务架构已经成为设计软件应用程序的流行风格。在这种架构中,我们将应用程序分解为可独立部署的服务。这些服务通常是轻量级的、多语言的,并且通常由各种职能团队进行管理。直到这些服务的数量变得庞大且难以管理之前,这种架构风格效果很好。突然之间,它们不再简单了。这在管理各个方面(例如安全性、网络流量控制和可观察性)带来了挑战。服务网格可以帮助应对这些挑战。
术语服务网格用于描述组成此类应用程序的微服务网络及其之间的交互。随着服务数量和复杂性的增加,其扩展和管理变得越来越困难。服务通常提供服务发现、负载均衡、故障恢复、指标和监控。服务网格通常还具有更复杂的操作要求,例如A/B测试、金丝雀发布、限流、访问控制和端到端身份验证。服务网格为负载均衡、服务到服务的身份验证、监控等提供了一种创建服务网络的简单方法,同时对服务代码的更改很少或没有更改。
让我们看一下 Istio 和 Linkerd 的架构。请注意,这两个项目都在快速演进,并且本文基于 Istio 1.6 版本和 Linkerd 2.7 版本。
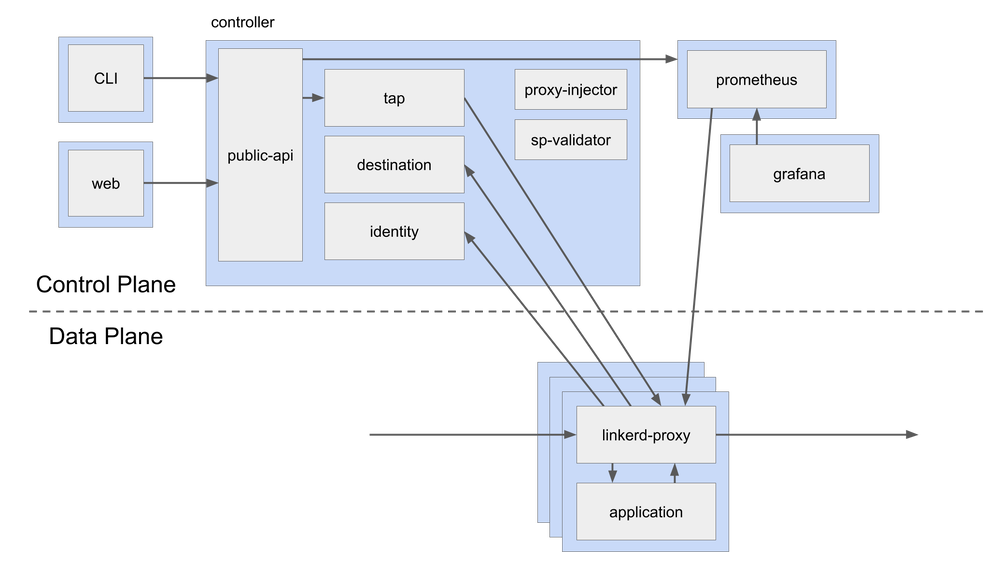
Istio
Istio 是一个提供了作为服务网格的整套解决方案的开源平台,提供了安全、连接和监控微服务的统一方法。它得到了 IBM、Google 和 Lyft 等行业领军者的支持。Istio 是最流行、最完善的解决方案之一,其高级特性适用于各种规模的企业。它是 Kubernetes 的一等公民,被设计成模块化、平台无关的系统。有关 Istio 的快速演示,请参考我们以前的文章。
架构

Istio架构来源:istio.io
组件
Envoy 是由 Lyft 用 C++ 编写的高性能代理,它可以协调服务网格中所有服务的所有入站和出站流量。它作为 Sidecar 代理与服务一起部署。
Envoy提供以下功能:
- 动态服务发现
- 负载均衡
- TLS 终止
- HTTP/2 和 gRPC 代理
- 断路器
- 健康检查
- 按百分比分配流量实现的分阶段发布
- 故障注入
- 丰富的指标
在较新的 Istio 版本中,Sidecar 代理对 Mixer 的工作承担了额外的责任。在早期版本的 Istio(<1.6)中,使用 Mixer 从网格收集遥测信息。
Pilot 为 Sidecar 代理提供服务发现、流量管理功能和弹性。它将控制流量行为的高级路由规则转换为 Envoy 的特定配置。
Citadel 通过内置的身份和凭证管理实现了强大的服务到服务和最终用户身份验证。它可以在网格中启用授权和零信任安全性。
Galley 是 Istio 配置验证、提取、处理和分发组件。
核心功能
- 流量管理 — 智能流量路由规则、流量控制和服务级别属性(如断路器、超时和重试)的管理。它使我们能够轻松设置 A/B测试、金丝雀发布和并按比例分配流量的分阶段发布。
- 安全性 — 在服务之间提供安全的通信通道,并管理大规模身份验证、授权和加密。
- 可观察性 — 强大的链路跟踪、监控和日志功能提供了深度洞察(deep insights)和可见性。它有助于有效地检测和解决问题。
Istio 还具有一个附加组件基础结构服务,该服务支持对微服务的监控。Istio 与 Prometheus、Grafana、Jaeger 和服务网格仪表盘 Kiali 等应用程序集成。
Linkerd
Linkerd 是 Buoyant 为 Kubernetes 设计的开源超轻量级的服务网格。用 Rust 完全重写以使其超轻量级和高性能,它提供运行时调试、可观察性、可靠性和安全性,而无需在分布式应用中更改代码。
架构
Linkerd 具有三个组件 — UI、数据平面和控制平面。它通过在每个服务实例旁边安装轻量级透明代理来工作。
控制平面
Linkerd 的控制平面是一组提供了服务网格的核心功能的服务。它聚合了遥测数据、提供面向用户的 API,并为数据平面代理提供控制数据。以下是控制平面的组件:
- 控制器 — 它包含一个公共 API 容器,该容器为 CLI 和仪表盘提供 API。
- 目标 — 数据平面中的每个代理都将访问此组件以查找将请求发送到的位置。它有用于每个路由指标、重试和超时的服务描述信息。
- 身份 — 它提供了一个证书颁发机构,该证书颁发机构接受来自代理的 CSR 并返回以正确身份签发的证书。它提供了 mTLS 功能。
- 代理注入器 — 它是一个准入控制器,用于查找注解(
linkerd.io/inject: enabled)并更改 pod 规范以添加initContainer和包含代理本身的 sidecar。 - 服务配置文件验证器 — 这也是一个准入控制器,用于在保存新服务描述之前对其进行验证。
- Tap — 它从 CLI 或仪表盘接收实时监控请求和响应的指令,以在应用程序中提供可观察性。
- Web — 提供 Web 仪表盘。
- Grafana — Linkerd 通过 Grafana 提供开箱即用的仪表盘。
- Prometheus — 通过
/metrics在端口 4191 上代理的断点来收集和存储所有 Linkerd 指标。
数据平面
Linkerd 数据平面由轻量级代理组成,这些轻量级代理作为边车容器与服务容器的每个实例一起部署。在具有特定注解的 Pod 的初始化阶段,将代理注入(请参见上面的代理注入器)。自从 2.x 由 Rust 中完全重写以来,该代理一直非常轻量级和高性能。这些代理拦截与每个 Pod 之间的通信,以提供检测和加密(TLS),而无需更改应用程序代码。
代理功能:
- HTTP、HTTP/2和任意 TCP 协议的透明、零配置代理。
- 自动为 HTTP 和 TCP 流量导出 Prometheus 指标。
- 透明的零配置 WebSocket 代理。
- 自动的、可感知延迟的 7 层负载均衡。
- 非 HTTP 流量的自动的 4 层负载均衡。
- 按需诊断 tap API。
比较
| 特点 | Istio | Linkerd |
|---|---|---|
| 易于安装 | 由于各种配置选项和灵活性,对于团队来说可能不堪重负。 | 因为有内置和开箱即用的配置,适配起来是相对容易的 |
| 平台 | Kubernetes、虚拟机 | Kubernetes |
| 支持的协议 | gRPC、HTTP/2、HTTP/1.x、Websocket 和所有 TCP 流量。 | gRPC、HTTP/2、HTTP/1.x、Websocket 和所有 TCP 流量。 |
| 入口控制器 | Envoy,Istio 网关本身。 | 任何 – Linkerd 本身不提供入口功能。 |
| 多集群网格和扩展支持 | 通过各种配置选项以及在 Kubernetes 集群外部扩展网格的稳定版本支持多集群部署。 | 2.7 版本,多群集部署仍处于试验阶段。根据最新版本 2.8,多群集部署是稳定的。 |
| 服务网格接口(SMI)兼容性 | 通过第三方 CRD。 | 原生的流量拆分和指标,而不用于流量访问控制。 |
| 监控功能 | 功能丰富 | 功能丰富 |
| 追踪支持 | Jaeger、Zipkin | 所有支持 OpenCensus 的后端 |
| 路由功能 | 各种负载均衡算法(轮训、随机最少连接),支持基于百分比的流量拆分,支持基于标头和路径的流量拆分。 | 支持 EWMA(指数加权移动平均)负载均衡算法,通过 SNI 支持基于百分比的流量拆分。 |
| 弹性 | 断路、重试和超时、故障注入、延迟注入。 | 无断路、无延迟注入支持。 |
| 安全 | mTLS支持所有协议、可以使用外部 CA 证书/密钥、支持授权规则。 | 除了 TCP 之外,还支持 mTLS,可以使用外部 CA/密钥,但尚不支持授权规则。 |
| 性能 | 在最新的 1.6 版本中,Istio 的资源占用越来越好并且延迟得到了改善。 | Linkerd 的设计非常轻巧 - 根据第三方基准测试,它比 Istio 快 3-5 倍。 |
| 企业支援 | 不适用于 OSS 版本。如果您将 Google 的 GKE 与 Istio 一起使用,或者将 Red Hat OpenShift 与 Istio 作为服务网格使用,则可能会得到各个供应商的支持。 | 开发了 Linkerd OSS 版本的 Buoyant 提供了完整的企业级工程、支持和培训。 |
结论
服务网格正成为云原生解决方案和微服务架构中必不可少的组成部分。它完成了所有繁重的工作,例如流量管理、弹性和可观察性,让开发人员专注于业务逻辑。Istio 和 Linkerd 都已经成熟,并已被多家企业用于生产。对需求的计划和分析对于选择要使用哪个服务网格至关重要。请在分析阶段投入足够的时间,因为在游戏的后期从一个迁移到另一个很复杂。
选择与服务网格一样复杂和关键的技术时,不仅要考虑技术,还要考虑使用技术的背景。缺少背景,很难说 A 是否比 B 好,因为答案确实是“取决于”。我喜欢 Linkerd 的简单,包括入门和以后管理服务网格。此外,多年来,Linkerd 与来自企业公司的用户一起得到了加强。
一个中可能有一些功能看起来不错,但请确保检查另一个是否计划在不久的将来发布该功能,并基于不仅是理论上的评估,而且还要在概念验证沙箱中对它们进行尝试,做出明智的决定。这种概念验证应集中在易用性、功能匹配以及更重要的是技术的操作方面。引入技术相对容易,最困难的部分是在其生命周期中运行和管理它。
请让我们知道你的想法和意见。
参考文献
7 - Servicemesh的问题
7.1 - (2021)在生产环境使用 Istio 前的若干考虑要素
内容出处
在生产环境使用 Istio 前的若干考虑要素
深度落地 Istio 两年的若干思考。
https://cloudnative.to/blog/the-facts-of-using-istio/
作者 陈鹏 发表于 2021年2月25日
前言
2021 年伊始,如果你想要在生产环境中落地 Service Mesh,那 Istio 一定已经在你的考虑范围之内。
Istio 作为目前最流行的 Service Mesh 技术之一,拥有活跃的社区和众多的落地案例。但如果你真的想在你的生产环境大规模落地 Isito,这看似壮观美好的冰山下,却是暗流涌动,潜藏着无数凶险。
本文是笔者深度参与百亿量级流量生产环境研发和落地 Istio 两年来的经验总结和一些思考,以期读者在自己生产环境引入 Isito 前,能有所参考和启发,做好更充足的准备,能更轻松的“入坑” Istio。
如果你对 Service Mesh 的概念还不甚了解,可先行阅读《云原生时代,你应该了解的 Service Mesh》。
使用 Isito 前的考虑要素
使用 Istio 无法做到完全对应用透明
服务通信和治理相关的功能迁移到 Sidecar 进程中后, 应用中的 SDK 通常需要作出一些对应的改变。
比如 SDK 需要关闭一些功能,例如重试。一个典型的场景是,SDK 重试 m 次,Sidecar 重试 n 次,这会导致 m * n 的重试风暴,从而引发风险。
此外,诸如 trace header 的透传,也需要 SDK 进行升级改造。如果你的 SDK 中还有其它特殊逻辑和功能,这些可能都需要小心处理才能和 Isito Sidecar 完美配合。
Istio 对非 Kubernetes 环境的支持有限
在业务迁移至 Istio 的同时,可能并没有同步迁移至 Kubernetes,而还运行在原有 PAAS 系统之上。 这会带来一系列挑战:
- 原有 PAAS 可能没有容器网络,Istio 的服务发现和流量劫持都可能要根据旧有基础设施进行适配才能正常工作
- 如果旧有的 PAAS 单个实例不能很好的管理多个容器(类比 Kubernetes 的 Pod 和 Container 概念),大量 Istio Sidecar 的部署和运维将是一个很大的挑战
- 缺少 Kubernetes webhook 机制,Sidecar 的注入也可能变得不那么透明,而需要耦合在业务的部署逻辑中
只有 HTTP 协议是一等公民
Istio 原生对 HTTP 协议提供了完善的全功能支持,但在真实的业务场景中,私有化协议却非常普遍,而 Istio 却并未提供原生支持。
这导致使用私有协议的一些服务可能只能被迫使用 TCP 协议来进行基本的请求路由,这会导致很多功能的缺失,这其中包括 Istio 非常强大的基于内容的消息路由,如基于 header、 path 等进行权重路由。
扩展 Istio 的成本并不低
虽然 Istio 的总体架构是基于高度可扩展而设计,但由于整个 Istio 系统较为复杂,如果你对 Istio 进行过真实的扩展,就会发现成本不低。
以扩展 Istio 支持某一种私有协议为例,首先你需要在 Istio 的 api 代码库中进行协议扩展,其次你需要修改 Istio 代码库来实现新的协议处理和下发,然后你还需要修改 xds 代码库的协议,最后你还要在 Envoy 中实现相应的 Filter 来完成协议的解析和路由等功能。
在这个过程中,你还可能面临上述数个复杂代码库的编译等工程挑战(如果你的研发环境不能很好的使用 Docker 或者无法访问部分国外网络的情况下)。
即使做完了所有的这些工作,你也可能面临这些工作无法合并回社区的情况,社区对私有协议的扩展支持度不高,这会导致你的代码和社区割裂,为后续的升级更新带来隐患。
Istio 在集群规模较大时的性能问题
Istio 默认的工作模式下,每个 Sidecar 都会收到全集群所有服务的信息。如果你部署过 Istio 官方的 Bookinfo 示例应用,并使用 Envoy 的 config dump 接口进行观察,你会发现,仅仅几个服务,Envoy 所收到的配置信息就有将近 20w 行。
可以想象,在稍大一些的集群规模,Envoy 的内存开销、Istio 的 CPU 开销、XDS 的下发时效性等问题,一定会变得尤为突出。
Istio 这么做一是考虑这样可以开箱即用,用户不用进行过多的配置,另外在一些场景,可能也无法梳理出准确的服务之间的调用关系,因此直接给每个 Sidecar 下发了全量的服务配置,即使这个 Sidecar 只会访问其中很小一部分服务。
当然这个问题也有解法,你可以通过 Sidecar CRD 来显示定义服务调用关系,使 Envoy 只得到他需要的服务信息,从而大幅降低 Envoy 的资源开销,但前提是在你的业务线中能梳理出这些调用关系。
XDS 分发没有分级发布机制
当你对一个服务的策略配置进行变更的时候,XDS 不具备分级发布的能力,所有访问这个服务的 Envoy 都会立即收到变更后的最新配置。这在一些对变更敏感的严苛生产环境,可能是有很高风险甚至不被允许的。
如果你的生产环境严格要求任何变更都必须有分级发布流程,那你可能需要考虑自己实现一套这样的机制。
Istio 组件故障时是否有退路?
以 Istio 为代表的 Sidecar 架构的特殊性在于,Sidecar 直接承接了业务流量,而不像一些其他的基础设施那样,只是整个系统的旁路组件(比如 Kubernetes)。
因此在 Isito 落地初期,你必须考虑,如果 Sidecar 进程挂掉,服务怎么办?是否有退路?是否能 fallback 到直连模式?
在 Istio 落地过程中,是否能无损 fallback,通常决定了核心业务能否接入 Service Mesh。
Isito 技术架构的成熟度还没有达到预期
虽然 Istio 1.0 版本已经发布了很久,但是如果你关注社区每个版本的迭代,就会发现,Istio 目前架构依然处于不太稳定的状态,尤其是 1.5 版本前后的几个大版本,先后经历了去除 Mixer 组件、合并为单体架构、仅支持高版本 Kubernetes 等等重大变动,这对于已经在生产环境中使用了 Istio 的用户非常不友好,因为升级会面临各种不兼容性问题。
好在社区也已经意识到这一问题,2021 年社区也成立了专门的小组,重点改善 Istio 的兼容性和用户体验。
Istio 缺乏成熟的产品生态
Istio 作为一套技术方案,却并不是一套产品方案。
如果你在生产环境中使用,你可能还需要解决可视化界面、权限和账号系统对接、结合公司已有技术组件和产品生态等问题,仅仅通过命令行来使用,可能并不能满足你的组织对权限、审计、易用性的要求。
而 Isito 自带的 Kiali 功能还十分简陋,远远没有达到能在生产环境使用的程度,因此你可能需要研发基于 Isito 的上层产品。
Istio 目前解决的问题域还很有限
Istio 目前主要解决的是分布式系统之间服务调用的问题,但还有一些分布式系统的复杂语义和功能并未纳入到 Istio 的 Sidecar 运行时之中,比如消息发布和订阅、状态管理、资源绑定等等。
云原生应用将会朝着多 Sidecar 运行时或将更多分布式能力纳入单 Sidecar 运行时的方向继续发展,以使服务本身变得更为轻量,让应用和基础架构彻底解耦。
如果你的生产环境中,业务系统对接了非常多和复杂的分布式系系统中间件,Istio 目前可能并不能完全解决你的应用的云原生化诉求。
写在最后
看到这里,你是否感到有些沮丧,而对 Isito 失去信心?
别担心,上面列举的这些问题,实际上并不影响 Isito 依然是目前最为流行和成功的 Service Mesh 技术选型之一。Istio 频繁的变动,一定程度上也说明它拥有一个活跃的社区,我们应当对一个新的事物报以信心,Isito 的社区也在不断听取来自终端用户的声音,朝着大家期待的方向演进。
同时,如果你的生产环境中的服务规模并不是很大,服务已经托管于 Kubernetes 之上,也只使用那些 Istio 原生提供的能力,那么 Istio 依然是一个值得尝试的开箱即用方案。
但如果你的生产环境比较复杂,技术债务较重,专有功能和策略需求较多,亦或者服务规模庞大,那么在开始使用 Istio 之前,你需要仔细权衡上述这些要素,以评估在你的系统之中引入 Istio 可能带来的复杂度和潜在成本。
7.2 - (2021)不必要的复杂性如何给服务网带来恶名
内容出处
How Unnecessary Complexity Gave the Service Mesh a Bad Name
https://www.infoq.com/articles/service-mesh-unnecessary-complexity
作者 Chris Campbell 发表于 2021年2月25日
低复杂度 - 服务网格的下一站
https://atbug.com/service-mesh-unnecessary-complexity/
翻译 张晓辉
译者:
作为一个曾经在制造业企业的基础架构团队任职,为支持公司的“互联网基因”和“数字化转型”落地了云原生基础设施平台,并在尝试采用服务网格未成的我来说,看到这篇文章深有感触。尤其是文中所说的“人少,问题多,需要快速输出价值”,直戳到了痛处。有限的人手有限的时间,我们需要将大部分精力集中在解决成熟度曲线较低的基本问题上,要想很好的运行复杂的系统是非常困难的。
服务网格是一个新的基础设施层,可以承载很多的功能,未来还会有更大的想象空间和光明的未来。
以上的种种原因,也促使我后来选择进入一家提供服务网格的产品企业,也希望服务网格可以被更简单的使用。
“道阻且长,行则将至!”
本文翻译自 Chris Campbell 的 How Unnecessary Complexity Gave the Service Mesh a Bad Name
关键要点
- 采用服务网格有巨大的价值,但必须以轻量级的方式进行,以避免不必要的复杂性。
- 在实施服务网时,要采取务实的方法,与技术的核心功能保持一致,并小心干扰(译者:注意力的分散)。
- 服务网格的一些核心特性包括标准化监控、自动加密和身份识别、智能路由、可靠的重试和网络可扩展性。
- 服务网格可以提供强大的功能,但这些功能会分散本应对核心优势的关注,并且这些功能也不是实施服务网格的主要原因。
- 在初始实施服务网格时没有必要去关注那些明显会分散注意力的功能,比如复杂的控制平面、多集群支持、Envoy、WASM 和 A/B 测试。
服务网格是 Kubernetes 世界中的一个热门话题,但许多潜在的采用者已经有些失望了。服务网格的落地受到压倒性的复杂性和看似无穷无尽的供应商解决方案的限制。在我亲自浏览了这个领域之后,我发现采用服务网格具有巨大的价值,但它必须以轻量级的方式完成,以避免不必要的复杂性。尽管普遍存在幻灭感,但服务网格的未来依然光明。
在工作中学习
我进入服务网格的世界始于我在一家老牌的财富 500 强技术公司担任云计算架构师的角色。在开始我们的服务网格之旅时,我身边有许多强大的工程师,但大多数人几乎没有云计算开发经验。我们的组织诞生于云计算之前,完全实现云计算的价值需要时间。我们的传统业务线主要集中在技术栈的硬件元素上,云计算的决策最初是由为运送硬件或为该硬件提供固件和驱动程序而开发的流程驱动的。
随着该组织经历其“数字化转型”,它越来越依赖于提供高质量的软件服务,并逐渐开发出更好的方法。但作为云计算架构师,我仍在为优先考虑硬件的业务流程,以及具有不同技能、流程和信念的工程团队导航。随着时间的推移,我和我的团队在将 .NET 应用程序迁移到 Linux、采用 Docker、迁移到 AWS 以及与之相关的最佳实践(如持续集成、自动化部署、不可变基础设施、基础设施即代码、监控等)方面变得熟练并成功。但挑战依然存在。
在此期间,我们开始将我们的应用程序拆分为一组微服务。起初,这是一个缓慢的转变,但最终这种方法流行起来,开发人员开始更喜欢构建新的服务而不是添加到现有服务。我们这些基础设施团队的人把这看作是一种成功。唯一的问题是与网络相关的问题数量激增,开发人员正在向我们寻求答案,而我们还没有准备好有效地应对这种冲击。
服务网格的援救
我第一次听说服务网格是在 2015 年,当时我正在研究服务发现工具并寻找与 Consul 集成的简单方法。我喜欢将应用程序职责卸载到“sidecar”容器的想法,并找到了一些可以帮助做到这一点的工具。大约在这个时候,Docker 有一个叫做“链接”的功能,让你可以将两个应用程序放在一个共享的网络空间中,这样它们就可以通过 localhost 进行通信。此功能提供了类似于我们现在在 Kubernetes pod 中所拥有的体验:两个独立构建的服务可以在部署时进行组合以实现一些附加功能。
我总是抓住机会用简单的方案来解决大问题,因此这些新功能的力量立即打动了我。虽然这个工具是为了与 Consul 集成而构建的,但实际上,它可以做任何你想做的事情。这是我们拥有的基础设施层,可以用来一次为所有人解决问题。
这方面的一个具体例子出现在我们采用过程的早期。当时,我们正致力于跨不同服务的日志标准化输出。通过采用服务网格和这种新的设计模式,我们能够将我们的人的问题——让开发人员标准化他们的日志——换成技术问题——将所有流量传递给可以为他们记录日志的代理。这是我们团队向前迈出的重要一步。
我们对服务网格的实现非常务实,并且与该技术的核心功能非常吻合。然而,大部分营销炒作都集中在不太需要的边缘案例上,在评估服务网格是否适合你时,能够识别这些干扰是很重要的。
核心功能
服务网格可以提供的核心功能分为四个关键责任领域:可观察性、安全性、连接性和可靠性。这些功能包括:
标准化监控
我们取得的最大胜利之一,也是最容易采用的,是标准化监控。它的运营成本非常低,可以适应你使用的任何监控系统。它使组织能够捕获所有 HTTP 或 gRPC 指标,并以标准方式在整个系统中存储它们。这控制了复杂性并减轻了应用程序团队的负担,他们不再需要实现 Prometheus 指标端点或标准化日志格式。它还使用户能够公正地了解其应用程序的黄金信号。
自动加密和身份识别
证书管理很难做好。如果一个组织还没有在这方面进行投入,他们应该找到一个网格来为他们做这件事。证书管理需要维护具有巨大安全隐患的复杂基础设施代码。相比之下,网格将能够与编排系统集成,以了解工作负载的身份,在需要时可以用来执行策略。这允许提供与 Calico 或 Cilium 等功能强大的 CNI 提供的安全态势相当或更好的安全态势。
智能路由
智能路由是另一个特性,它使网格能够在发送请求时“做正确的事”。场景包括:
- 使用延迟加权算法优化流量
- 拓扑感知路由以提高性能并降低成本
- 根据请求成功的可能性使请求超时
- 与编排系统集成以进行 IP 解析,而不是依赖 DNS
- 传输升级,例如 HTTP 到 HTTP/2
这些功能可能不会让普通人感到兴奋,但随着时间的推移,它们从根本上增加了价值
可靠的重试
在分布式系统中重试请求可能很麻烦,但是它几乎总是需要实现的。分布式系统通常会将一个客户端请求转换为更多下游请求,这意味着“尾巴”场景的可能性会大大增加,例如发生异常失败的请求。对此最简单的缓解措施是重试失败的请求。
困难来自于避免“重试风暴”或“重试 DDoS”,即当处于降级状态的系统触发重试、随着重试增加而增加负载并进一步降低性能时。天真的实现不会考虑这种情况,因为它可能需要与缓存或其他通信系统集成以了解是否值得执行重试。服务网格可以通过对整个系统允许的重试总数进行限制来实现这一点。网格还可以在这些重试发生时报告这些重试,可能会在你的用户注意到系统降级之前提醒你。
网络可扩展性
也许服务网格的最佳属性是它的可扩展性。它提供了额外的适应性层,以应对 IT 下一步投入的任何事情。Sidecar 代理的设计模式是另一个令人兴奋和强大的功能,即使它有时会被过度宣传和过度设计来做用户和技术人员还没有准备好的事情。虽然社区在等着看哪个服务网格“生出”,这反映了之前过度炒作的编排战争,但未来我们将不可避免地看到更多专门构建的网格,并且可能会有更多的最终用户构建自己的控制平面和代理以满足他们的场景。
服务网格干扰
平台或基础设施控制层的价值怎么强调都不为过。然而,在服务网格世界中,我了解到入门的一个主要的挑战是,服务网格解决的核心问题通常甚至不是大多数服务网格项目交流的焦点!
相反,来自服务网格项目的大部分交流都围绕着听起来很强大或令人兴奋但最终会让人分心的功能。这包括:
强(复)大(杂)的控制平面
要很好地运行复杂的软件是非常困难的。这就是为什么如此多的组织使用云计算来使用完全托管的服务来减轻这一点的原因。那么为什么服务网格项目会让我们负责操作如此复杂的系统呢?系统的复杂性不是资产,而是负债,但大多数项目都在吹捧它们的功能集和可配置性。
多集群支持
多集群现在是一个热门话题。最终,大多数团队将运行多个 Kubernetes 集群。但是多集群的主要痛点是你的 Kubernetes 管理的网络被切分。服务网格有助于解决这个 Kubernetes 横向扩展问题,但它最终并没有带来任何新的东西。是的,多集群支持是必要的,但它对服务网格的承诺被过度宣传了。
Envoy
Envoy 是一个很棒的工具,但它被作为某种标准介绍,这是有问题的。Envoy 是众多开箱即用的代理之一,你可以将其作为服务网格平台的基础。但是 Envoy 并没有什么内在的特别之处,使其成为正确的选择。采用 Envoy 会给你的组织带来一系列重要问题,包括:
- 运行时成本和性能(所有这些过滤器加起来!)
- 计算资源需求以及如何随负载扩展
- 如何调试错误或意外行为
- 你的网格如何与 Envoy 交互以及配置生命周期是什么
- 运作成熟的时间(这可能比你预期的要长)
服务网格中代理的选择应该是一个实现细节,而不是产品要求。
WASM
我是 Web Assembly (WASM) 的忠实拥趸,已经成功地使用它在 Blazor 中构建前端应用程序。然而,WASM 作为定制服务网格代理行为的工具,让你处于获得一个全新的软件生命周期开销的境地,这与你现有的软件生命周期完全正交!如果你的组织还没有准备好构建、测试、部署、维护、监控、回滚和版本代码(影响通过其系统运行的每个请求),那么你还没有准备好使用 WASM。
A/B 测试
直到为时已晚,我才意识到 A/B 测试实际上是一个应用程序级别的问题。在基础设施层提供原语来实现它是很好的,但是没有简单的方法来完全自动化大多数组织需要的 A/B 测试水平。通常,应用程序需要定义独特的指标来定义测试的积极信号。如果组织想要在服务网格级别投入 A/B 测试,那么解决方案需要支持以下内容:
- 对部署和回滚的精细控制,因为它可能同时进行多个不同的“测试”
- 能够捕获系统知道的自定义指标并可以根据这些指标做出决策
- 根据请求的特征暴露对流量方向的控制,其中可能包括解析整个请求正文
这需要实现很多,没有哪个服务网格是开箱即用的。最终,我们的组织选择了网格之外的特征标记解决方案,其以最小的努力取得了巨大的成功。
我们在哪里结束
最终,我们面临的挑战并不是服务网格独有的。我们工作的组织有一系列限制条件,要求我们对解决的问题以及如何解决问题采取务实的态度。我们面临的问题包括:
- 一个拥有大量不同技能的开发人员的大型组织
- 云计算和 SaaS 能力普遍不成熟
- 为非云计算软件优化的流程
- 碎片化的软件工程方法和信念
- 有限的资源
- 激进的截止日期
简而言之,我们人少,问题多,需要快速输出价值。我们必须支持主要不是 Web 或云计算的开发者,我们需要扩大规模以支持有不同方法和流程的大型工程组织来做云计算。我们需要将大部分精力集中在解决成熟度曲线较低的基本问题上。
最后,当面对我们自己的服务网格决策时,我们决定建立在 Linkerd 服务网格上,因为它最符合我们的优先事项:低运营成本(计算和人力)、低认知开销、支持性社区以及透明的管理——同时满足我们的功能要求和预算。在 Linkerd 指导委员会工作了一段时间后(他们喜欢诚实的反馈和社区参与),我了解到它与我自己的工程原则有多么的契合。Linkerd 最近在 CNCF 达到毕业状态,这是一个漫长的过程,强调了该项目的成熟及其广泛采用。
关于作者

