1 - CNCF Serverless Whitepaper v1.0
CNCF Serverless Whitepaper v1.0
备注:内容翻译自 https://github.com/cncf/wg-serverless/tree/master/whitepapers/serverless-overview
本文描述了新型云原生计算模型,该模型由新兴的“serverless”架构及其支持平台实现。它定义了serverless计算的内容,重点介绍了serverless计算的用例和成功示例,并展示了serverless计算如何与其他云应用程序开发模型(如Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS),容器编排或Container-as-a-Service(CaaS)。
本文包含对通用serverless平台机制的逻辑描述,还有和这些平台相关的编程模型和消息格式,但它没有规定标准。它介绍了几种行业serverless平台及其功能,但不推荐特定实现。
最后,还有关于CNCF如何推进云原生计算的serverless计算的一系列建议。
工作组主席/TOC发起人: Ken Owens (Mastercard)
作者 (按姓氏字母顺序排列):
Sarah Allen (Google), Chris Aniszczyk (CNCF), Chad Arimura (Oracle), Ben Browning (Red Hat), Lee Calcote (SolarWinds), Amir Chaudhry (Docker), Doug Davis (IBM), Louis Fourie (Huawei), Antonio Gulli (Google), Yaron Haviv (iguazio), Daniel Krook (IBM), Orit Nissan-Messing (iguazio), Chris Munns (AWS), Ken Owens (Mastercard), Mark Peek (VMWare), Cathy Zhang (Huawei)
其他贡献者 (按姓氏字母顺序排列):
Kareem Amin (Clay Labs), Amir Chaudhry (Docker), Sarah Conway (Linux Foundation), Zach Corleissen (Linux Foundation), Alex Ellis (VMware), Brian Grant (Google), Lawrence Hecht (The New Stack), Lophy Liu, Diane Mueller (Red Hat), Bálint Pató, Peter Sbarski (A Cloud Guru), Peng Zhao (Hyper)
Serverless 计算
什么是serverless计算?
Serverless计算是指构建和运行不需要服务器管理的应用程序的概念。它描述了一种更细粒度的部署模型,应用程序捆绑一个或多个function,上载到平台,然后执行,缩放和计费,以响应当前所需的确切需求。
Serverless计算并不意味着我们不再使用服务器来托管和运行代码;这也不意味着不再需要运维工程师。相反,它指的是serverless计算的消费者不再需要花费时间和资源来进行服务器配置,维护,更新,扩展和容量规划。相反,所有这些任务和功能都由serverless平台处理,并完全从开发人员和IT/运维团队中抽象出来。因此,开发人员专注于编写应用程序的业务逻辑。运维工程师能够将重点更多的放到关键业务任务上。
Serverless有两个主要角色:
- Developer/开发人员:为serverless平台编写代码并从中获益,serverless平台提供了这样的视角:没有服务器,而代码始终在运行。
- Provider/供应商:为外部或内部客户部署serverless平台。
运行serverless平台仍然需要服务器。供应商需要管理服务器(或虚拟机和容器)。即使在空闲时,供应商也会有一些运行平台的成本。自托管系统仍然可以被视为serverless:通常一个团队充当供应商,另一个团队充当开发人员。
Serverless计算平台可以提供以下中的一个或两个:
- Functions-as-a-Service (FaaS),通常提供事件驱动计算。开发人员使用由事件或HTTP请求触发的function来运行和管理应用程序代码。 开发人员将代码的小型单元部署到FaaS,这些代码根据需要作为离散动作执行,无需管理服务器或任何其他底层基础设施即可进行扩展。
- Backend-as-a-Service (BaaS),它是基于API的第三方服务,可替代应用程序中的核心功能子集。因为这些API是作为可以自动扩展和透明操作的服务而提供的,所以对于开发人员表现为是serverless。
Serverless产品或平台为开发人员带来以下好处:
-
零服务器运维:serverless通过消除维护服务器资源所涉及的开销,显着改变了运行软件应用程序的成本模型。
-
无需配置,更新和管理服务器基础设施。管理服务器,虚拟机和容器对于公司而言是一项重大费用,其中包括人员,工具,培训和时间。Serverless大大减少了这种费用。
-
灵活的可扩展性:serverless的FaaS或BaaS产品可以即时而精确地扩展,以处理每个单独的传入请求。对于开发人员来说,serverless平台没有“预先计划容量”的概念,也不需要配置“自动缩放”的触发器或规则。缩放可以在没有开发人员干预的情况下自动进行。完成请求处理后,serverless FaaS会自动收缩计算资源,因此不会有空闲容量。
-
-
闲置时无计算成本:从消费者的角度来看,serverless产品的最大好处之一是空闲容量不会产生任何成本。例如,serverless计算服务不对空闲虚拟机或容器收费; 换句话说,当代码没有运行或者没有进行有意义的工作时,不收费。 对于数据库,数据库引擎容量空闲等待请求时无需收费。当然,这不包括其他成本,例如有状态存储成本或添加的功能/功能/特性集。
Serverless技术简史
虽然按需或“花多少用多少”模式的概念可追溯到2006年和一个名为Zimki的平台,但serverless一词的第一次使用是2012年来自Iron.io的IronWorker产品 ,一个基于容器的分布式按需工作平台。
从那以后,公共云和私有云都出现了更多serverless实现。首先是BaaS产品,例如2011年的Parse和2012年的Firebase(分别由Facebook和谷歌收购)。2014年11月,AWS Lambda推出,2016年初在Bluemix上宣布了IBM OpenWhisk on Bluemix(现在是IBM Cloud Functions,其核心开源项目成为Apache OpenWhisk),Google Cloud Functions和Microsoft Azure Functions。华为Function Stage于2017年推出。还有许多开源serverless框架。每个框架(公共和私有)都具有独特的语言运行时和服务集,用于处理事件和数据。
这只是几个例子; 有关更完整和最新的列表,请参阅 Serverless Landscape 文档。Detail View: Serverless Processing Model 部分包含有关整个FaaS模型的更多详细信息。
Serverless用例
虽然serverless计算广泛使用,但它仍然相对较新。通常,当工作负载为以下情况时,应将serverless方法视为首选:
- 异步,并发,易于并行化为独立的工作单元
- 不经常或有零星的需求,在扩展要求方面存在巨大的,不可预测的差异
- 无状态,短暂的,对瞬间冷启动时间没有重大需求
- 在业务需求变更方面具有高度动态性,需要加快开发人员的速度
例如,对于常见的基于HTTP的应用程序,在自动扩展和更细粒度的成本模型方面有明显的优势。也就是说,使用serverless平台可能会有一些权衡。 例如,如果function的实例数下降到零,则在一段不活动时间后function启动可能会导致性能下降。因此,选择是否采用serverless架构需要仔细查看计算模型的功能性和非功能性方面。
不适合IaaS,PaaS或CaaS解决方案的非HTTP中心和非弹性规模工作负载现在可以利用serverless架构的按需性质和高效成本模型。其中一些工作负载包括:
- 执行逻辑以响应数据库更改(insert, update, trigger, delete)
- 对IoT传感器输入消息(例如MQTT消息)执行分析
- 流处理(分析或修改动态数据)
- 管理单次提取,转换和加载的作业,这些作业需要在短时间内进行大量处理(ETL)
- 通过聊天机器人界面提供认知计算(异步,但有关联)
- 调度执行时间很短的任务,例如cron或批处理样式调用