Chris Campbell 担任软件工程师和架构师已有十多年,与多个团队和组织合作落地云原生技术和最佳实践。他在与业务领导者合作采用加速业务的软件交付策略和与工程团队合作交付可扩展的云基础架构之间分配时间。他对提高开发人员生产力和体验的技术最感兴趣。
8 - Servicemesh的未来
8.1 - (2019)微服务架构的应用集成:服务网格不是ESB
内容出处
Application Integration for Microservices Architectures: A Service Mesh Is Not an ESB
https://www.infoq.com/articles/application-integration-service-mesh/
作者 Kasun Indrasiri 发表于 2019年5月
8.2 - (2020)2020年ServiceMesh技术展望
内容出处
2020 年 Service Mesh 技术展望
本文由 ServiceMesher 社区治理委员与业界知名大牛针对 Service Mesh 技术发表的看法汇总而成。
https://cloudnative.to/blog/2020-service-mesh-technology-outlook/
背景
有外文指出,2020 年 Service Mesh 技术将有以下三大发展:
- 快速增长的服务网格需求;
- Istio 很难被打败,很可能成为服务网格技术的事实标准;
- 出现更多的服务网格用例,WebAssembly 将带来新的可能。
针对 Service Mesh 技术,ServiceMesher 社区治理委员会成员在 2020 新年伊始发表了他们各自的看法,并邀请云原生与服务网格领域业界大牛抒发各自的见解,汇总成文,希望能给读者们带来一些思考和启发。
正文
宋净超(蚂蚁金服)
用一句话概括 Service Mesh 近几年的发展——道阻且长,行则将至。这几年来我一直在探寻云原生之道,从容器、Kubernetes 再到 Service Mesh,从底层的基础设施到越来越趋向于业务层面,Service Mesh 肯定不是云原生的终极形式,其复杂性依然很高,且业界标准也尚未形成,它的发展也远没有同期的 Kubernetes 那么顺利,但是很多人都已意识到了服务网格价值,现在它正在远离最初市场宣传时的喧嚣,走向真正的落地。
罗广明(百度)
据了解,2020 年的 Kubecon EU 的提案中,很少有涉及服务网格落地场景,由此来看,服务网格技术离大规模生产落地还有很远的路要走。当前 Istio 架构体现出来的性能问题迟迟没有得到优化,使用原生的 Istio 大规模上生产还不太靠谱,有的公司选择将 mixer 功能下层至自研的数据面,有的公司通过向容器注入探针解决可观察性。总的来看,在当前服务网格部分落地场景中,大多都是基于 Istio 和 envoy,但对其或多或少都有改动,以满足公有云/私有云的需求。
此外,在 Service Mesh 落地的过程中,现有传统微服务应用(Spring Cloud/Dubbo 应用)如何平滑迁移到 Service Mesh,也是一个至关重要的话题。“双模微服务”的互联互通、共同治理有望成为 2020 年服务网格落地的关键技术之一,这也是国内几家典型云厂商力求打造的亮点产品。
马若飞(FreeWheel)
我个人认为 Service Mesh 想要真正发展成熟并大规模落地还有很长的一段路要走。一方面业界基于微服务构建的一系列服务治理框架和产品相当稳定和成熟,在功能上和 Service Mesh 有很多重合的地方,使得开发者对 Service Mesh 的需求并不迫切;另一方面,目前 Service Mesh 领域产品的成熟度还有待提高,冒险迁移过于激进,也容易面临兼容性的问题,这也制约了 Service Mesh 的落地。
从近半年厂商的动作来看,主要方向是提供托管的控制平面,并整合成熟的数据面(如 Envoy);同时提供多环境支持(如多云、混合云、VM 等)。这也和目前应用复杂多样的的部署现状有关,厂商的目的是先让你上云,再 Mesh 化。这也是一个相对稳妥且折中的方案。我司作为一个重度使用 AWS 服务的公司,选择了 AWS App Mesh 托管服务作为 mesh 的解决方案,使得和现有服务能更容易的整合,减少维护和迁移成本。
邱世达 (BoCloud)
目前来看,Kubernetes 已经逐步在企业中落地,服务上云已然是大势所趋。而随着云计算基础设施层的日益完备,在可以预见的未来,应用层服务治理必然成为新的焦点,也是在大规模微服务场景下必须要解决的问题。在 Service Mesh 领域,Istio 无疑是明星项目,除了具备一定自研能力的科技公司会定制开发自己的服务治理工具,大多数中小型企业通常会选择以 Istio 为代表的开源服务治理方案进行初步试水。实践过程中遇到问题并不可怕,我认为这反而是一种正向推动力,作为一种良性反馈,能更加积极地促使 Service Mesh 技术趋于成熟和稳定。拥抱服务网格,拥抱云原生,让我们期待 Service Mesh 在新的一年取得更大的发展!
孙海洲(中国科学院计算技术研究所)
对于 Service Mesh 来说,2019 年是极不平凡的一年,也是从观望走向生产落地的一年。在这一年里,以 Istio 为代表的 Service Mesh 开始加快发布周期,可以看到社区从以优雅架构到开始追求性能。最近社区里大家积极地参与到 Istio 文档的本地化工作中。在业界可以看到国内各个大厂开始有所举动,蚂蚁在双十一的成功大规模落地为 Service Mesh 走向生产打下了坚实的基础,同时也为大家提供了很多宝贵的经验,腾讯、百度、华为等云服务提供商也都纷纷发布相关的产品。关于 Service Mesh 的图书在今年也出版了几本,社区多次组织线下的 Service Mesh Meetup 场场爆满,可见大家对 Service Mesh 的热情与日俱增。2020年应该可以看到会有更多的 Service Mesh 的成功落地,但是当前还有很多企业还处于过渡时期,如何更好更便捷地解决向云原生迁移依赖值得关注。Service Mesh 社区的推广和布道工作依然任重而道远,需要我们更加积极努力地投入到 Service Mesh 事业中去。
赵化冰(中兴通讯)
在 2019 年里,我看到的一个有趣的现象是出现了各种各样的开源 Service Mesh 项目,基于开源 Service Mesh 项目的初创公司,以及各大云厂商的闭源 Service Mesh 实现。和 2018 年大部分项目围绕 Istio 搭建生态有所不同(至少大部分项目声称自己兼容 Istio),2019年整个 Service Mesh 生态出现了百花齐放,百家争鸣的趋势。这也许和 Istio 项目的进度有一定关系。Istio 在项目最开始发布时搭建了一个非常漂亮的架构,但实际开发的进展较慢。目前 Mixer V2 还没有能够正式发布(处于 alpha 版本), 其安全模型也在近期进行了较大的变动,导致除了流量管控之外的其他功能基本无法在生产中使用;除此之外,Istio 对于非 Kubernetes 环境的支持也非常有限。所有这些因素在一定程度上给其他 Service Mesh 项目留出了较大的发展空间。
在 Service Mesh 的不同实现纷纷涌现的情况下,要最大化利用 Service Mesh 提供了服务通信和管控能力,必须统一 Service Mesh 的标准接口。通过一个标准北向接口,对 Service Mesh 提供的流量控制,安全策略,拓扑信息、性能指标等基本能力进行组合,并加以创新,可以创建大量端到端的高附加值业务,例如支持业务平滑升级的灰度发布,测试微服务系统健壮性的混沌测试,微服务的监控系统等等。而采用一个标准的南向接口,则可以构建一个良好的数据面代理生态,甚至可能将一些传统的硬件代理设备纳入 Service Mesh 控制面进行统一管理。
在 2020 年里,我希望 Istio 项目在 telemetry 和 security 方面取得更多实际性的进展,并出现更多的商用案例。希望能够制定一个 Service Mesh 的标准接口,或者出现一个足够强大的事实标准,并看到建立在标准北向接口上的更多应用,这是 Service Mesh 的核心价值所在,也许会成为 Service Mesh 的下一个热点。
钟华(腾讯云)
还记得 2019 年初,我们对打磨半年之久的 Istio 新版本翘首以盼,大家对 Istio 的高度抽象模型褒贬不一,社区里偶尔会看到朋友问「到底有没有公司在生产环境落地了 Istio?」
在过去的一年里,Istio 持续发力,核心功能迭代更加稳定,发布了四个子版本,同时也更注重用户体验的优化。各大云厂商在 2019 年陆续实现了对 Istio 的支持,业界也出现了越来越多的 Service Mesh 生产实践,其中典型的是蚂蚁双十一大规模落地案例;笔者所在的腾讯云 TKE Mesh 团队,支持了数十个团队的 Service Mesh 改造过程,其中不乏一些场景复杂、体量庞大的核心系统。
Service Mesh 技术前景广阔,但远未成熟。展望 2020, 作为 Service Mesh 头号玩家的, Istio 还会持续快速发展,我个人很期待的一些演进: 支持 webassembly 扩展的数据面,真正生产可用的 Mixer V2,更易安装和运维的单体控制面 istiod,更容易理解和操纵的用户接口,以及提升 Istio 自身的可观测性。
Service Mesh 技术本质上是各种最佳实践的组合运用。Istio 试图运用精巧的模型,去联结各种平台、观测系统和用户应用。未来的 Istio,一定会更加复杂,这些「复杂」的目的,是让用户能更「简单」地使用 Service Mesh 领域的最佳实践。
William Morgan
Buoyant CEO, author of Linkerd,the originator of the concept
Service Mesh.
今天的服务网格处于有点不幸的状态:虽然有真实和重要的价值,但市场营销已经超过了技术本身。云供应商特别利用服务网格作为区分他们的容器产品的一种方式,而由此产生的狂热的市场推广给终端用户带来了实质性的损害。
然而,如果应用正确,服务网格确实能提供一些真正变革性的功能。从 Linkerd 的角度来看,创建服务网格的项目,我们仍然认为最小化服务网格的成本,特别是由复杂性引起的长期运营成本是最重要的。
在2020年,Linkerd 将继续专注于提供“可观察的安全性”的目标,同时最小化复杂性和使用成本 — Linkerd 的超轻、超快 Rust 代理、极简控制平面,以及“少做,而不是多做”的理念已经在这里得到了鲜明的体现。最重要的是,Linkerd 对开放治理和中立基础的承诺将确保 Linkerd 将继续成为一个为所有工程师服务的项目,而不是为某个特定云供应商的客户服务。
Christian Posta
Field CTO at solo.io, author Istio in Action and Microservices for Java Developers, open-source enthusiast, cloud application development, committer @ Apache, Serverless, Cloud, Integration, Kubernetes, Docker, Istio, Envoy blogger, blog https://blog.christianposta.com/.
回顾2019
- 更多的Service Mesh产品发布了!API/软件网络领域的每个人都正在实践自己的服务网格。我认为这对市场来说是一件好事,因为它表明这是有价值的,并且应该探索不同的实现方式。这也将指引我们在未来殊途同归。
- 越来越多的组织参与到服务网格技术中(从去年的架构讨论开始)可用性是关键!像linkerd这样的网格技术展示了如何简化使用和操作,其他产品也注意到了这一点,并尝试提高它们的可用性。
- Istio已经持续的进行定期发布,这证明了它开始走向稳定并具有可预测性。
- Consul推出了和consul模型无缝结合的L7路由特性。
- 不可忽视,虽然更多的人开始着手服务网格技术的实践,但依然有很多争议:
- 谁来支持?
- 多租户支持的不好
- 对现有应用不总是透明的
- VM+容器支持不够好
- 暴露什么样的API给用户
2020年展望
服务网格在2019年引领了潮流,我期待它能变得更加强大。2020年,会有更多的组织落地服务网格,继续与现有的网格技术集成,如Istio和其他产品:
- 多网格的存在!虽然现在已经有很多网格实现,但最终还是会收敛的。然而,有趣的是,我不认为融合会像kubernetes那样发生(我们都落在一件事情上)。我怀疑总会有多种服务网格实现会成为主流。每个云提供商都有自己的托管网格产品,这可能与本地网格不同。因此,多集群和网格的多分布将成为主要的部署实现。
- Web assembly正在流行:它提供了一种在类似Envoy这样的代理中安全地运行用户代码的方法,我们将很快看到服务网格和API网关,如istio和gloo对它提供支持。Web assembly将允许用户/供应商/组织提供功能模块,用以定制化代理并改变其默认行为。Web assembly 工具集将开始出现并对其进行管理。对于那些努力将服务网格集成到现有环境并维护组织兼容性的人来说,这将是令人兴奋的。
- 优化服务网格数据平面:去年我在第一个ServiceMeshCon演讲(PPT:https://www.slideshare.net/ceposta/the-truth-about-the-service-mesh-data-plane)讨论了如何在服务网格数据平面进行调优,就像直接运行你的代码一样。作为代理,和共享的代理。例如,gRPC最近增加了对xDS API的支持, CNCF也有一个工作组来帮助将这个“通用数据平面API”标准化以用于其他用途:https://github.com/cncf/udpa。
8.3 - (2020)2020年三大服务网格发展
前言
The Top 3 Service Mesh Developments in 2020
https://thenewstack.io/the-top-3-service-mesh-developments-in-2020/
2020年三大服务网格发展
https://z.itpub.net/article/detail/8910269504CC681F54CA2ADCE2350659
2019年,我们看到服务网格超越了试验性技术,成为了了一个组织很感兴趣并开始关注的解决方案,它是任何成功的Kubernetes部署的基本组成部分。服务网格的大规模采用开始成气候,无论是大公司还是小公司。最前沿的采用者们成功地使用了服务网格技术,后续的公司也心动起来,开始评估服务网格,以解决Kubernetes留下的挑战。
随着服务网格的日益采用,2019年出现了一个新兴的服务网格市场。Istio和Linkerd一直在发展,围绕Istio的工具和供应商生态系统全年几乎增长了两倍。也有许多新的参与者进入市场,为解决第七层网络挑战提供了替代方法。网格(如Kuma和Maesh提供的)已经出现并提供不同方法的服务网格,以解决各种边缘用例。
我们还看到了Service Mesh Interface spec和Meshery等工具的出现,它们试图进入一个早期市场,这个市场由于巨大的机会而蓬勃发展,但在关键厂商仍在等待一个契机。Network Service Mesh等相邻项目将服务网格原则带到堆栈的较低层。
虽然在服务网格领域还有很多需要解决的问题,但服务网格作为一种技术模式的价值是显而易见的,最近由451 Research进行的《Voice of the Enterprise: DevOps》调查就证明了这一点。


虽然仍然是一个新兴市场,但人们对将服务网格作为基础设施的关键部分的兴趣和采用计划正在迅速赶上Kubernetes和容器。
2020年服务网格:三大发展
1.快速增长的服务网格需求
Kubernetes正在爆炸式发展。它已成为企业和绿地部署中容器编排的首选。有一些真正的挑战存在,但人们正在探索和解决问题。Kubernetes是一项新兴技术,还有很长的路要走。但很明显,Kubernetes已经并将继续成为软件世界的主导力量。
如果Kubernetes已经赢了,并且基于Kubernetes的应用程序的规模和复杂性将会增加,那么就会有一个临界点,服务网格将是有效管理这些应用程序所必需的。
2. Istio很难被打败
市场上可能还有其他竞争者的存在,但我们将看到市场整合将在2020年开始。从长远来看,我们很可能会看到与Kubernetes类似的情况——一个赢家出现,公司围绕着这个赢家标准化。可以想象,服务网格可能不是为解决第7层网络问题而选择的技术模式。但如果真的发生了这种情况,Istio很可能成为服务网格的事实标准。
对这一点,有很多人支持,也有很多人反对,但最能说明问题的是围绕着Istio发展的生态系统。几乎每个主要的软件供应商都有一个Istio解决方案或集成,Istio开源社区在活动和贡献方面远远超过其他社区。
3. 用例,用例,用例
2019年是人们发现服务网格易于解决问题的一年。早期的采用者选择了服务网格中他们最想要的两三个功能,然后一头扎了进去。在过去一年中,需求最多的三个解决方案是:mTLS、可观察性、流量管理。
2020年将是核心服务网格用例出现的一年,并将成为下一波采用者实施服务网格解决方案的参照。
用户最想要的用例是:
-
能够更好地理解集群状态、快速调试和更深入地理解系统,从而构建更具弹性和稳定性的系统。
-
利用服务网格策略来驱动预期的应用程序行为。
-
执行并证明安全且兼容的环境。
-
像WebAssembly这样的技术使得有可能将现有的功能分发到数据平面上,并建立新的智能和可编程性。
如果你已经在使用服务网格,那么你能理解它所带来的价值。如果你正在考虑采用服务网格,那么请密切关注这个领域,用例的数量将使未来一年中它的价值越发凸显。
9 - Servicemesh介绍推荐阅读
9.1 - (2017)什么是服务网格以及为什么我们需要服务网格?
前言
What’s a service mesh? And why do I need one?
William Morgan, 发表于2017年4月24日
https://buoyant.io/what-is-a-service-mesh
https://linkerd.io/2017/04/25/whats-a-service-mesh-and-why-do-i-need-one/
中文翻译 by 薛命灯
https://www.infoq.cn/news/2017/11/WHAT-SERVICE-MESH-WHY-NEED/
Service Mesh(服务网格)是一个基础设施层,让服务之间的通信更安全、快速和可靠。如果你在构建云原生应用,那么就需要 Service Mesh。
在过去的一年中,Service Mesh 已经成为云原生技术栈里的一个关键组件。很多拥有高负载业务流量的公司都在他们的生产应用里加入了 Service Mesh,如 PayPal、Lyft、Ticketmaster 和 Credit Karma 等。今年一月份,Service Mesh 组件 Linkerd 成为 CNCF(Cloud Native Computing Foundation)的官方项目。不过话说回来,Service Mesh 到底是什么?为什么它突然间变得如此重要?
在这篇文章里,我将给出 Service Mesh 的定义,并追溯过去十年间 Service Mesh 在应用架构中的演变过程。我会解释 Service Mesh 与 API 网关、边缘代理(Edge Proxy)和企业服务总线之间的区别。最后,我会描述 Service Mesh 将何去何从以及我们可以作何期待。
什么是 Service Mesh?
Service Mesh 是一个基础设施层,用于处理服务间通信。云原生应用有着复杂的服务拓扑,Service Mesh 保证请求可以在这些拓扑中可靠地穿梭。在实际应用当中,Service Mesh 通常是由一系列轻量级的网络代理组成的,它们与应用程序部署在一起,但应用程序不需要知道它们的存在。
随着云原生应用的崛起,Service Mesh 逐渐成为一个独立的基础设施层。在云原生模型里,一个应用可以由数百个服务组成,每个服务可能有数千个实例,而每个实例可能会持续地发生变化。服务间通信不仅异常复杂,而且也是运行时行为的基础。管理好服务间通信对于保证端到端的性能和可靠性来说是非常重要的。
Service Mesh 是一种网络模型吗?
Service Mesh 实际上就是处于 TCP/IP 之上的一个抽象层,它假设底层的 L3/L4 网络能够点对点地传输字节(当然,它也假设网络环境是不可靠的,所以 Service Mesh 必须具备处理网络故障的能力)。
从某种程度上说,Service Mesh 有点类似 TCP/IP。TCP 对网络端点间传输字节的机制进行了抽象,而 Service Mesh 则是对服务节点间请求的路由机制进行了抽象。Service Mesh 不关心消息体是什么,也不关心它们是如何编码的。应用程序的目标是“将某些东西从 A 传送到 B”,而 Service Mesh 所要做的就是实现这个目标,并处理传送过程中可能出现的任何故障。
与 TCP 不同的是,Service Mesh 有着更高的目标:为应用运行时提供统一的、应用层面的可见性和可控性。Service Mesh 将服务间通信从底层的基础设施中分离出来,让它成为整个生态系统的一等公民——它因此可以被监控、托管和控制。
Service Mesh 可以做什么?
在云原生应用中传输服务请求是一项非常复杂的任务。以 Linkerd 为例,它使用了一系列强大的技术来管理这种复杂性:回路断路器、负载均衡、延迟感知、最终一致性服务发现、重试和超时。这些技术需要组合在一起,并互相协调,它们与环境之间的交互也非常微妙。
举个例子,当一个请求流经 Linkerd 时,会发生如下的一系列事件。
- Linkerd 根据动态路由规则确定请求是发给哪个服务的,比如是发给生产环境里的服务还是发给 staging 环境里的服务?是发给本地数据中心的服务还是发给云端的服务?是发给最新版本的服务还是发给旧版本的服务?这些路由规则可以动态配置,可以应用在全局的流量上,也可以应用在部分流量上。
- 在确定了请求的目标服务后,Linkerd 从服务发现端点获取相应的服务实例。如果服务实例的信息出现了偏差,Linkerd 需要决定哪个信息来源更值得信任。
- Linkerd 基于某些因素(比如最近处理请求的延迟情况)选择更有可能快速返回响应的实例。
- Linkerd 向选中的实例发送请求,并把延迟情况和响应类型记录下来。
- 如果选中的实例发生宕机、没有响应或无法处理请求,Linkerd 就把请求发给另一个实例(前提是请求必须是幂等的)。
- 如果一个实例持续返回错误,Linkerd 就会将其从负载均衡池中移除,并在稍后定时重试(这个实例有可能只是临时发生故障)。
- 如果请求超时,Linkerd 会主动放弃请求,不会进行额外的重试。
- Linkerd 以度量指标和分布式日志的方式记录上述各种行为,然后将度量指标发送给中心度量指标系统。
除此之外,Linkerd 还能发起和终止 TLS、执行协议升级、动态调整流量、在数据中心之间进行失效备援。

Linkerd 的这些特性可以保证局部的弹性和应用层面的弹性。大规模分布式系统有一个共性:局部故障累积到一定程度就会造成系统层面的灾难。Service Mesh 的作用就是在底层系统的负载达到上限之前通过分散流量和快速失效来防止这些故障破坏到整个系统。
为什么我们需要 Service Mesh?
Service Mesh 并非新出现的功能。一直以来,Web 应用程序需要自己管理复杂的服务间通信,从过去十多年间应用程序的演化就可以看到 Service Mesh 的影子。
2000 年左右的中型 Web 应用一般使用了三层模型:应用逻辑层、Web 服务逻辑层和存储逻辑层。层与层之间的交互虽然也不算简单,但复杂性是很有限的,毕竟一个请求最多只需要两个跳转。虽然这里不存在“网格”,但仍然存在跳转通信逻辑。
随着规模的增长,这种架构就显得力不从心了。像 Google、Netflix、Twitter 这样的公司面临着大规模流量的挑战,他们实现了一种高效的解决方案,也就是云原生应用的前身:应用层被拆分为多个服务(也叫作微服务),这个时候层就变成了一种拓扑结构。这样的系统需要一个通用的通信层,以一个“富客户端”包的形式存在,如 Twitter 的 Finagle 、Netflix 的 Hystrix 和 Google 的 Stubby。
一般来说,像 Finagle、Stubby 和 Hystrix 这样的包就是最初的 Service Mesh。云原生模型在原先的微服务模型中加入了两个额外的元素:容器(比如 Docker)和编排层(如 Kubernetes)。容器提供了资源隔离和依赖管理,编排层对底层的硬件进行抽象池化。
这三个组件让应用程序在云环境中具备了伸缩能力和处理局部故障的能力。但随着服务和实例的数量增长,编排层需要无时不刻地调度实例,请求在服务拓扑间穿梭的路线也变得异常复杂,再加上可以使用任意语言来开发不同的服务,所以之前那种“富客户端”包的方式就行不通了。
这种复杂性和迫切性催生了服务间通信层的出现,这个层既不会与应用程序的代码耦合,又能捕捉到底层环境高度动态的特点,它就是 Service Mesh。
Service Mesh 的未来
尽管 Service Mesh 在云原生系统方面的应用已经有了快速的增长,但仍然存在巨大的提升空间。无服务器 (Serverless) 计算(如 Amazon 的 Lambda)正好需要 Service Mesh 的命名和链接模型,这让 Service Mesh 在云原生生态系统中的角色得到了彰显。服务识别和访问策略在云原生环境中仍显初级,而 Service Mesh 毫无疑问将成为这方面不可或缺的基础。就像 TCP/IP 一样,Service Mesh 将在底层基础设施这条道上更进一步。
结论
Service Mesh 是云原生技术栈中一个非常关键的组件。Linkerd 项目在启动一年多之后正式成为 CNCF 的官方项目,并拥有了众多的贡献者和用户。Linkerd 的用户横跨初创公司(如 Monzo)到大规模的互联网公司(如 PayPal、Ticketmaster、Credit Karma),再到拥有数百年历史的老牌公司(如 Houghton Mifflin Harcourt)。
9.2 - (2017)Service Mesh:下一代微服务
我在2017年10月,QCon 上海做的主题演讲
Service Mesh:下一代微服务
https://skyao.io/talk/201710-service-mesh-next-generation-microservice/
9.3 - (2017)Pattern: Service Mesh
Phil Calçado 编写的博客 Pattern: Service Mesh,这是早期讲述 servicemesh 和 sidecar 最透彻的文章。
前言
Pattern: Service Mesh 的英文原文发表于 Phil Calçado 的个人博客网站:
https://philcalcado.com/2017/08/03/pattern_service_mesh.html
网上找到的中文翻译:
- https://segmentfault.com/a/1190000015593617
- http://walkerdu.com/2020/02/26/service_mesh_introduction/
- https://www.sohu.com/a/198248408_355135:相比之下这篇翻译的质量比较好。
以下内容为转载自最后一篇的翻译内容加我的少许修改。
自从几十年前第一次引入分布式系统以来,我们了解到分布式系统能够实现我们以前根本想象不到的用例,但它们也带来了各种新的问题。
当这些系统还很少见和简单的时候,工程师们通过尽量减少远程交互来处理增加的复杂性。处理分布式的最安全方式是尽可能地避免使用分布式,即使这意味着在各个系统中存在重复的逻辑和数据。
但行业需求推动我们前进,分布式系统从几台较大的中央计算机演变为成百上千的小型服务。在这个新的世界里,我们必须解决问题,应对新的挑战和开放性问题,首先是以个案的方式完成的临时解决方案,随后是更复杂的东西。首先,具体问题具体分析,针对某个问题给出有针对性的解决办法,然后再提供更先进更复杂的解决方案。随着我们对问题领域越来越熟悉、提出的解决办法越来越好,我们开始将一些最常见的需求总结归纳为模式、库,以及最终的平台。
第一次计算机联网
由于人们首先想到的是让两台或多台电脑相互通讯,因此,他们就设想出了这样的东西:

互相之间可以通讯的两个服务可以满足最终用户的一些需求。但这个示意图显然过于简单了,缺少了包括通过代码操作的字节转换和在线路上收发的电信号转换在内的多个层。虽然,一定程度上的抽象对于我们的讨论是必需的,但还是让我们来添加网络协议栈组件以增加一点细节内容吧:

上述模型的变种自20世纪50年代以来一直使用至今。一开始,计算机很稀少,也很昂贵,所以两个节点之间的每个链接都精心制作和维护。随着计算机变得越来越便宜,越来越流行,连接的数量和通过它们的数据量急剧增加。随着人们越来越依赖网络系统,工程师们需要确保他们构建的软件能够达到用户所要求的服务质量。
而为了达到预期的质量水平,有许多问题急需解决。人们需要找到解决方案让机器互相发现、通过同一条线路同时处理多个连接、允许机器在非直连的情况下互相通信、在网络上路由数据包、加密流量等等。
在这其中,有一种叫做流量控制的东西,下面我们以此为例。流量控制是一种机制,防止服务器发送的数据包超过下游服务器可以承受的上限。这是必要的,因为在一个联网的系统中,你至少有两个不同的、独立的计算机,彼此之间互不了解。计算机A以给定的速率向计算机B发送字节,但不能保证B可以连续地以足够快的速度来处理接收到的字节。例如,B可能正在忙于并行运行其他任务,或者数据包可能不按顺序到达,并且B可能被阻塞以等待本应该先到达的数据包。这意味着A不仅不知道B的预期性能,而且还可能让事情变得更糟,因为这可能会让B过载,B现在必须对所有这些传入的数据包进行排队处理。
一段时间以来,大家寄希望于建立网络服务和应用程序的开发者能够通过编写代码来解决上面提出的挑战。在我们的这个流程控制示例中,应用程序本身必须包含某种逻辑来确保服务不会因为数据包而过载。这种重度联网逻辑与业务逻辑一样重要。在我们的抽象示意图中,它是这样的:

幸运的是,技术的发展日新月异,随着像TCP/IP这样的标准的横空出世,流量控制和许多其他问题的解决方案被融入进了网络协议栈本身。这意味着这些流量控制代码仍然存在,但已经从应用程序转移到了操作系统提供的底层网络层中:

这个模型相当地成功。几乎任何一个组织都能够使用商业操作系统附带的TCP/IP协议栈来驱动他们的业务,即使有高性能和高可靠性的要求。
第一次使用微服务
多年以来,计算机变得越来越便宜,并且到处可见,而上面提到的网络协议栈已被证明是用于可靠连接系统的事实上的工具集。随着节点和稳定连接的数量越来越多,行业中出现了各种各样的网络系统,从细粒度的分布式代理和对象到由较大但重分布式组件组成的面向服务的架构。
这样的分布式系统给我们带来了很多有趣的更高级别的案例和好处,但也出现了几个难题。其中一些是全新的,但其他的只是我们在讨论原始网络时遇到难题的更高版本而已。
在90年代,Peter Deutsch和他在Sun公司的同事工程师们撰写了“分布式计算的八大错误”一文,其中列出了人们在使用分布式系统时通常会做出的一些假设。Peter认为,这些假设在更原始的网络架构或理论模型中可能是真实的,但在现代世界中是不成立的:
- 网络是可靠的
- 延迟为零
- 带宽是无限的
- 网络是安全的
- 拓扑是不变的
- 有一个管理员
- 传输成本为零
- 网络是同构的
大家把上面这个列表斥为“谬论”,因此,工程师们不能忽视这些问题,必须明确地处理这些问题。
为了处理更复杂的问题,需要转向更加分散的系统(我们通常所说的微服务架构),这在可操作性方面提出了新的要求。之前我们已经详细讨论了一些内容,但下面则列出了一个必须要处理的东西:
- 计算资源的快速提供
- 基本的监控
- 快速部署
- 易于扩展的存储
- 可轻松访问边缘
- 认证与授权
- 标准化的RPC
因此,尽管数十年前开发的TCP/IP协议栈和通用网络模型仍然是计算机之间相互通讯的有力工具,但更复杂的架构引入了另一个层面的要求,这再次需要由在这方面工作的工程师来实现。
例如,对于服务发现和断路器,这两种技术已用于解决上面列出的几个弹性和分布式问题。
历史往往会重演,第一批基于微服务构建的系统遵循了与前几代联网计算机类似的策略。这意味着落实上述需求的责任落在了编写服务的工程师身上。

服务发现是在满足给定查询条件的情况下自动查找服务实例的过程,例如,一个名叫 Teams 的服务需要找到一个名为 Players 的服务实例,其中该实例的 environment 属性设置为 production。你将调用一些服务发现进程,它们会返回一个满足条件的服务列表。对于更集中的架构而言,这是一个非常简单的任务,可以通常使用DNS、负载均衡器和一些端口号的约定(例如,所有服务将HTTP服务器绑定到8080端口)来实现。而在更分散的环境中,任务开始变得越来越复杂,以前可以通过盲目信任 DNS 来查找依赖关系的服务现在必须要处理诸如客户端负载均衡、多种不同环境、地理位置上分散的服务器等问题。如果之前只需要一行代码来解析主机名,那么现在你的服务则需要很多行代码来处理由分布式引入的各种问题。
断路器是由Michael Nygard在其编写的“Release It”一书中引入的模式。我非常喜欢Martin Fowler对该模式的一些总结:
断路器背后的基本思路非常简单。将一个受保护的函数调用包含在用于监视故障的断路器对象中。一旦故障达到一定阈值,则断路器跳闸,并且对断路器的所有后续调用都将返回错误,并完全不接受对受保护函数的调用。通常,如果断路器发生跳闸,你还需要某种监控警报。
这些都是非常简单的设备,它们能为服务之间的交互提供更多的可靠性。然而,跟其他的东西一样,随着分布式水平的提高,它们也会变得越来越复杂。系统发生错误的概率随着分布式水平的提高呈指数级增长,因此即使简单的事情,如“如果断路器跳闸,则监控警报”,也就不那么简单了。一个组件中的一个故障可能会在许多客户端和客户端的客户端上产生连锁反应,从而触发数千个电路同时跳闸。而且,以前可能只需几行代码就能处理某个问题,而现在需要编写大量的代码才能处理这些只存在于这个新世界的问题。
事实上,上面举的两个例子可能很难正确实现,这也是大型复杂库,如 Twitter 的 Finagle 和 Facebook 的 Proxygen,深受欢迎的原因,它们能避免在每个服务中重写相同的逻辑。

大多数采用微服务架构的组织都遵循了上面提到的那个模型,如 Netflix、Twitter 和 SoundCloud。随着系统中服务数量的增加,他们发现了这种方法存在着各种弊端。
即使是使用像 Finagle 这样的库,项目团队仍然需要投入大量的时间来将这个库与系统的其他部分结合起来,这是一个代价非常高的难题。根据我在 SoundCloud 和 DigitalOcean 的经验,我估计在100-250人规模的工程师组织中,需要有1/10的人员来构建模型。有时,这种代价很容易看到,因为工程师被分配到了专门构建工具的团队中,但是更多的时候,这种代价是看不见的,因为它表现为在产品研发上需要花费更多的时间。
第二个问题是,上面的设置限制了可用于微服务的工具、运行时和语言。用于微服务的类库通常是为特定平台编写的,无论是编程语言还是像JVM这样的运行时。如果开发团队使用了类库不支持的平台,那么通常需要将代码移植到新的平台。这浪费了本来就很短的工程时间。工程师没办法再把重点放在核心业务和产品上,而是不得不花时间来构建工具和基础架构。那就是为什么一些像 SoundCloud 和 DigitalOcean 这样的中型企业认为其内部服务只需支持一个平台,分别是 Scala 或者 Go。
这个模型最后一个值得讨论的问题是管理方面的问题。类库模型可能对解决微服务架构需求所需功能的实现进行抽象,但它本身仍然是需要维护的组件。必须要确保数千个服务实例所使用的类库的版本是相同的或至少是兼容的,并且每次更新都意味着要集成、测试和重新部署所有服务,即使服务本身没有任何改变。
下一个逻辑
类似于我们在网络协议栈中看到的那样,大规模分布式服务所需的功能应该放到底层的平台中。
人们使用高级协议(如HTTP)编写非常复杂的应用程序和服务,甚至无需考虑TCP是如何控制网络上的数据包的。这种情况就是微服务所需要的,那些从事服务开发工作的工程师可以专注于业务逻辑的开发,从而避免浪费时间去编写自己的服务基础设施代码或管理整个系统的库和框架。
将这个想法结合到我们的图表中,我们可以得到如下所示的内容:

不幸的是,通过改变网络协议栈来添加这个层并不是一个可行的任务。许多人的解决方案是通过一组代理来实现。这个的想法是,服务不会直接连接到它的下游,而是让所有的流量都将通过一个小小的软件来透明地添加所需功能。
在这个领域第一个有记载的进步使用了边车(sidecars)这个概念。“边车”是一个辅助进程,它与主应用程序一起运行,并为其提供额外的功能。在2013年, Airbnb 写了一篇有关 Synapse 和 Nerve 的文章,这是“边车”的一个开源实现。一年后,Netflix 推出了 Prana,专门用于让非JVM应用程序从他们的Netflix OSS 生态系统中受益。在 SoundCloud,我们构建了可以让遗留的 Ruby 程序使用我们为JVM微服务构建的基础设施的“边三轮”。

虽然有这么几个开源的代理实现,但它们往往被设计为需要与特定的基础架构组件配合使用。例如,在服务发现方面,Airbnb 的 Nerve 和 Synapse 假设了服务是在 Zookeeper 中注册,而对于 Prana,则应该使用 Netflix 自己的 Eureka 服务注册表。
随着微服务架构的日益普及,我们最近看到了一波新的代理浪潮,它们足以灵活地适应不同的基础设施组件和偏好。 这个领域中第一个广为人知的系统是Linkerd,它由 Buoyant 创建出来,源于他们的工程师先前在 Twitter 微服务平台上的工作。很快,Lyft 的工程团队宣布了 Envoy 的发布,它遵循了类似的原则。
Service Mesh
在这种模式中,每个服务都配备了一个代理“边车”。由于这些服务只能通过代理“边车”进行通信,我们最终会得到类似于下图的部署方案:

Buoyant的首席执行官威廉·摩根表示,代理之间的互连形成了服务网格。2017年初,威廉写下了这个平台的定义,并称它为服务网格:
服务网格是用于处理服务到服务通信的专用基础设施层。它负责通过复杂的服务拓扑来可靠地传递请求。实际上,服务网格通常被实现为与应用程序代码一起部署的轻量级网络代理矩阵,并且它不会被应用程序所感知。
这个定义最强大的地方可能就在于它不再把代理看作是孤立的组件,并承认它们本身就是一个有价值的网络。

随着微服务部署被迁移到更为复杂的运行时中去,如Kubernetes和Mesos,人们开始使用一些平台上的工具来实现网格网络这一想法。他们实现的网络正从互相之间隔离的独立代理,转移到一个合适的并且有点集中的控制面上来。

最近公布的Istio项目是这类系统中最著名的例子。
完全理解服务网格在更大规模系统中的影响还为时尚早,但这种架构已经凸显出两大优势。首先,不必编写针对微服务架构的定制化软件,即可让许多小公司拥有以前只有大型企业才能拥有的功能,从而创建出各种有趣的案例。第二,这种架构可以让我们最终实现使用最佳工具或语言进行工作的梦想,并且不必担心每个平台的库和模式的可用性。
9.4 - (2021)服务网格:每位软件工程师需要了解的世界上最被过度炒作的技术
前言
The Service Mesh
What every software engineer needs to know about the world’s most over-hyped technology
William Morgan, 发表时间未知,从过度炒作这个梗猜测是2021年。
https://buoyant.io/service-mesh-manifesto/
服务网格:每位软件工程师需要了解的世界上最被过度炒作的技术
没找到中文翻译,以下内容为自行翻译。
介绍
如果你是工作在后端系统的软件工程师,在过去几年中你可以经常听到"服务网格"这个词。由于一系列奇怪的事件,这个词像一个巨大的雪球一样在行业内滚动,粘附在越来越喧哗的营销和炒作上,并且没有任何迹象表明很快就会停止。
服务网格诞生于云原生生态系统阴暗而充满趋势的水域中,不幸的是,这意味着大量的服务网格内容从 “低营养的废话” 到使用一个技术术语–“基本上是废话”。但是,如果你能穿透所有的噪音,服务网格也有一些真实、具体和重要的价值。
在本指南中,我将尝试这样做:为服务网格提供一个诚实、深入、以工程师为中心的指南。我不仅要介绍什么,还要介绍为什么,以及现在为什么。最后,我将尝试描述为什么我认为这项特殊技术吸引了如此疯狂的炒作,这本身就是一个有趣的故事。
我是谁?
大家好,我是威廉-摩根, Linkerd 的创建者之一,Linkerd 是第一个服务网格项目,也是服务网格这个词的诞生地。(对不起!)我也是 Buoyant 的首席执行官,Buoyant是一家创业公司,建立了像 Linkerd 和 Buoyant Cloud 这样很酷的服务网格。
正如你可能想象的那样,我非常有偏见,对这个话题有一些强烈的看法。也就是说,所以我将尽力把社论化的东西降到最低(除了一个部分,“为什么人们对这个问题谈得这么多?",在那里我将揭开一些观点),我将尽力以尽可能客观的方式来写这个指南。当我需要具体的例子时,我将主要依靠 Linkerd,但当我知道与其他网格实现的差异时,我将会把它们指出来。
好的,现在开始!
什么是服务网格?
对于所有的炒作,服务网格是非常简单的。它只不过是一堆用户空间的代理,卡在你的服务的"旁边”(我们稍后会讨论 “旁边” 的意思),加上一套管理流程。代理被称为服务网格的数据平面,而管理进程被称为控制平面。数据平面拦截服务间的调用,并对这些调用进行"处理";控制平面协调代理的行为,并为运维人员提供API,以操纵和测量整个网格。

这些代理是什么?它们是7层感知的TCP代理,就像 haproxy 和 NGINX 一样。代理的选择各不相同:Linkerd 使用的是 Rust 的"微代理",简称 Linkerd-proxy,是我们专门为服务网格建立的。其他网格使用不同的代理:Envoy是一个常见的选择。但代理的选择是一个实现细节。(2020年1月编辑:请参阅《为什么Linkerd不使用Envoy》以了解为什么 Linkerd 使用 Linkerd2-proxy 而不是 Envoy。)
这些代理是做什么的?当然,他们代理服务的调用。(严格地说,它们既是"代理",也是"反向代理",处理传入和传出的调用)。它们实现了一个专注于服务间调用的功能集。这种对服务间流量的关注是服务网格代理与API网关或Ingress代理的不同之处,后者关注从外部世界到整个集群的调用。
所以,这就是数据平面。控制平面更简单:它是一组组件,提供数据平面所需的任何元件,以协调的方式行事,包括服务发现、TLS证书发放、指标汇总等等。数据平面调用控制平面以告知其行为;控制平面反过来提供一个API,允许用户修改和检查整个数据平面的行为。
下面是 Linkerd 的控制平面和数据平面的图示。可以看到,控制平面有几个不同的组件,包括一个小型的Prometheus实例,它从代理处汇总指标数据,以及destination(服务发现)、identity(证书授权)和 public-api(web和CLI终端)等组件。相比之下,数据平面只是应用实例旁边的单个 linkerd-proxy。这只是逻辑图;在部署时,你可能最终会有每个控制平面组件的三个副本,但有数百或数千个数据平面代理。
(这张图中的蓝色方框代表Kubernetes pod的边界。你可以看到,linkerd-proxy 容器实际上与应用容器运行在同一个pod中。这种模式被称为sidecar容器。)