- 服务于机器学习和AI模型(检索一个或多个数据元素,如表格,NLP或图像,并与预先学习的数据模型匹配,以识别文本,面孔,异常等)
- 持续集成pipeline,按需为构建作业提供资源,而不是保留构建从属主机池等待作业分派
本节介绍serverless架构优秀的现有和新兴工作负载和用例。它还包括从早期成功案例中提取的早期结果,模式和最佳实践的详细信息。
这些场景中的每一个都显示了serverless架构如何解决技术问题,即Iaas,PaaS或CaaS效率低下或无法实现。这些例子是:
- 在没有按需模型的情况下,有效解决了一个全新的问题
- 更有效地解决了传统的云问题(性能,成本)
- 显示“大”的维度,无论是处理的数据大小还是处理的请求
- 通过低错误率的自动缩放(向上和向下)来显示弹性
- 以前所未有的速度(从天到小时)为市场带来了解决方案
多媒体处理
一个常见的用例,也是最早具体化的用例之一,是响应新文件上传执行一些转换过程的函数。 例如,如果将图像上载到诸如Amazon S3的对象存储服务,则该事件触发函数,用于创建图像的缩略图版本并将其存储回另一个对象存储桶或Database-as-a-Service。 这是一个相当原子化,可并行化的计算任务示例,该计算任务不经常运行并根据需求进行伸缩。
例子包括:
-
Santander 使用serverless function构建了一个概念验证,使用光学字符识别来处理移动支票存款。 这种类型的工作量变化很大,发薪日的处理需求 - 每两周一次 - 可能比支付期的大部分空闲时间大几倍。
-
通过将 每个视频帧通过图像识别服务 来自动分类电影,以提取演员,情感和对象; 或处理灾区的无人机镜头以估计损坏的程度。
数据库更改或更改数据捕获(CDC)
在此场景中,当从数据库插入,修改或删除数据时调用function。在这种情况下,它的功能类似于传统的SQL触发器,几乎就像是与主同步流并行的副作用或动作。其结果是执行一个异步逻辑,可以修改同一个数据库中的某些内容(例如记录到审计表),或者依次调用外部服务(例如发送电子邮件)或更新其他数据库,例如 DB CDC(更改数据捕获)用例的情况。 由于业务需要和处理变更的服务分布的原因,这些用例的频率以及对原子性和一致性的需要可能不同。
例子包括:
-
审核对数据库的更改,或确保它们满足特定质量或分析标准以进行可接受的更改。
-
在输入数据时或之后不久自动将数据翻译为其他语言。
IoT/物联网传感器输入消息
随着连接到网络的自主设备的爆炸式增加,额外的流量体积庞大,并且使用比HTTP更轻量级的协议。 高效的云服务必须能够快速响应消息并扩展以响应其扩散或突然涌入的消息。Serverless功能可以有效地管理和过滤来自IoT设备的MQTT消息。 它们既可以弹性扩展,也可以屏蔽负载下游的其他服务。
例子包括:
-
GreenQ的卫生用例(垃圾互联网),根据垃圾箱的相对饱满度来优化卡车取件路线。
-
在物联网设备(如AWS Greengrass)上使用serverless来收集本地传感器数据,对其进行规范化,与触发器进行比较,并将事件推送到聚合单元/云。
大规模流处理
另一种非事务性,非请求/响应类型的工作负载是在可能无限的消息流中处理数据。 函数可以连接到消息源,而消息必须从事件流中读取和处理。 鉴于高性能,高弹性和计算密集型处理工作负载,这对于serverless而言非常重要。 在许多情况下,流处理需要将数据与一组上下文对象(在NoSQL或in-mem DB中)进行比较,或者将数据从流聚合并存储到对象或数据库系统中。
例子包括:
-
Mike Roberts有一个很好的 Java/AWS Kinesis 示例 ,可以有效地处理数十亿条消息。
-
SnapChat 在Google AppEngine上使用serverless 处理邮件。
聊天机器人
与人类交互不一定需要毫秒级别的响应时间,并且在许多方面,稍微延迟让回复人类的机器人对话感觉更自然。因此,等待从冷启动加载function的初始等待时间可能是可接受的。当添加到Facebook,WhatsApp或Slack等流行的社交网络时,机器人可能还需要具有极高的可扩展性,因此在PaaS或IaaS模型中预先设置一个永远在线的守护程序,以预测突然或高峰需求,可能不会有作为serverless方法的高效或成本效益。
例子包括:
-
支持和销售机器人插入到大型社交媒体服务,如Facebook或其他高流量网站。
-