服务网格有几个重要的影响。首先,由于代理功能集是为服务间调用而设计的,服务网格只有在你的应用被构建为服务时才有意义。你可以把它用在单体上,但要运行一个代理就需要大量的机器,而且功能集也不是很合适。
另一个结果是,服务网格将需要很多很多的代理。事实上,Linkerd 为每个服务的每个实例添加一个 linkerd-proxy。(其他一些网格的实现也会为每个节点/主机/虚拟机添加一个代理。无论哪种方式都是很多的)。) 这种大量使用代理的做法本身就有一些影响:
-
不管这些数据平面代理是什么,它们一定要快。每一次调用都会增加两跳,一个在客户端,一个在服务器端。
-
另外,代理需要小而轻。每一个代理都会消耗内存和CPU,而且这种消耗会随着你的应用线性扩展。
-
需要一个系统来部署和更新大量的代理。你不希望必须用手来做这件事。
但是,至少在10,000英尺的水平上,这就是服务网格的全部内容:部署了大量的用户空间代理来对内部的、服务间流量进行"处理",使用控制平面来改变它们的行为并查询它们产生的数据。
现在让我们继续讨论为什么。
为什么服务网格有意义?
如果你是第一次遇到服务网格的想法,你可以原谅你的第一反应是轻微的惊恐。服务网格的设计意味着它不仅会给你的应用程序增加延迟,还会消耗资源,而且还会引入一大堆机器。前一分钟你还在安装一个服务网格,后一分钟你就突然要负责操作成百上千的代理。为什么会有人想这么做呢?
答案有两部分。首先,由于生态系统正在发生一些其他变化,部署这些代理的运营成本可以大大降低。关于这一点,后面还有更多内容。
更重要的答案是,这种设计实际上是将额外的逻辑引入系统的一个好方法。这不仅是因为有大量的功能你可以在那里添加,而且还因为你可以在不改变生态系统的情况下添加它们。事实上,整个服务网格模型是建立在这个洞察力之上的:在一个多服务系统中,无论单个服务实际做什么,它们之间的流量是一个理想的功能插入点。
例如,Linkerd,像大多数网格一样,有一个第七层的功能集,主要集中在HTTP调用,包括HTTP/2和gRPC:
-
可靠性特性:请求重试、超时、金丝雀(流量拆分/转移)等。
-
可观察性特性:每个服务或单个路由的成功率、延迟和请求量的汇总;服务拓扑图的绘制;等等。
-
安全特性:双向TLS、访问控制等。
这些功能中有许多是在请求层面操作的(因此是"L7代理")。例如,如果服务 Foo 对服务 Bar 进行HTTP调用,Foo 一方的 linkerd-proxy 可以根据观察到的每个实例的延迟,在 Bar 的所有实例中智能地平衡该调用;如果请求失败,它可以重试,如果它是幂等的;它可以记录响应代码和延迟;等等。同样地,Bar那边的 linkerd-proxy 可以拒绝调用,如果它不被允许,或者超过了速率限制;它可以从自己的角度记录延迟;等等。
代理人也可以在连接层面上"做事情"。例如,Foo 的 linkerd-proxy 可以启动TLS连接,Bar 的 linkerd-proxy 可以终止它,而且双方都可以验证对方的TLS证书。这不仅提供了服务间的加密,而且提供了服务身份的加密安全形式–Foo和Bar可以"证明"它们是它们所说的人。
不管是在请求层面还是在连接层面,需要注意的重要问题是,服务网格的功能都是操作性的。Linkerd 中没有任何关于转换请求有效载荷语义的内容,例如,向JSON blob 添加字段或转换 protobuf。这是一个重要的区别,当我们谈论 ESB 和中间件时,会再次触及。
所以,这就是服务网格可以提供的一系列功能。但为什么不直接在应用程序中实现它们呢?为什么还要麻烦代理呢?
为什么服务网格是个好主意?
虽然功能集很有趣,但服务网格的核心价值其实并不在功能上。毕竟,我们可以直接在应用程序本身中实现这些功能。(事实上,我们将在后面看到这是服务网格的起源。) 如果我不得不把它归结为一句话,服务网格的价值可以归结为以下几点:服务网格提供了对运行现代服务器端软件至关重要的功能,这些功能在堆栈中是统一的,并与应用程序代码解耦。
让我们一点一点地看。
**对运行现代服务器端软件至关重要的功能。**如果你正在构建一个连接到公共互联网的事务性服务器端应用程序,接受来自外部世界的请求,并在较短的时间内对其作出响应–想想Web应用、API服务器和大部分现代服务器端软件–如果你正在将这个系统作为一个服务的集合,以同步的方式相互交谈,如果你正在不断地修改这个软件以增加更多的功能,如果你的任务是在修改这个系统的同时保持其运行,那么恭喜你,你正在构建现代服务器端软件。而上面列出的所有这些光荣的功能实际上对你来说都是至关重要的。该应用程序必须是可靠的;必须是安全的;而且必须能够观察到它在做什么。而这正是服务网格能提供帮助的地方。
(好吧,我在这里偷偷地说了一个观点:这种方法是构建服务器端软件的现代方式。今天世界上有一些人正在构建单体或 “反应式微服务” 以及其他不符合上述定义的东西,他们持有不同的观点。)
在堆栈中是统一的。服务网格不仅仅提供关键的功能,它们还能适用于应用程序中的每一个服务,无论服务是用什么语言编写的,使用什么框架,由谁编写,如何部署,或任何其他开发或部署的细节。
与应用程序代码解耦。最后,服务网不只是在你的堆栈中统一提供功能,它是以一种不需要改变应用的方式提供的。服务网格功能的基本所有权–包括配置、更新、操作、维护等方面的操作所有权–纯粹是在平台层面,独立于应用程序。应用程序可以在不涉及服务网格的情况下改变,而服务网格也可以在不涉及应用程序的情况下改变。
简而言之:服务网格不仅提供重要的功能,而且是以一种全局的、统一的、独立于应用程序的方式提供的。因此,尽管服务网格的功能可以在服务代码中实现(甚至作为一个库被链接到每个服务中),但这种方法不会提供解耦和统一性,而这正是服务网格价值的核心所在。
而你所要做的就是增加大量的代理! 我保证,我们很快就会讨论增加所有这些代理的运营成本。但首先,我们需要稍息,从人的角度来研究这个解耦的想法。
服务网格能帮助谁?
尽管可能很不方便,但事实证明,为了使技术真正产生影响,它必须被人类采用。那么,谁采用了服务网格?谁会从中受益?
如果你正在构建我上面所说的现代服务器软件,你可以大致认为你的团队分为服务所有者和平台所有者,前者从事构建业务逻辑的工作,后者则是构建这些服务所运行的内部平台。在小型组织中,这些人可能是同一个人,但随着组织规模的扩大,这些角色通常会变得更加明确,甚至进一步细分。(这里还有很多关于devops的变化性质、微服务的组织影响等的内容。但现在让我们把这些描述作为一个既定的事实)。)
从这个角度看,服务网格的直接受益者是平台所有者。毕竟,平台团队的目标是建立内部平台,让服务所有者可以在上面运行他们的业务逻辑,并且以一种让服务所有者尽可能独立于操作细节的方式来实现。服务网格不仅提供对实现这一目标至关重要的功能,而且其方式不会反过来引起对服务所有者的依赖。
服务所有者也受益,尽管是以更间接的方式。服务所有者的目标是在构建业务逻辑时尽可能地富有成效,而他们需要担心的运维机制越少,就越容易实现。他们不需要为实施重试策略或TLS而操心,而是可以纯粹地关注业务逻辑问题,并相信平台会处理好其他问题。这对他们来说也是一个很大的好处。
平台和服务所有者之间解耦的组织价值怎么强调都不过分。事实上,我认为这可能是服务网格有价值的关键原因。
当我们最早的 Linkerd 采用者之一告诉我们他们采用服务网格的原因时,我们学到了这个教训:因为它允许他们 “不必与人交谈”。这是一家大公司的平台团队,正在向 Kubernetes 迁移。由于他们的应用程序处理敏感信息,他们希望对集群上的所有通信进行加密。有数百个服务和数百个开发团队,他们不希望说服每个开发团队将 TLS 添加到他们的路线图中。通过安装 Linkerd,他们将该功能的所有权从开发人员手中转移到了平台团队手中,因为对他们来说,这是一个强加的任务。Linkerd 并没有为他们解决一个技术问题,而是解决了一个组织问题。
简而言之,服务网格与其说是一个技术问题的解决方案,不如说是一个社会技术问题的解决方案。
服务网格是否能解决我所有的问题?
是的。呃,不是!
如果你看一下上面概述的三类功能–可靠性、安全性和可观察性–应该很清楚,服务网格不是这些领域的完整解决方案。虽然 Linkerd 可以在知道请求是无效的情况下重试,但它不能决定在服务完全中断的情况下向用户返回什么–应用程序必须做出这些决定。虽然 Linkerd 可以报告成功率等,但它不能查看服务内部并报告内部指标–应用程序必须有工具。虽然 Linkerd 可以 “免费” 做双向TLS这样的事情,但安全解决方案的内容远不止这些。
在这些领域中,服务网格提供的功能子集是属于平台功能的。我的意思是这些功能:
-
独立于业务逻辑。为 Foo 和 Bar 之间的调用计算流量延迟直方图的方式与 Foo 首先调用 Bar 的原因完全无关。
-
难以正确实现。Linkerd的重试是用重试预算等复杂的东西来设置参数的,因为对重试的天真做法是导致 “重试风暴” 和其他分布式系统故障模式的必经之路。
-
统一实施时最有效。互相TLS的机制只有在每个人都在做的时候才真正有意义。
因为这些功能是在代理层实现的,而不是在应用层,服务网格在平台而不是应用层面提供这些功能。服务用什么语言编写,或使用什么框架,或由谁编写,或如何得到的,都不重要。代理的功能独立于所有这些,而且这种功能的所有权–包括配置、更新、操作、维护等方面的操作所有权–纯粹是在平台层面。
服务网格的示例特征
| 可观察性 | 可靠性 | 安全性 | |
|---|---|---|---|
| 服务网格 | 服务成功率 | 请求重试 | 所有服务之间都是双向TLS |
| 平台(非服务网格) | 日志聚合 | 数据集的多个副本 | 静止状态下的数据加密 |
| 应用程序 | 内部功能使用的仪表化 | 处理整个组件宕机时的故障 | 确保用户只能访问自己的数据 |
总结:服务网格并不是可靠性、或可观察性、或安全性的完整解决方案。这些领域更广泛的所有权必然涉及服务所有者、运维和SRE团队以及组织的其他部分。服务网格只能提供每个领域的平台层"切片"。
为什么服务网格现在有意义了?
在这一点上,你可能会对自己说:好吧,如果这个服务网格的东西这么棒,为什么十年前我们没有在我们的堆栈中玩转数百万个代理?
对此有一个浅显的答案,那就是十年前大家都在构建单体,所以没有人需要服务网格。这是事实,但我认为忽略了问题的关键。甚至在十年前,“微服务"的概念作为构建大规模系统的可行方式被广泛讨论,并在 Twitter、Facebook、Google 和 Netflix 等公司公开付诸实践。至少在我所接触到的部分行业中,普遍的看法是,微服务是构建大规模系统的"正确方式”,即使它们做起来真的很痛苦。
当然,虽然十年前就有公司在运维微服务,但他们基本上没有到处安装代理来形成服务网格。不过,如果你仔细观察,他们在做一些相关的事情:许多这些组织强制要求使用特定的内部库来进行网络通信(有时称为"胖客户端"库)。Netflix 有 Hysterix,谷歌有 Stubby 库,而 Twitter 有 Finagle。例如,Finagle 是 Twitter 的每项新服务都必须使用的,它同时处理客户端和服务器端的连接,并实现重试、请求路由、负载平衡和仪表等。它为整个 Twitter 堆栈提供了一个一致的可靠性和可观察性层,与服务本身的实际工作无关。当然,它只适用于JVM语言,而且它有一个编程模型,你必须围绕它建立整个应用程序,但它提供的操作功能几乎与服务网格的功能完全相同。
因此,十年前,我们不仅有了微服务,还有了原生的服务网格库,解决了许多今天服务网格所解决的问题。但我们还没有服务网格。首先需要改变一些别的东西。
而这正是更深层次的答案所在,它埋藏在过去十年发生的另一个差异中:部署微服务的成本大幅降低。我在上面列出的那些十年前公开使用微服务的公司–Twitter、Netflix、Facebook、Google–都是规模巨大、资源丰富的公司。他们不仅有需求,而且有人才来构建、部署和运维重要的微服务应用。Twitter从单体迁移到微服务所花费的工程时间和精力之多,让人难以想象。
对比今天,你可能会遇到微服务与开发人员比例为5:1甚至10:1的初创公司,更重要的是,他们有能力处理这个问题。如果运行50个微服务对于一个5人的初创公司来说是一个合理的方法,那么显然有什么东西降低了采用微服务的成本。

备注:这张图片来自 https://twitter.com/JackKleeman/status/1190407465659183104,在 monzo 有1500个微服务,150个工程师,蓝色线条代表容许网络规则容许的流量。
微服务运维成本的大幅降低的结果是:容器和容器编排器的采用率上升。而这正是什么变化使服务网格得以实现这一问题的更深层次答案所在。使得服务网格在运维上可行的,也使得微服务在运维上可行的东西是:Kubernetes 和 Docker。
为什么?嗯,Docker解决了一件大事:打包问题。通过允许将应用及其(非网络)运行时的依赖打包到一个容器中,应用现在是一个可替换的单元,可以被扔到任何地方并运行。同样,Docker使运行多语言堆栈变得更加容易:因为容器是原子执行单元,对于部署和操作来说,容器内是什么并不重要,不管它是JVM应用还是Node应用,还是Go、Python或Ruby。你只需运行它。
Kubernetes解决了下一步的问题:现在我有一堆"可执行的东西",我也有一堆"可以执行这些可执行的东西"(也就是机器),我需要它们之间的映射关系。从广义上讲,你给 Kubernetes 一堆容器和一堆机器,它就能找出这种映射。(当然,这是一个动态的和不断变化的东西,因为新的容器在系统中滚动,机器进入和退出操作,等等。但是,Kubernetes会把它弄清楚。)
一旦有了 Kubernetes,运行一个服务的部署时间成本与运行十个服务没有太大区别,实际上与100个服务没有太大区别。结合容器作为鼓励多语言实现的打包机制,结果是大量的新应用被实现为用各种语言编写的微服务–正是服务网格最适合的环境。
因此,最后我们来看看为什么服务网格现在是可行的:Kubernetes为服务提供的统一性也直接适用于服务网格的运维挑战。把代理打包到容器中,告诉Kubernetes把它们贴在任何地方,然后就可以了!你得到了一个服务网格,所有的部署时间机制都由Kubernetes为你处理。
总结一下:与10年前相比,现在的服务网格之所以有意义,是因为 Kubernetes 和 Docker 的兴起不仅极大地增加了运行服务网格的需求,使你的应用可以轻松地构建成一个多角化的微服务架构,而且通过提供部署和维护 sidecar 代理机群的机制,极大地降低了运行服务网格的成本。
为什么人们对服务网格谈论得如此之多?
内容警告:在本节中,我采用了推测、猜想、仅是个人观点。
人们只需要搜索"服务网格",就会遇到一个kafka式的热梦景观,充斥着了混乱的项目、低热量的循环内容和普遍的回声室扭曲。所有闪亮的新技术都有一定程度的这种情况,但服务网格似乎特别糟糕。为什么会这样?
嗯,部分原因是我的错。我已经尽了最大的努力,一有机会就谈论 Linkerd 和服务网格,在无数的博客文章、播客和像这样的文章中。但我并没有那么强大。要真正回答这个问题,我必须谈一谈服务网格。如果不谈一个特别的项目,就不可能谈及这个景观。Istio是一个开源的服务网格,是谷歌、IBM和Lyft之间的合作。
Istio 的显著之处在于两点。首先,谷歌在其背后付出了巨大的营销努力。据我估计,今天知道这个服务网格的大多数人都是通过Istio介绍的。第二件了不起的事情是Istio的反响有多差。显然,我在利益相关者,但在我看来,Istio已经形成了相当大的公众反响,这对一个开源项目来说是不常见的(虽然不是闻所未闻的)。
撇开我的个人理论不谈,我相信谷歌的参与才是服务网格被炒得如此火热的真正原因。具体来说,a)Istio被谷歌大力推广;b)其相应的乏善可陈;以及 c)最近Kubernetes的陨落让每个人都记忆犹新,这些因素结合在一起,形成了一种令人陶醉的无氧环境,理性思考的能力被扼杀,只剩下一种奇怪的云原生郁金香狂热。
当然,从 Linkerd 的角度来看,这是……我想我会将其描述为一种混合的祝福。我的意思是,现在服务网格是一个"东西",这很好–2016年Linkerd刚刚起步时,情况并非如此,而且真的很难让人注意到。我们现在没有这个问题了!但糟糕的是,服务网格如此混乱,甚至很难理解哪些项目是服务网格,更不用说哪个项目最适合你的用例。这对每个人都是一种伤害。(当然,在某些情况下,Istio或其他项目会是比Linkerd更正确的选择–它远不是一个万能的解决方案。)
在Linkerd方面,我们的策略是忽略这些噪音,继续专注于为我们的社区解决真正的问题,并基本上等待整个事情的结束。炒作的程度最终会消退,我们都可以继续我们的生活。
不过,在此期间,我们都将不得不一起承受这一切。
那么…我,一个卑微的软件工程师,应该关心服务网格吗?
如果你是一个软件工程师,以下是我对你是否应该关心服务网的基本评判标准。
如果你是一个纯粹的业务逻辑实施的开发者角色。不,你真的不需要关心服务网。我的意思是,我们当然欢迎你去关心,但理想情况下,服务网格不会直接影响你的生活。继续建立甜蜜的商业逻辑,让你周围的人都得到报酬。
如果你在一个正在使用Kubernetes的组织中担任平台角色。是的,你100%应该关心。除非你采用K8s纯粹是为了运行一个单体或做批处理(在这种情况下,我会认真地问为什么要用K8s),否则你最终会遇到这样的情况:你有很多微服务,都是由其他人编写的,都在相互访问,都被捆绑在一起,成为一个运行时依赖的邪恶捆绑,你需要一种方法来处理这些。由于你是在Kubernetes上,你将有几个服务网格的选择,你应该对哪些服务网格,甚至你是否想要任何一个服务网格有一个明智的看法。(从Linkerd开始)
如果你在一个不使用Kubernetes的组织中担任平台角色,但却在"做微服务"。是的,你应该关心,但这将是复杂的。当然,你可以通过在各处部署大量的代理来获得服务网格的价值,但Kubernetes的优点是部署模式,如果你必须自己管理这些代理,你的投资回报率方程将看起来非常不同。
如果你在一个"做单体"的组织中担任平台角色。不,你可能不需要关心。如果你正在运维一个单体,甚至是一个"单体的集合",有明确的和不经常变化的通信模式,那么服务网格不会增加很多,你可以忽略它并希望它消失。
结论
服务网格可能实际上并不拥有 “世界上最被过度炒作的技术” 的称号–这个可疑的称号可能是属于比特币或人工智能。也许它只是排在前五名。但是,如果你能穿过层层噪音,对于在Kubernetes上构建应用程序的人来说,有一些真正的价值可以利用。
最后,我很想让你试试 Linkerd–在Kubernetes集群上安装它应该需要60秒,甚至只是在你的笔记本电脑上安装一个Minikube,你可以自己看看我到底在说什么。
9.5 - (2021)分布式系统在 Kubernetes 上的进化
内容出处
The Evolution of Distributed Systems on Kubernetes
https://www.infoq.com/articles/distributed-systems-kubernetes/
分布式系统在 Kubernetes 上的进化
本文翻译自 Bilgin Ibryam 的文章 The Evolution of Distributed Systems on Kubernetes。
https://cloudnative.to/blog/distributed-systems-kubernetes/
在 3 月份的 QCon 上,我做了一个关于 Kubernetes 的分布式系统进化的演讲。首先,我想先问一个问题,微服务之后是什么?我相信大家都有各自的答案,我也有我的答案。你会在最后发现我的想法是什么。为了达到这个目的,我建议大家看看分布式系统的需求是什么?以及这些需求在过去是如何发展的,从单体应用开始到 Kubernetes,再到最近的 Dapr、Istio、Knative 等项目,它们是如何改变我们做分布式系统的方式。我们将尝试对未来做一些预测。
现代分布式应用
为了给这个话题提供更多的背景信息,我认为的分布式系统是由数百个组件组成的系统。这些组件可以是有状态的、无状态的或者无服务器的。此外,这些组件可以用不同的语言创建,运行在混合环境上,并开发开源技术、开放标准和互操作性。我相信你可以使用闭源软件来构建这样的系统,也可以在 AWS 和其他地方构建。具体到这次演讲,我将关注 Kubernetes 生态系统,以及你如何在 Kubernetes 平台上构建这样一个系统。
我们从分布式系统的需求讲起。我认为是我们要创建一个应用或者服务,并写一些业务逻辑。那从运行时的平台到构建分布式系统,我们还需要什么呢?在底层,最开始是我们要一些生命周期的能力。当你用任一语言开发你的应用时,我们希望有能力把这个应用可靠地打包和部署、回滚、健康检查。并且能够把应用部署到不同的节点上,并实现资源隔离、扩展、配置管理,以及所有这些。这些都是你创建分布式应用所需要的第一点。
第二点是围绕网络。我们有了应用之后,我们希望它能够可靠地连接到其他服务,无论该服务是在集群内部还是在外部。我们希望其具有服务发现、负载均衡的能力。为了不同的发布策略或是其他的一些原因的我们希望有流量转移的能力。然后我们还希望其具有与其他系统进行弹性通信的能力,无论是通过重试、超时还是断路器。要有适当的安全保障,并且要有足够的监控、追踪、可观察性等等。
我们有了网络之后,接下来就是我们希望有能力与不同的 API 和端点交互,即资源绑定–与其他协议和不同的数据格式交互。甚至能够从一种数据格式转换成另一种数据格式。我还会在这里加入诸如过滤功能,也就是说,当我们订阅一个主题时,我们也许只对某些事件感兴趣。
你认为最后一类是什么?是状态。当我在说状态和有状态的抽象时,我并不是在谈论实际的状态管理,比如数据库或者文件系统的功能。我要说的更多是有关幕后依赖状态的开发人员抽象。可能,你需要具有工作流管理的能力。也许你想管理运行时间长的进程或者做临时调度或者某些定时任务来定期运行服务。也许你还想进行分布式缓存,具有幂等性或者支持回滚。所有这些都是开发人员级的原语,但在幕后,它们依赖于具有某种状态。你想随意使用这些抽象来创建完善的分布式系统。
我们将使用这个分布式系统原语的框架来评估它们在 Kubernetes 和其他项目上的变化情况。
单体架构——传统中间件功能
假设我们从单体架构以及如何获得这些能力开始。在那种情况下,首先是当我说单体的时候,在分布式应用的情况下我想到的是 ESB。ESB 是相当强大的,当我们检查我们的需求列表时,我们会说 ESB 对所有有状态的抽象有很好的支持。
使用 ESB,你可以进行长时间运行的流程的编排、分布式事务、回滚和幂等。此外,ESB 还提供了出色的资源绑定能力,并且有数百个连接器,支持转换、编排,甚至有联网功能。最后,ESB 甚至可以做服务发现和负载均衡。
它具有围绕网络连接的弹性的所有功能,因此它可以进行重试。可能 ESB 本质上不是很分布式,所以它不需要非常高级的网络和发布能力。ESB 欠缺的主要是生命周期管理。因为它是单一运行时,所以第一件事就是你只能使用一种语言。通常是创建实际运行时的语言,Java、.NET 或者其他的语言。然后,因为是单一运行时,我们不能轻松地进行声明式的部署或者自动调配。部署是相当大且非常重的,所以它通常涉及到人机交互。这种单体架构的另一个难点是扩展:“我们无法扩展单个组件。”
最后却并非最不重要的一点是,围绕隔离,无论是资源隔离还是故障隔离。使用单体架构无法完成所有这些工作。从我们的需求框架来看,ESB 的单体架构不符合条件。
云原生架构——微服务和 Kubernetes
接下来,我建议我们研究一下云原生架构以及这些需求是如何变化的。如果我们从一个非常高的层面来看,这些架构是如何发生变化的,云原生可能始于微服务运动。微服务使我们可以按业务领域进行拆分单体应用。事实证明,容器和 Kubernetes 实际上是管理这些微服务的优秀平台。让我们来看一下 Kubernetes 对于微服务特别有吸引力的一些具体特性和功能。
从一开始,进行健康状况探测的能力就是 Kubernetes 受欢迎的原因。在实践中,这意味着当你将容器部署到 Pod 中时,Kubernetes 会检查进程的运行状况。通常情况下,该过程模型还不够好。你可能仍然有一个已启动并正在运行的进程,但是它并不健康。这就是为什么还可以使用就绪度和存活度检查的原因。Kubernetes 会做一个就绪度检查,以确定你的应用在启动期间何时准备接受流量。它将进行活跃度检查,以检查服务的运行状况。在 Kubernetes 之前,这并不是很流行,但今天几乎所有语言、所有框架、所有运行时都有健康检查功能,你可以在其中快速启动端点。
Kubernetes 引入的下一个特性是围绕应用程序的托管生命周期——我的意思是,你不再控制何时启动、何时关闭服务。你相信平台可以做到这一点。Kubernetes 可以启动你的应用;它可以将其关闭,然后在不同的节点上移动它。为此,你必须正确执行平台在应用启动和关闭期间告诉你的事件。
Kubernetes 流行的另一件特性是围绕着声明式部署。这意味着你不再需要启动服务;检查日志是否已经启动。你不必手动升级实例——支持声明式部署的 Kubernetes 可以为你做到这一点。根据你选择的策略,它可以停止旧实例并启动新实例。此外,如果出现问题,可以进行回滚。
另外就是声明你的资源需求。创建服务时,将其容器化。最好告诉平台该服务将需要多少 CPU 和内存。Kubernetes 利用这些信息为你的工作负载找到最佳节点。在使用 Kubernetes 之前,我们必须根据我们的标准将实例手动放置到一个节点上。现在,我们可以根据自己的偏好来指导 Kubernetes,它将为我们做出最佳的决策。
如今,在 Kubernetes 上,你可以进行多语言配置管理。无需在应用程序运行时进行配置查找就可以进行任何操作。Kubernetes 会确保配置最终在工作负载所在的同一节点上。这些配置被映射为卷或环境变量,以供你的应用程序使用。
事实证明,我刚才谈到的那些特定功能也是相关的。比如说,如果要进行自动放置,则必须告诉 Kubernetes 服务的资源需求。然后,你必须告诉它要使用的部署策略。为了让策略正确运行,你的应用程序必须执行来自环境的事件。它必须执行健康检查。一旦采用了所有这些最佳实践并使用所有这些功能,你的应用就会成为出色的云原生公民,并且可以在 Kubernetes 上实现自动化了(这是在 Kubernetes 上运行工作负载的基本模式)。最后,还有围绕着构建 Pod 中的容器、配置管理和行为,还有其他模式。
我要简要介绍的下一个主题是工作负载。从生命周期的角度来看,我们希望能够运行不同的工作负载。我们也可以在 Kubernetes 上做到这一点。运行十二要素应用程序和无状态微服务非常简单。Kubernetes 可以做到这一点。这不是你将要承担的唯一工作量。可能你还有有状态的工作负载,你可以使用有状态集在 Kubernetes 上完成此工作。
你可能还有的另一个工作负载是单例。也许你希望某个应用程序的实例是整个集群中应用程序的唯一一个实例–你希望它成为可靠的单例。如果失败,则重新启动。因此,你可以根据需求以及是否希望单例至少具有一种或最多一种语义来在有状态集和副本集之间进行选择。你可能还有的另一个工作负载是围绕作业和定时作业–有了 Kubernetes,你也可以实现这些。
如果我们将所有这些 Kubernetes 功能映射到我们的需求,则 Kubernetes 可以满足生命周期需求。我通常创建的需求列表主要是由 Kubernetes 今天提供给我们的。这些是任何平台上的预期功能,而 Kubernetes 可以为你的部署做的是配置管理、资源隔离和故障隔离。此外,除了无服务器本身之外,它还支持其他工作负载。
然后,如果这就是 Kubernetes 给开发者提供的全部功能,那么我们该如何扩展 Kubernetes 呢?以及如何使它具有更多功能?因此,我想描述当今使用的两种常用方法。
进程外扩展机制
首先是 Pod 的概念,Pod 是用于在节点上部署容器的抽象。此外,Pod 给我们提供了两组保证:
- 第一组是部署保证 – Pod 中的所有容器始终位于同一个节点上。这意味着它们可以通过 localhost 相互通信,也可以使用文件系统或通过其他 IPC 机制进行异步通信。
- Pod 给我们的另一组保证是围绕生命周期的。Pod 中的所有容器并非都相等。
根据使用的是 init 容器还是应用程序容器,你会获得不同的保证。例如,init 容器在开始时运行;当 Pod 启动时,它按顺序一个接一个地运行。他们仅在之前的容器已成功完成时运行。它们有助于实现由容器驱动的类似工作流的逻辑。
另一方面,应用程序容器是并行运行的。它们在整个 Pod 的生命周期中运行,这也是 sidecar 模式的基础。sidecar 可以运行多个容器,这些容器可以协作并共同为用户提供价值。这也是当今我们看到的扩展 Kubernetes 附加功能的主要机制之一。
为了解释以下功能,我必须简要地告诉你 Kubernetes 内部的工作方式。它是基于调谐循环的。调谐循环的思想是将期望状态驱动到实际状态。在 Kubernetes 中,很多功能都是靠这个来实现的。例如,当你说我要两个 Pod 实例,这系统的期望状态。有一个控制循环不断地运行,并检查你的 Pod 是否有两个实例。如果不存在两个实例,它将计算差值。它将确保存在两个实例。
这方面的例子有很多。一些是副本集或有状态集。资源定义映射到控制器是什么,并且每个资源定义都有一个控制器。该控制器确保现实世界与所需控制器相匹配,你甚至可以编写自己的自定义控制器。
当在 Pod 中运行应用程序时,你将无法在运行时加载任何配置文件更改。然而,你可以编写一个自定义控制器,检测 config map 的变化,重新启动 Pod 和应用程序–从而获取配置更改。
事实证明,即使 Kubernetes 拥有丰富的资源集合,但它们并不能满足你的所有不同需求。Kubernetes 引入了自定义资源定义的概念。这意味着你可以对需求进行建模并定义适用于 Kubernetes 的 API。它与其他 Kubernetes 原生资源共存。你可以用能理解模型的任何语言编写自己的控制器。你可以设计一个用 Java 实现的 ConfigWatcher,描述我们前面所解释的内容。这就是 operator 模式,即与自定义资源定义一起使用的控制器。如今,我们看到很多 operator 加入,这就是第二种扩展 Kubernetes 附加功能的方式。
接下来,我想简单介绍一下基于 Kubernetes 构建的一些平台,这些平台大量使用 sidecar 和 operator 来给开发者提供额外的功能。
什么是服务网格?
让我们从服务网格开始,什么是服务网格?
我们有两个服务,服务 A 要调用服务 B,并且可以用任何语言。把这个当做是我们的应用工作负载。服务网格使用 sidecar 控制器,并在我们的服务旁边注入一个代理。你最终会在 Pod 中得到两个容器。代理是一个透明的代理,你的应用对这个代理完全无感知–它拦截所有传入和传出的流量。此外,代理还充当数据防火墙。
这些服务代理的集合代表了你的数据平面,并且很小且无状态。为了获得所有状态和配置,它们依赖于控制平面。控制平面是保持所有配置,收集指标,做出决定并与数据平面进行交互的有状态部分。此外,它们是不同控制平面和数据平面的正确选择。事实证明,我们还需要一个组件-一个 API 网关,以将数据获取到我们的集群中。一些服务网格具有自己的 API 网关,而某些使用第三方。如果你研究下所有这些组件,它们将提供我们所需的功能。
API 网关主要专注于抽象我们服务的实现。它隐藏细节并提供边界功能。服务网格则相反。在某种程度上,它增强了服务内的可见性和可靠性。可以说,API 网关和服务网格共同提供了所有网络需求。要在 Kubernetes 上获得网络功能,仅使用服务是不够的:“你需要一些服务网格。”
什么是 Knative?
我要讨论的下一个主题是 Knative,这是 Google 几年前启动的一个项目。它是 Kubernetes 之上的一层,可为您提供无服务器功能,并具有两个主要模块:
- Knative 服务 - 围绕着请求-应答交互,以及
- Knative Eventing - 更多的是用于事件驱动的交互。
只是让你感受一下,Knative Serving 是什么?通过 Knative Serving,你可以定义服务,但这不同于 Kubernetes 服务。这是 Knative 服务。使用 Knative 服务定义工作负载后,你就会得到具有无服务器的特征的部署。你不需要有启动并运行实例。它可以在请求到达时从零开始。你得到的是无服务器的能力;它可以迅速扩容,也可以缩容到零。