消息应用程序Wuu使用Google Cloud Functions使用户能够创建和共享在数小时或数秒内消失的内容。
-
另请参阅下面的HTTP REST API和Web应用程序。
批处理作业或计划任务
每天只需几分钟就能以异步方式进行强大的并行计算,IO或网络访问的作业非常适合serverless。作业可以在以弹性方式运行时有效地消费他们所需的资源,并且在不被使用的当天剩余时间内不会产生资源成本。
例子包括:
- 计划任务可以是每晚运行的备份作业。
- 并行发送许多电子邮件的作业会扩展function实例。
HTTP REST API和Web应用程序
传统的请求/响应工作负载仍然非常适合serverless,无论工作负载是静态网站还是使用JavaScript或Python等编程语言按需生成响应。即使它们可能会为第一个用户带来启动成本,但在其他计算模型中存在这种延迟的先例,例如将JavaServer Page初始编译为servlet,或者启动新的JVM来处理额外的负载。好处是单个REST调用(例如,微服务中的GET,POST,UPDATE和DELETE 4端点中的每一个)可以独立扩展并单独计费,即使它们共享公共数据后端。
例子包括:
- 移植到serverless架构的澳大利亚人口普查显示了开发速度,成本改进和自动扩展。
- “如何通过无服务器将我的AWS账单削减90%。”
- AutoDesk示例:“成本只占传统云方法的一小部分(约1%)。”
- 在线编码/教育(考试,测试等)在事件驱动的环境中运行训练代码,并基于与该训练的结果和预期结果的比较向用户提供反馈。Serverless平台根据需要运行应答检查并根据需要进行扩展,仅在代码运行的时间内需要付费。
移动后端
使用serverless进行移动后端任务也很有吸引力。它允许开发人员在BaaS API之上构建REST API后端工作负载,因此他们可以花时间优化移动应用程序,而不是扩展后端。 例子包括:优化视频游戏的图形,而不是在游戏成为病毒式打击时投资服务器; 或者对于需要快速迭代以发现产品/市场适合性,或者上市时间至关重要的消费者业务应用程序。另一个示例是批量通知用户或程序其他异步任务以获得离线优先体验。
例子包括:
- 需要少量服务器端逻辑的移动应用程序; 开发人员可以将精力集中在原生代码开发上。
- 使用已配置的安全策略(例如Firebase身份验证/规则或Amazon Cognito)通过事件触发的serverless计算使用直接从移动设备访问BaaS的移动应用程序。
- “Throwaway”或短期使用的移动应用程序,例如大型会议的调度应用程序,在会议前后的周末几乎没有需求,但需要极大的扩展和收缩; 在周一和周二早上的活动过程中根据时间表查看要求,然后在午夜时分回到主题演讲。
业务逻辑
当与管理和协调function一起部署时,在业务流程中执行一系列步骤的微服务工作负载的编排是serverless计算的另一个好用例。执行特定业务逻辑的function(例如订单请求和批准,股票交易处理等)可以与有状态管理器一起安排和协调。来自客户端门户的事件请求可以由这样的协调function提供服务,并传递给适当的serverless function。
例子包括:
交易台,处理股票市场交易并处理客户的交易订单和确认。协调器使用状态图管理交易。初始状态接受来自客户端门户的交易请求,并将请求传递给微服务function以解析请求并验证客户端。随后的状态根据买入或卖出交易指导工作流,验证基金余额,股票代码等,并向客户发送确认。在从客户端接收到确认请求事件时,后续状态调用管理交易执行的function,更新账户,并通知客户完成交易。
持续集成管道
传统的CI管道包括一个构建从属主机池,它们处于空闲等待以便分派作业。Serverless是一种很好的模式,可以消除对预配置主机的需求并降低成本。构建作业由新代码提交或PR合并触发。 调用function来运行构建和测试用例,仅在所需的时间内执行,并且在未使用时不会产生成本。这降低了成本,并可通过自动扩展来减少瓶颈以满足需求。
例子包括:
Serverless vs. 其他云原生技术
大多数应用程序开发人员在寻找托管其云原生应用程序的平台时可能会考虑三种主要的开发和部署模型。每个模型都有自己的一组不同的实现(无论是开源项目,托管平台还是本地产品)。这三种型号通常建立在容器技术的基础上,为了密度,性能,隔离和包装特性,但容器化并不是要求。