Knative Eventing 为我们提供了一个完全声明式的事件管理系统。假设我们有一些要与之集成的外部系统,以及一些外部的事件生产者。在底部,我们将应用程序放在具有 HTTP 端点的容器中。借助 Knative Eventing,我们可以启动代理,该代理可以触发 Kafka 映射的代理,也可以在内存或者某些云服务中。此外,我们可以启动连接到外部系统的导入器,并将事件导入到我们的代理中。这些导入器可以基于,例如,具有数百个连接器的 Apache Camel。
一旦我们将事件发送给代理,然后用 YAML 文件声明,我们可以让容器订阅这些事件。在我们的容器中,我们不需要任何消息客户端–比如 Kafka 客户端。我们的容器将使用云事件通过 HTTP POST 获取事件。这是一个完全平台管理的消息传递基础设施。作为开发人员,你必须在容器中编写业务代码,并且不处理任何消息传递逻辑。
从我们的需求的角度来看,Knative 可以满足其中的一些要求。从生命周期的角度来看,它为我们的工作负载提供了无服务器的功能,因此能够将其扩展到零,并从零开始激活。从网络的角度来看,如果服务网格之间存在某些重叠,则 Knative 也可以进行流量转移。从绑定的角度来看,它对使用 Knative 导入程序进行绑定提供了很好的支持。它可以使我们进行发布/订阅,或点对点交互,甚至可以进行一些排序。它可以满足几类需求。
什么是 Dapr?
另一个使用 sidecar 和 operator 的项目是 Dapr,它是微软几个月前才开始并且正在迅速流行起来。此外,1.0 版本 被认为是生产可用的。它是一个作为 sidecar 的分布式系统工具包–Dapr 中的所有内容都是作为 sidecar 提供的,并且有一套他们所谓的构件或功能集的集合。
这些功能是什么呢?第一组功能是围绕网络。Dapr 可以进行服务发现和服务之间的点对点集成。同样,它也可以进行服务网格的追踪、可靠通信、重试和恢复。第二套功能是围绕资源绑定:
- 它有很多云 API、不同系统的连接器,以及
- 也可以做消息发布/订阅和其他逻辑。
有趣的是,Dapr 还引入了状态管理的概念。除了 Knative 和服务网格提供的功能外,Dapr 在状态存储之上进行了抽象。此外,你通过存储机制支持与 Dapr 进行基于键值的交互。
在较高的层次上,架构是你的应用程序位于顶部,可以使用任何语言。你可以使用 Dapr 提供的客户端库,但你不必这样做。你可以使用语言功能来执行称为 sidecar 的 HTTP 和 gRPC。与 服务网格的区别在于,这里的 Dapr sidecar 不是一个透明的代理。它是一个显式代理,你必须从你的应用中调用它,并通过 HTTP 或 gRPC 与之交互。根据你需要的功能,Dapr 可以与其他如云服务的系统对话。
在 Kubernetes 上,Dapr 是作为 sidecar 部署的,并且可以在 Kubernetes 之外工作(不仅仅是 Kubernetes)。此外,它还有一个 operator – 而 sidecar 和 Operator 是主要的扩展机制。其他一些组件管理证书、处理基于 actor 的建模并注入 sidecar。你的工作负载与 sidecar 交互,并尽其所能与其他服务对话,让你与不同的云提供商进行互操作。它还为你提供了额外的分布式系统功能。
综上所述,这些项目所提供的功能,我们可以说 ESB 是分布式系统的早期化身,其中我们有集中式的控制平面和数据平面–但是扩展性不好。在云原生中,集中式控制平面仍然存在,但是数据平面是分散的–并且具有隔音功能和高度的可扩展性。
我们始终需要 Kubernetes 来做良好的生命周期管理,除此之外,你可能还需要一个或多个附加组件。你可能需要 Istio 来进行高级联网。你可能会使用 Knative 来进行无服务器工作负载,或者使用 Dapr 来做集成。这些框架可与 Istio 和 Envoy 很好的配合使用。从 Dapr 和 Knative 的角度来看,你可能必须选择一个。它们共同以云原生的方式提供了我们过去在 ESB 上拥有的东西。
未来云原生趋势–生命周期趋势
在接下来的部分,我列出了一些我认为在这些领域正在发生令人振奋的发展的项目。
我想从生命周期开始。通过 Kubernetes,我们可以为应用程序提供一个有用的生命周期,这可能不足以进行更复杂的生命周期管理。比如,如果你有一个更复杂的有状态应用,则可能会有这样的场景,其中 Kubernetes 中的部署原语不足以为应用提供支持。
在这些场景下,你可以使用 operator 模式。你可以使用一个 operator 来进行部署和升级,还可以将 S3 作为服务备份的存储介质。此外,你可能还会发现 Kubernetes 的实际健康检查机制不够好。假设存活检查和就绪检查不够好。在这种情况下,你可以使用 operator 对你的应用进行更智能的存活和就绪检查,然后在此基础上进行恢复。
第三个领域就是自动伸缩和调整。你可以让 operator 更好的了解你的应用,并在平台上进行自动调整。目前,编写 operator 的框架主要有两个,一个是 Kubernetes 特别兴趣小组的 Kubebuilder,另一个是红帽创建的 operator 框架的一部分–operator SDK。它有以下几个方面的内容:
Operator SDK 让你可以编写 operator – operator 生命周期管理器来管理 operator 的生命周期,以及可以发布你的 operator 到 OperatorHub。如今在 OperatorHub,你会看到 100 多个 operator 用于管理数据库、消息队列和监控工具。从生命周期空间来看,operator 可能是 Kubernetes 生态系统中发展最活跃的领域。
网络趋势 - Envoy
我选的另一个项目是 Envoy。服务网格接口规范的引入将使你更轻松地切换不同的服务网格实现。在部署上 Istio 对架构进行了一些整合。你不再需要为控制平面部署 7 个 Pod;现在,你只需要部署一次就可以了。更有趣的是在 Envoy 项目的数据平面上所正在发生的:越来越多的第 7 层协议被添加到 Envoy 中。
服务网格增加了对更多协议的支持,比如 MongoDB、ZooKeeper、MySQL、Redis,而最新的协议是 Kafka。我看到 Kafka 社区现在正在进一步改进他们的协议,使其对服务网格更加友好。我们可以预料将会有更紧密的集成、更多的功能。最有可能的是,会有一些桥接的能力。你可以从服务中在你的应用本地做一个 HTTP 调用,而代理将在后台使用 Kafka。你可以在应用外部,在 sidecar 中针对 Kafka 协议进行转换和加密。
另一个令人兴奋的发展是引入了 HTTP 缓存。现在 Envoy 可以进行 HTTP 缓存。你不必在你的应用中使用缓存客户端。所有这些都是在 sidecar 中透明地完成的。有了 tap 过滤器,你可以 tap 流量并获得流量的副本。最近,WebAssembly 的引入,意味着如果你要为 Envoy 编写一些自定义的过滤器,你不必用 C++ 编写,也不必编译整个 Envoy 运行时。你可以用 WebAssembly 写你的过滤器,然后在运行时进行部署。这些大多数还在进行中。它们不存在,说明数据平面和服务网格无意停止,仅支持 HTTP 和 gRPC。他们有兴趣支持更多的应用层协议,为你提供更多的功能,以实现更多的用例。最主要的是,随着 WebAssembly 的引入,你现在可以在 sidecar 中编写自定义逻辑。只要你没有在其中添加一些业务逻辑就可以了。
绑定趋势 - Apache Camel
Apache Camel 是一个用于集成的项目,它具有很多使用企业集成模式连接到不同系统的连接器。 比如 Camel version 3 就深度集成到了 Kubernetes 中,并且使用了我们到目前为止所讲的那些原语,比如 operator。
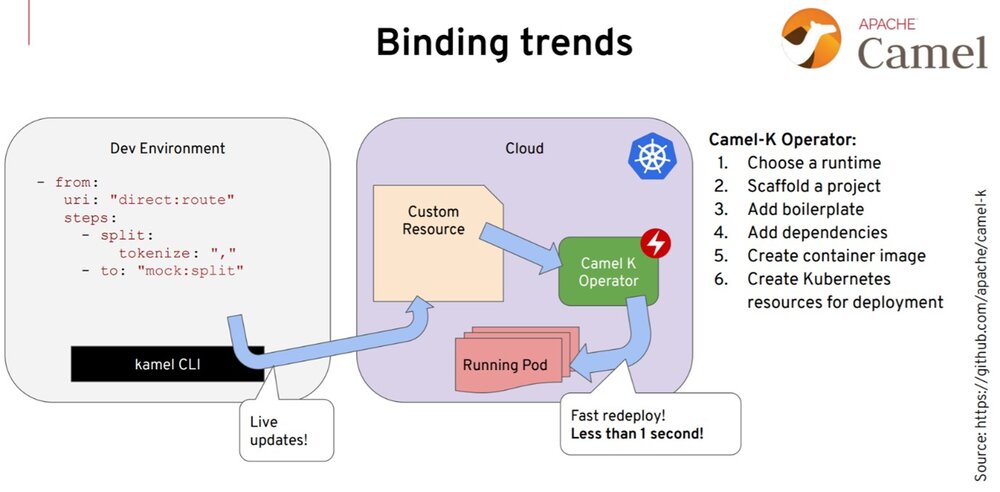
你可以在 Camel 中用 Java、JavaScript 或 YAML 等语言编写你的集成逻辑。最新的版本引入了一个 Camel operator,它在 Kubernetes 中运行并理解你的集成。当你写好 Camel 应用,将其部署到自定义资源中,operator 就知道如何构建容器或查找依赖项。根据平台的能力,不管是只用 Kubernetes,还是带有 Knative 的 Kubernetes,它都可以决定要使用的服务以及如何实现集成。在运行时之外有相当多的智能 – 包括 operator – 所有这些都非常快地发生。为什么我会说这是一个绑定的趋势?主要是因为 Apache Camel 提供的连接器的功能。这里有趣的一点是它如何与 Kubernetes 深度集成。
状态趋势 - Cloudstate
另一个我想讨论的项目是 Cloudstate 和与状态相关的趋势。Cloudstate 是 Lightbend 的一个项目,主要致力于无服务器和功能驱动的开发。最新发布的版本,正在使用 sidecar 和 operator 与 Kubernetes 进行深度集成。
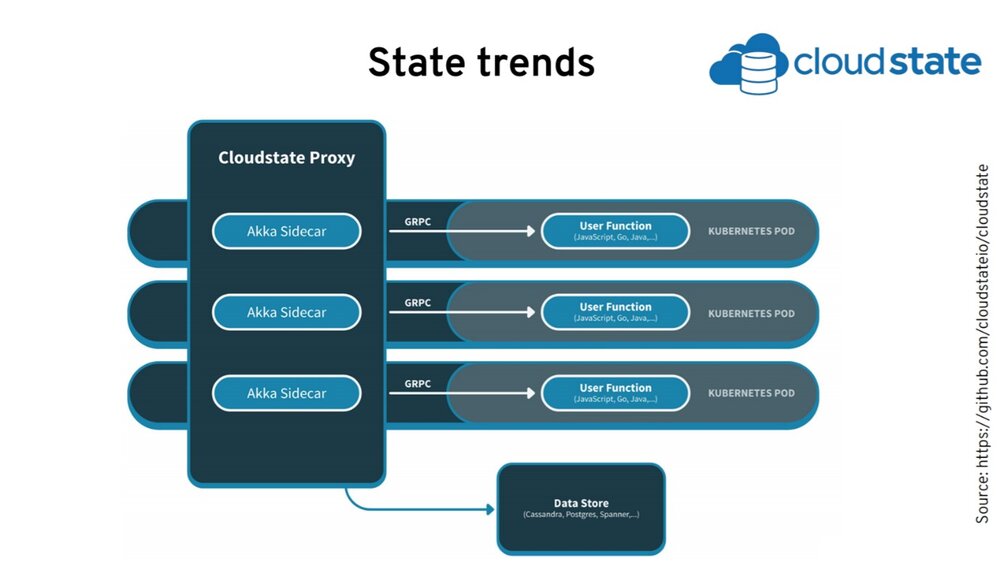
这个创意是,当你编写你的功能时,你在功能中要做的就是使用 gRPC 来获取状态并与之进行交互。整个状态管理在与其他 sidecar 群集的 sidear 中进行。它使你能够进行事件溯源、CQRS、键值查询、消息传递。
从应用程序角度来看,你并不了解所有这些复杂性。你所做的只是调用一个本地的 sidecar,而 sidecar 会处理这些复杂的事情。它可以在后台使用两个不同的数据源。而且它拥有开发人员所需的所有有状态抽象。
到目前为止,我们已经看到了云原生生态系统中的最新技术以及一些仍在进行中的开发。我们如何理解这一切?
多运行时微服务已经到来
如果你看微服务在 Kubernetes 上的样子,则将需要使用某些平台功能。此外,你将需要首先使用 Kubernetes 的功能进行生命周期管理。然后,很有可能透明地,你的服务会使用某些服务网格(例如 Envoy)来获得增强的网络功能,无论是流量路由、弹性、增强的安全性,甚至出于监控的目的。除此之外,根据你的场景和使用的工作负载可能需要 Dapr 或者 Knative。所有这些都代表了进程外附加的功能。剩下的就是编写业务逻辑,不是放在最上面而是作为一个单独的运行时来编写。未来的微服务很有可能将是由多个容器组成的这种多运行时。有些是透明的,有些则是非常明确的。
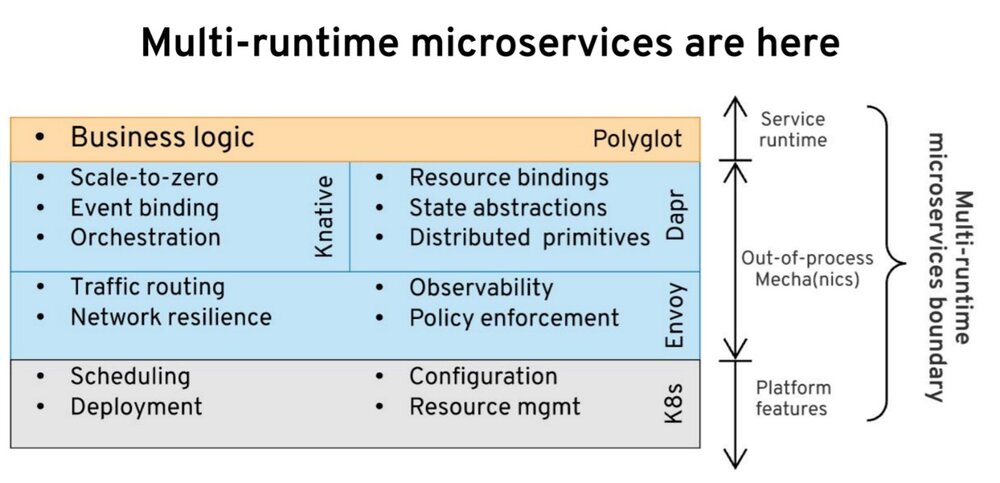
智能的 sidecar 和愚蠢的管道
如果更深入地看,那可能是什么样的,你可以使用一些高级语言编写业务逻辑。是什么并不重要,不必仅是 Java,因为你可以使用任何其他语言并在内部开发自定义逻辑。
你的业务逻辑与外部世界的所有交互都是通过 sidecar 发生的,并与平台集成进行生命周期管理。它为外部系统执行网络抽象,为你提供高级的绑定功能和状态抽象。sidecar 是你不需要开发的东西。你可以从货架上拿到它。你用一点 YAML 或 JSON 配置它,然后就可以使用它。这意味着你可以轻松地更新 sidecar,因为它不再被嵌入到你的运行时。这使得打补丁、更新变得更加更容易。它为我们的业务逻辑启用了多语言运行时。
微服务之后是什么?
这让我想到了最初的问题,微服务之后是什么?
如果我们看下架构的发展历程,应用架构在很高的层面上是从单体应用开始的。然而微服务给我们提供了如何把一个单体应用拆分成独立的业务域的指导原则。之后又出现了无服务器和功能即服务(FaaS),我们说过可以按操作将其进一步拆分,从而实现极高的可扩展性-因为我们可以分别扩展每个操作。
我想说的是 FaaS 并不是最好的模式 – 因为功能并不是实现合理的复杂服务的最佳模式,在这种情况下,当多个操作必须与同一个数据集进行交互时,你希望它们驻留在一起。可能是多运行时(我把它称为 Mecha 架构),在该架构中你将业务逻辑放在一个容器中,而所有与基础设施相关的关注点作为一个单独的容器存在。它们共同代表多运行时微服务。也许这是一个更合适的模型,因为它有更好的属性。
你可以获得微服务的所有好处。仍然将所有域和所有限界上下文放在一处。你将所有的基础设施和分布式应用需求放在一个单独的容器中,并在运行时将它们组合在一起。大概,现在最接近这种模型的是 Dapr。他们正在遵循这种模型。如果你仅对网络方面感兴趣,那么可能使用 Envoy 也会接近这种模型。
关于作者
Bilgin Ibryam 是红帽公司的产品经理和前架构师、提交人,并且是 Apache 软件基金会的成员。他是开源布道者,经常写博客、发表演讲,是 Kubernetes Patterns 和 Camel Design Patterns 书籍的作者。Bilgin 目前的工作主要集中在分布式系统、事件驱动架构以及可重复的云原生应用开发模式和实践上。请关注他 @bibryam 了解未来类似主题的更新。
9.6 - (2021)服务网格终极指南第二版——下一代微服务开发
前言
Service Mesh Ultimate Guide - Second Edition: Next Generation Microservices Development
https://www.infoq.com/articles/service-mesh-ultimate-guide-2e/
服务网格终极指南第二版——下一代微服务开发
https://cloudnative.to/blog/service-mesh-ultimate-guide-e2/
主要收获
- 了解采用服务网格技术的新兴架构趋势,特别是多云、多集群和多租户模式,如何在异构基础设施(裸机、虚拟机和 Kubernetes)中部署服务网格解决方案,以及从边缘计算层到网格的应用 / 服务连接。
- 了解服务网格生态系统中的一些新模式,如多集群服务网格、媒体服务网格(Media Service Mesh)和混沌网格,以及经典的微服务反模式,如 “死星(Death Star) “架构。
- 获取最新的关于在部署领域使用服务网格的创新总结,在 Pod(K8s 集群)和 VM(非 K8s 集群)之间进行快速实验、混乱工程和金丝雀部署。
- 探索服务网格扩展领域的创新,包括:增强身份管理,以确保微服务连接的安全性,包括自定义证书授权插件,自适应路由功能,以提高服务的可用性和可扩展性,以及增强 sidecar 代理。
- 了解操作方面即将出现的情况,如配置多集群功能和将 Kubernetes 工作负载连接到托管在虚拟机基础设施上的服务器,以及管理多集群服务网格中所有功能和 API 的开发者门户。
在过去的几年里,服务网格技术有了长足的发展。服务网格在各组织采用云原生技术方面发挥着重要作用。通过提供四种主要能力 —— 连接性、可靠性、可观察性和安全性,服务网格已经成为 IT 组织的技术和基础设施现代化工作的核心组成部分。服务网格使开发和运维团队能够在基础设施层面实现这些能力,因此,当涉及到跨领域的非功能需求时,应用团队不需要重新发明轮子。
自本文第一版于 2020 年 2 月发表以来,服务网格技术经历了重大创新,在不断发展的服务网格领域出现了一些新的架构趋势、技术能力和服务网格项目。
在过去的一年里,服务网格产品的发展远远超过了原有的 Kubernetes 解决方案,没有托管在 Kubernetes 平台上的应用无法利用服务网格。并非所有的组织都将其所有的业务和 IT 应用程序过渡到 Kubernetes 云平台。因此,自服务网格诞生以来,一直需要这项技术在不同的 IT 基础设施环境中工作。
随着微服务架构的不断采用,应用系统在云供应商、基础设施(Kubernetes、虚拟机、裸机服务器)、地域,甚至在服务网格集成环境中要管理的工作负载类型方面,都已实现解耦和分布式。
让我们从服务网格的历史开始说起,了解服务网格是如何产生的。
2016 年前后,“服务网格 " 这个词出现在微服务、云计算和 DevOps 的领域。Buoyant 团队在 2016 年用这个词来解释他们的产品 Linkerd。和云计算领域的许多概念一样,相关的模式和技术其实有很长的历史。
服务网格的到来主要是由于 IT 领域内的一场风暴。开发人员开始使用多语言(polyglot)方法构建分布式系统,并需要动态服务发现。运维部门开始使用短暂的基础设施,并希望优雅地处理不可避免的通信故障和执行网络策略。平台团队开始接受像 Kubernetes 这样的容器编排系统,并希望使用现代 API 驱动的网络代理(如 Envoy)在系统中和周围动态地路由流量。
本文旨在回答软件架构师和技术负责人的相关问题,如:什么是服务网格?我是否需要服务网格?如何评估不同的服务网格产品?
服务网格模式
服务网格模式专注于管理分布式软件系统中所有服务之间的通信。
背景介绍
该模式的背景有两个方面。首先,工程师们已经采用了微服务架构模式,并通过将多个(理想情况下是单一用途且可独立部署的)服务组合在一起构建他们的应用。第二,组织已经接受了云原生平台技术,如容器(如 Docker)、编排器(如 Kubernetes)和网关。
意图
服务网格模式试图解决的问题包括:
- 消除了将特定语言的通信库编译到单个服务中的需求,以处理服务发现、路由和应用层(第 7 层)非功能通信要求。
- 外部化服务通信配置,包括外部服务的网络位置、安全凭证和服务质量目标。
- 提供对其他服务的被动和主动监测。
- 在整个分布式系统中分布式地执行策略。
- 提供可观察性的默认值,并使相关数据的收集标准化。
- 启用请求记录
- 配置分布式追踪
- 收集指标
结构
服务网格模式主要侧重于处理传统上被称为 “东西向 “的基于远程过程调用(RPC)的流量:请求 / 响应类型的通信,源自数据中心内部,在服务之间传播。这与 API 网关或边缘代理相反,后者被设计为处理 “南北 “流量。来自外部的通信,进入数据中心内的一个终端或服务。
服务网格的特点
服务网格的实施通常会提供以下一个或多个功能:
- 规范化命名并增加逻辑路由,(例如,将代码级名称 “用户服务 " 映射到平台特定位置 “AWS-us-east-1a/prod/users/v4”。
- 提供流量整形和流量转移
- 保持负载均衡,通常采用可配置的算法
- 提供服务发布控制(例如,金丝雀释放和流量分割)
- 提供按请求的路由(例如,影子流量、故障注入和调试重新路由)。
- 增加基线可靠性,如健康检查、超时 / 截止日期、断路和重试(预算)。
- 通过透明的双向传输级安全(TLS)和访问控制列表(ACL)等策略,提高安全性
- 提供额外的可观察性和监测,如顶线指标(请求量、成功率和延迟),支持分布式追踪,以及 “挖掘” 和检查实时服务间通信的能力。
- 使得平台团队能够配置 " 理智的默认值”,以保护系统免受不良通信的影响。
服务网格的能力可分为以下四个方面:
- 连接性
- 可靠性
- 安全性
- 可观察性
让我们看看服务网格技术在这些领域都能提供哪些功能。
连接性
- 流量控制(路由,分流)
- 网关(入口、出口)
- 服务发现
- A/B 测试、金丝雀
- 服务超时、重试
可靠性
- 断路器
- 故障注入 / 混沌测试
安全性
- 服务间认证(mTLS)
- 证书管理
- 用户认证(JWT)
- 用户授权(RBAC)
- 加密
可观察性
- 监测
- 遥测、仪表、计量
- 分布式追踪
- 服务图表
服务网格架构:内部原理
服务网格由两部分组成:数据平面和控制平面。Matt Klein,Envoy Proxy 的作者,写了一篇关于 “ 服务网格数据平面与控制平面 “的深入探讨。
广义上讲,数据平面 “执行工作”,负责 “有条件地翻译、转发和观察流向和来自 [网络终端] 的每个网络数据包”。在现代系统中,数据平面通常以代理的形式实现,(如 Envoy、HAProxy 或 MOSN),它作为 “sidecar” 与每个服务一起在进程外运行。Linkerd 使用了一种 微型代理方法,该方法针对服务网格的使用情况进行了优化。
控制平面 “监督工作”,并将数据平面的所有单个实例 —— 一组孤立的无状态 sidecar 代理变成一个分布式系统。控制平面不接触系统中的任何数据包 / 请求,相反,它允许人类运维人员为网格中所有正在运行的数据平面提供策略和配置。控制平面还能够收集和集中数据平面的遥测数据,供运维人员使用。
控制平面和数据平面的结合提供了两方面的优势,即策略可以集中定义和管理,同时,同样的政策可以以分散的方式,在 Kubernetes 集群的每个 pod 中本地执行。这些策略可以与安全、路由、断路器或监控有关。
下图取自 Istio 架构文档,虽然标注的技术是 Istio 特有的,但这些组件对所有服务网格的实现都是通用的。

Istio 架构,展示了控制平面和代理数据平面的交互方式(由 Istio 文档提供)。
使用案例
服务网格可以实现或支持多种用例。
动态服务发现和路由
服务网格提供动态服务发现和流量管理,包括用于测试的流量影子(复制),以及用于金丝雀发布和 A/B 实验的流量分割。
服务网格中使用的代理通常是 “应用层 " 感知的(在 OSI 网络堆栈的第 7 层运行)。这意味着流量路由决策和指标的标记可以利用 HTTP 头或其他应用层协议元数据。
服务间通信可靠性
服务网格支持跨领域的可靠性要求的实施和执行,如请求重试、超时、速率限制和断路。服务网格经常被用来补偿(或封装)处理分布式计算的八个谬误。应该注意的是,服务网格只能提供 wire-level 的可靠性支持(如重试 HTTP 请求),最终服务应该对相关的业务影响负责,如避免多个(非幂等的)HTTP POST 请求。
流量的可观察性
由于服务网格处于系统内处理的每个请求的关键路径上,它还可以提供额外的 “可观察性”,例如请求的分布式追踪、HTTP 错误代码的频率以及全局和服务间的延迟。虽然在企业领域是一个被过度使用的短语,但服务网格经常被提议作为一种方法来捕获所有必要的数据,以实现整个系统内流量的统一界面视图。
通信安全
服务网格还支持跨领域安全要求的实施和执行,如提供服务身份(通过 x509 证书),实现应用级服务 / 网络分割(例如,“服务 A” 可以与 “服务 B “通信,但不能与 “服务 C “通信),确保所有通信都经过加密(通过 TLS),并确保存在有效的用户级身份令牌或 “护照 “。
反模式
当反模式的使用出现时,这往往是一个技术成熟的标志。服务网格也不例外。
太多的流量管理层次
当开发人员不与平台或运维团队协商,并在现在通过服务网格实现的代码中重复现有的通信处理逻辑时,就会出现这种反模式。例如,除了服务网格提供的 wire-level 重试策略外,应用程序还在代码中还实现了重试策略。这种反模式会导致重复的事务等问题。
服务网格银弹
在 IT 领域没有 “银弹 “这样的东西,但供应商有时会被诱惑给新技术贴上这个标签。服务网格不会解决微服务、Kubernetes 等容器编排器或云网络的所有通信问题。服务网格的目的只是促进服务件(东西向)的通信,而且部署和运行服务网格有明显的运营成本。
企业服务总线(ESB)2.0
在前微服务面向服务架构(SOA)时代,企业服务总线(ESB)实现了软件组件之间的通信系统。有些人担心 ESB 时代的许多错误会随着服务网格的使用而重演。
通过 ESB 提供的集中的通信控制显然有价值。然而,这些技术的发展是由供应商推动的,这导致了多种问题,例如:ESB 之间缺乏互操作性,行业标准的定制扩展(例如,将供应商的特定配置添加到 WS-* 兼容模式中),以及高成本。ESB 供应商也没有做任何事情来阻止业务逻辑与通信总线的集成和紧耦合。
大爆炸部署
在整个 IT 界有一种诱惑,认为大爆炸式的部署方法是最容易管理的方法,但正如 Accelerate 和 DevOps 报告的研究,事实并非如此。由于服务网格的全面推广意味着这项技术处于处理所有终端用户请求的关键路径上,大爆炸式的部署是非常危险的。
死星建筑
当企业采用微服务架构,开发团队开始创建新的微服务或在应用中利用现有的服务时,服务间的通信成为架构的一个关键部分。如果没有一个良好的治理模式,这可能会导致不同服务之间的紧密耦合。当整个系统在生产中出现问题时,也将很难确定哪个服务出现了问题。
如果缺乏服务沟通战略和治理模式,该架构就会变成所谓的 “死星架构”。
关于这种架构反模式的更多信息,请查看关于云原生架构采用的第一部分、第二部分和第三部分的文章。
特定领域的服务网格
服务网格的本地实现和过度优化有时会导致服务网格部署范围过窄。开发人员可能更喜欢针对自己的业务领域的服务网格,但这种方法弊大于利。我们不希望实现过于细化的服务网格范围,比如为组织中的每个业务或功能域(如财务、人力资源、会计等)提供专用的服务网格。这就违背了拥有像服务网格这样的通用服务协调解决方案的目的,即企业级服务发现或跨域服务路由等功能。
服务网格的实现和产品
以下是一份非详尽的当前服务网格实施清单。
- Linkerd (CNCF 毕业项目)
- Istio
- Consul
- Kuma(CNCF 沙盒项目)
- AWS App Mesh
- NGINX Service Mesh
- AspenMesh
- Kong
- Solo Gloo Mesh
- Tetrate Service Bridge
- Traefik Mesh(原名 Maesh)。
- Meshery
- Open Service MEsh(CNCF 沙盒项目)。
另外,像 DataDog 这样的其他产品也开始提供与 Linkerd、Istio、Consul Connect 和 AWS App Mesh 等服务网格技术的集成。
服务网格对比
服务网格领域的发展极为迅速,因此任何试图创建比较的努力都可能很快变得过时。然而,确实存在一些比较。应该注意了解来源的偏见(如果有的话)和进行比较的日期。
- https://layer5.io/landscape
- https://kubedex.com/istio-vs-linkerd-vs-linkerd2-vs-consul/(截至 2021 年 8 月的正确数据)
- https://platform9.com/blog/kubernetes-service-mesh-a-comparison-of-istio-linkerd-and-consul/(截至 2019 年 10 月的最新情况)
- https://servicemesh.es/ (最后发表于 2021 年 8 月)
InfoQ 一直建议服务网格的采用者对每个产品进行自己的尽职调查和试验。
服务网格教程
对于希望试验多服务网格的工程师或建筑师来说,可以使用以下教程、游戏场和工具。
- Layer 5 Meshery—— 多网格管理平面
- Solo 的 Gloo Mesh—— 服务网格编排平台
- KataCoda Istio 教程
- Consul 服务网格教程
- Linkerd 教程
- NGINX 服务网格教程
- Istio 基础教程
服务网格的历史
自 2013 年底 Airbnb 发布 SmartStack,为新兴的 “ 微服务 “风格架构提供进程外服务发现机制(使用 HAProxy)以来,InfoQ 一直在跟踪这个我们现在称之为 服务网格的话题。许多之前被贴上 “独角兽 “标签的组织在此之前就在研究类似的技术。从 21 世纪初开始,谷歌就在开发其 Stubby RPC 框架,该框架演变成了 gRPC,以及 谷歌前端(GFE)和全局软件负载均衡器(GSLB),在 Istio 中可以看到它们的特质。在 2010 年代早期,Twitter 开始了 Scala 驱动的 Finagle 的工作,Linkerd 服务网格由此产生。
2014 年底,Netflix 发布了一整套基于 JVM 的实用程序,包括 Prana,一个 “sidecar “程序,允许用任何语言编写的应用服务通过 HTTP 与库的独立实例进行通信。2016 年,NGINX 团队开始谈论 “Fabric 模型 “,这与服务网格非常相似,但需要使用他们的商业 NGINX Plus 产品来实现。另外,Linkerd v0.2 在 2016 年 2 月发布,尽管该团队直到后来才开始称它为服务网格。
服务网格历史上的其他亮点包括 2017 年 5 月的 Istio、2018 年 7 月的 Linkerd 2.0、2018 年 11 月的 Consul Connect 和 Gloo Mesh、2019 年 5 月的 服务网格接口(SMI),以及 2019 年 9 月的 Maesh(现在叫 Traefik Mesh)和 Kuma。
即使是在独角兽企业之外出现的服务网格,如 HashiCorp 的 Consul,也从上述技术中获得了灵感,通常旨在实现 CoreOS 提出的 “GIFEE “概念;所有人可用的 Google 基础设施(Google infrastructure for everyone else)。
为了深入了解现代服务网格概念的演变历史,Phil Calçado 写了一篇全面的文章 “ 模式:服务网格 “。
服务网格标准
尽管在过去的几年里,服务网格技术年复一年地发生着重大转变,但服务网格的标准还没有跟上创新的步伐。
使用服务网格解决方案的主要标准是服务网格接口(SMI)。服务网格接口是在 Kubernetes 上运行的服务网格的一个规范。它本身并没有实现服务网格,而是定义了一个通用的标准,可以由各种服务网格供应商来实现。
SMI API 的目标是提供一套通用的、可移植的服务网格 API,Kubernetes 用户可以以一种与提供者无关的方式使用。通过这种方式,人们可以定义使用服务网格技术的应用程序,而不需要与任何特定的实现紧密结合。
SMI 基本上是一个 Kubernetes 自定义资源定义(CRD)和扩展 API 服务器的集合。这些 API 可以安装到任何 Kubernetes 集群,并使用标准工具进行操作。为了激活这些 API,需要在 Kubernetes 集群中运行一个 SMI 提供者。
SMI 规范既允许终端用户的标准化,也允许服务网格技术提供商的创新。SMI 实现了灵活性和互操作性,并涵盖了最常见的服务网格功能。目前的规范组件集中在服务网格能力的连接方面。API 规范包括以下内容。
- 流量访问控制
- 流量指标
- 流量规格
- 流量分割
目前的 SMI 生态系统包括广泛的服务网格,包括 Istio、Linkerd、Consul Connect、Gloo Mesh 等。
SMI 规范是在 Apache License 2.0 版本下许可的。
如果你想了解更多关于 SMI 规范及其 API 细节,请查看以下链接。
- 核心规范(当前版本:0.6.0)
- 规范 Github 项目
- 如何贡献
服务网格基准测试
服务网格性能是一个捕捉基础设施容量、服务网配置和工作负载元数据细节的标准。SMP 规范用于捕捉以下细节。
- 环境和基础设施细节
- 节点的数量和规模,编排器
- 服务网格和它的配置
- 工作量 / 应用细节
- 进行统计分析以确定性能特征
来自 Linkerd 团队的 William Morgan 写了关于 Linkerd 和 Istio 的性能基准测试。还有一篇来自 2019 年的文章,介绍了 Istio 关于服务网格性能基准测试的最佳实践。
重要的是要记住,就像其他性能基准测试一样,你不应该对任何这些外部出版物投入过多的注意力,特别是产品供应商发表的文章。该在你的服务器环境中设计和执行你自己的性能测试,以验证哪个具体产品适合你的应用程序的业务和非功能要求。
探索服务网格的未来
Kasun Indrasiri 探讨了 “ 为事件驱动的消息传递使用服务网格的潜力 “,他在其中讨论了在服务网格中实现消息传递支持的两种主要的新兴架构模式:协议代理 sidecar 和 HTTP 桥接 sidecar。这是服务网格社区中一个活跃的发展领域,在 Envoy 中支持 Apache Kafka 的工作引起了相当多的关注。
Christian Posta 之前在 “Towards a Unified, Standard API for Consolidating Service Meshes 中写过关于服务网格使用标准化的尝试。这篇文章还讨论了 2019 年微软和合作伙伴在 KubeCon EU 上宣布的服务网格接口(SMI)。SMI 定义了一套通用和可移植的 API,旨在为开发人员提供不同服务网格技术的互操作性,包括 Istio、Linkerd 和 Consul Connect。
将服务网格与平台结构整合的主题可以进一步分为两个子主题。
首先,正在进行的工作是减少由服务网格数据平面引入的网络开销。这包括数据平面开发工具包(DPDK),它是一个用户空间应用程序,“绕过了 Linux 内核网络堆栈,直接与网络硬件对话”。还有 Cilium 团队的基于 Linux 的 BPF 解决方案,它利用 Linux 内核中的扩展伯克利包过滤器(eBPF)功能来实现 “非常有效的网络、策略执行和负载均衡功能”。另一个团队正在用网络服务网格(Network Service Mesh)将服务网格的概念映射到 L2/L3 有效载荷,试图 “以云原生的方式重新想象网络功能虚拟化(NFV)"。
其次,有多项举措将服务网格与公共云平台更紧密地结合在一起,从 AWS App Mesh、GCP Traffic Director 和 Azure Service Fabric Mesh 的发布可见端倪。
Buoyant 团队致力于为服务网格技术开发有效的以人为本的控制平面。他们最近发布了 Buoyant Cloud,一个基于 SaaS 的 “团队控制平面”,用于平台团队操作 Kubernetes。这个产品将在下面的章节中详细讨论。
自去年以来,在服务网格领域也有一些创新。
多云、多集群、多租户服务网格
近年来,不同组织对云的采用已经从单一的云解决方案(私有云或公共云)转变为由多个不同供应商(AWS、谷歌、微软 Azure 等)支持的基于多云(私有、公共和混合)的新基础设施。同时,需要支持不同的工作负载(交易、批处理和流媒体),这对实现统一的云架构至关重要。
这些业务和非功能需求反过来又导致需要在异构基础设施(裸机、虚拟机和 Kubernetes)中部署服务网格解决方案。服务网格需要相应转变,以支持这些不同的工作负载和基础设施。
像 Kuma 和 Tetrate Service Bridge 这样的技术支持多网格控制平面,以使业务应用在多集群和多云服务网格环境中工作。这些解决方案抽象出跨多个区域的服务网格策略的同步以及跨这些区域的服务连接(和服务发现)。
多集群服务网格技术的另一个新趋势是需要从边缘计算层(物联网设备)到网格层的应用 / 服务连接。
媒体服务网格
思科系统公司开发的媒体流网格(Media Streaming Mesh)或媒体服务网格,用于协调实时应用程序,如多人游戏、多方视频会议或在 Kubernetes 云平台上使用服务网格技术的 CCTV 流。这些应用正越来越多地从单体应用转向微服务架构。服务网格可以通过提供负载均衡、加密和可观察性等功能来帮助应用程序。
混沌网格
Chaos Mesh 是 CNCF 托管的项目,是一个开源的、云原生的混沌工程平台,用于托管在 Kubernetes 上的应用程序。虽然不是直接的服务网格实现,但 Chaos Mesh 通过协调应用程序中的故障注入行为来实现混沌工程实验。故障注入是服务网格技术的一个关键能力。
Chaos Mesh 隐藏了底层的实现细节,因此应用开发者可以专注于实际的混沌实验。Chaos Mesh 可以和服务网格一起使用。请看这个用例,该团队如何使用 Linkerd 和 Chaos Mesh 来为他们的项目进行混沌实验。
服务网格作为一种服务
一些服务网格供应商,如 Buoyant,正在提供管理服务网格或 “服务网格作为一种服务 “的解决方案。今年早些时候,Buoyant 宣布公开测试发布一个名为 Buoyant Cloud 的 SaaS 应用程序,允许客户组织利用 Linkerd 服务网格的按需支持功能来管理服务网格。
Buoyant Cloud 解决方案提供的一些功能包括如下:
- 自动跟踪 Linkerd 数据平面和控制平面的健康状况
- 在 Kubernetes 平台上管理跨 pod、代理和集群的服务网格生命周期和版本
- 以 SRE 为重点的工具,包括服务水平目标(SLO)、工作负荷黄金指标跟踪和变更跟踪
网络服务网格(NSM)
网络服务网格(NSM)是云原生计算基金会的另一个沙盒项目,提供了一个混合的、多云的 IP 服务网格。NSM 实现了网络服务连接、安全和可观察性等功能,这些都是服务网格的核心特征。NSM 与现有的容器网络接口(CNI)实现协同工作。
服务网格扩展
服务网格扩展是另一个已经看到很多创新的领域。服务网格扩展的一些发展包括:
- 增强的身份管理,以确保微服务连接的安全,包括自定义证书授权插件
- 自适应路由功能,以提高服务的可用性和可扩展性
- 加强 sidecar 代理权
服务网格业务
采用服务网格的另一个重要领域是服务网格生命周期的运维方面。操作方面 —— 如配置多集群功能和将 Kubernetes 工作负载连接到虚拟机基础设施上托管的服务器,以及管理多集群服务网格中所有功能和 API 的开发者门户 —— 将在生产中服务网格解决方案的整体部署和支持方面发挥重要作用。
常见问题
什么是服务网格?
服务网格是一种在分布式(可能是基于微服务的)软件系统内管理所有服务对服务(东西向)流量的技术。它既提供以业务为重点的功能操作,如路由,也提供非功能支持,如执行安全策略、服务质量和速率限制。它通常(尽管不是唯一的)使用 sidecar 代理来实现,所有服务都通过 sidecar 代理进行通信。
服务网格与 API 网关有什么不同?
关于服务网格的定义,见上文。
另一方面,API 网关管理进入集群的所有入口(南北)流量,并为跨功能的通信要求提供额外支持。它作为进入系统的单一入口点,使多个 API 或服务凝聚在一起,为用户提供统一的体验。
如果我正在部署微服务,我是否需要服务网格?
不一定。服务网格增加了技术栈的操作复杂性,因此通常只有在组织在扩展服务与服务之间的通信方面遇到困难,或者有特定的用例需要解决时才会部署。
我是否需要服务网格来实现微服务的服务发现?
不,服务网格提供了实现服务发现的一种方式。其他解决方案包括特定语言的库(如 Ribbon 和 Eureka 或 Finagle)。
服务网格是否会给我的服务之间的通信增加开销 / 延迟?
是的,当一个服务与另一个服务进行通信时,服务网格至少会增加两个额外的网络跳数(第一个是来自处理源的出站连接的代理,第二个是来自处理目的地的入站连接的代理)。然而,这个额外的网络跳转通常发生在 localhost 或 loopback 网络接口上,并且只增加了少量的延迟(在毫秒级)。实验和了解这对目标用例是否是一个问题,应该是服务网格分析和评估的一部分。
服务网格不应该是 Kubernetes 或应用程序被部署到的 “云原生平台” 的一部分吗?
潜在的。有一种说法是在云原生平台组件内保持关注点的分离(例如,Kubernetes 负责提供容器编排,而服务网格负责服务间的通信)。然而,正在进行的工作是将类似服务网格的功能推向现代平台即服务(PaaS)产品。
我如何实施、部署或推广服务网格?
最好的方法是分析各种服务网格产品(见上文),并遵循所选网格特有的实施准则。一般来说,最好是与所有利益相关者合作,逐步将任何新技术部署到生产中。
我可以建立自己的服务网格吗?
是的,但更相关的问题是,你应该吗?建立一个服务网格是你组织的核心竞争力吗?你能否以更有效的方式为你的客户提供价值?你是否也致力于维护你自己的网络,为安全问题打补丁,并不断更新它以利用新技术?由于现在有一系列的开源和商业服务网格产品,使用现有的解决方案很可能更有效。
在一个软件交付组织内,哪个团队拥有服务网格?
通常,平台或运维团队拥有服务网格,以及 Kubernetes 和持续交付管道基础设施。然而,开发人员将配置服务网格的属性,因此这两个团队应该紧密合作。许多企业正在追随云计算先锋的脚步,如 Netflix、Spotify 和谷歌,并正在创建内部平台团队,为以产品为重点的全周期开发团队提供工具和服务。
Envoy 是一个服务网格吗?
Envoy 是一个云原生代理,最初是由 Lyft 团队设计和构建的。Envoy 经常被用作服务网格的数据平面。然而,为了被认为是一个服务网格,Envoy 必须与控制平面一起使用,这样才能使这些技术集合成为一个服务网格。控制平面可以是简单的集中式配置文件库和指标收集器,也可以是全面 / 复杂的 Istio。
Istio 和 “服务网格 " 这两个词可以互换使用吗?
不,Istio 是服务网格的一种。由于 Istio 在服务网格类别出现时很受欢迎,一些人将 Istio 和服务网格混为一谈。这个混淆的问题并不是服务网格所独有的,同样的挑战发生在 Docker 和容器技术上。
我应该使用哪个服务网格?
这个问题没有唯一的答案。工程师必须了解他们当前的需求,以及他们的实施团队的技能、资源和时间。上面的服务网格比较链接将提供一个良好的探索起点,但我们强烈建议企业至少尝试两个网格,以了解哪些产品、技术和工作流程最适合他们。
我可以在 Kubernetes 之外使用服务网吗?
是的。许多服务网格允许在各种基础设施上安装和管理数据平面代理和相关控制平面。HashiCorp 的 Consul 是最知名的例子,Istio 也被实验性地用于 Cloud Foundry。
其他资源
10 - Servicemesh资料收集
官方资料
暂无。
社区资料
- ServiceMesh中国社区: 由我和宋净超发起的service mesh中国技术社区,是目前国内最权威的service mesh技术社区,汇聚了目前国内对这个新技术有兴趣的大批技术人员。是Istio官方合作中文社区,组织翻译了Istio中文文档并负责日常维护。目前已停止维护。
- servicemesh.io网站: 之前有一个简单网站,还有邮件订阅,现在直接定向到 https://buoyant.io/service-mesh-manifesto/