为了增加抽象,远离运行其代码的实际基础设施,并且更加关注开发的业务逻辑,它们是Container Orchestration(或Containers-as-a-Service),Platform-as-a-Service和Serverless(Functions-as-a-Service)。所有这些方法都提供了部署云原生应用程序的方法,但它们根据其预期的开发人员和工作负载类型确定了不同功能和非功能方面的优先级。以下部分列出了每个模型的一些关键特征。
请记住,没有任何银弹可以满足所有云原生开发和部署挑战。将特定工作负载的需求与每种常见的云原生开发技术的优缺点相匹配非常重要。同样重要的是要考虑应用程序的子组件可能更适合于一种方法而不是另一种方法,因此可以采用混合方式。
Container Orchestration/容器编排
Containers-as-a-Service(CaaS) - 保持对基础设施的完全控制并获得最大的可移植性。 示例:Kubernetes,Docker Swarm,Apache Mesos。
像Kubernetes,Swarm和Mesos这样的容器编排平台允许团队构建和部署可移植应用程序,具有灵活性和对配置的控制,可以在任何地方运行,而无需为不同的环境重新配置和部署。
优势包括最大限度的控制,灵活性,可重用性以及将现有的容器化应用程序引入云中的便利性,所有这些都是可能的,因为不太自由的应用程序部署模型提供了自由度。
CaaS的缺点包括显著地增加开发人员对操作系统(包括安全补丁),负载平衡,容量管理,扩展,日志记录和监控的责任。
目标受众
- 希望控制其应用程序及其所有依赖项的打包和版本控制的开发人员和运维团队,确保跨部署平台的可移植性和重用。
- 在一组相互依赖,独立扩展的微服务中寻求高性能的开发人员。
- 将容器移至云端,或跨私有/公共云部署,以及具有端到端群集部署经验的组织。
开发/运维人员经验
- 创建Kubernetes集群,Docker Swarm堆栈或Mesos资源池(完成一次)。
- 在本地迭代和构建容器镜像。
- 将打好标记的应用程序镜像推送到注册表。
- 将基于容器镜像的容器部署到集群。
- 测试并观察生产中的应用。
优点
- 对于正在部署的内容,开发人员拥有最大程度的控制权和责任。使用容器编排器,可以定义要部署的确切镜像版本,配置,以及管理其运行时的策略。
- 控制运行时环境(例如,运行时,版本,最小OS,网络配置)。
- 在系统外,容器镜像具有更高的可重用性和可移植性。
- 非常适合将容器化应用程序和系统引入云端。
缺点
- 对文件系统映像和执行环境负有更多责任,包括安全补丁和分发优化。
- 管理负载平衡和扩展行为的更多责任。
- 通常更多的责任是容量管理。
- 通常更长的启动时间,今天。
- 通常对应用程序结构的看法较少,因此指导意见较少。
- 通常对构建和部署机制负有更多责任。
- 通常,对监视,日志记录和其他常见服务的集成负有更多责任。
Platform-as-a-Service
Platform-as-a-Service (PaaS) - 专注于应用程序,让平台处理其余的事务。
示例:Cloud Foundry,OpenShift,Deis,Heroku
Platform-as-a-Service实现使团队能够部署和扩展应用程序,通过将配置信息注入到这些应用程序,可以使用大量运行时,绑定到数据目录,AI,IoT和安全服务,而无需手动配置和管理容器和操作系统。它非常适合具有稳定编程模型的现有Web应用程序。
优点包括更轻松地管理和部署应用程序,自动扩展和预配置服务,以满足最通用的应用程序需求。
缺点包括缺乏操作系统控制、粒度容器可移植性、负载平衡、应用程序优化,还有潜在的供应商锁定,以及需要在大多数PaaS平台上构建和管理监视和日志记录功能。
目标受众
- 需要部署平台的开发人员,使他们能够专注于应用程序源代码和文件(不打包它们),而不必担心操作系统。
- 默认情况下,使用可路由主机名创建更传统的基于HTTP的服务(应用程序和API)的开发人员。 但是,一些PaaS平台现在也支持通用TCP路由。
- 对更为成熟的云计算模型(与serverless相比)感到满意的组织,这些模型有综合文档和许多实例的支持。
开发/运维人员经验
- 迭代应用程序,在本地Web开发环境中构建和测试。
- 将应用程序推送到PaaS,在其中构建和运行。
- 测试并观察生产中的应用。
- 更新配置以确保高可用性和扩展以匹配需求。
优点
- 开发人员的参考框架在应用程序代码和它连接的数据服务上。对实际运行时的控制较少,但开发人员避免了构建步骤,也可以选择扩展和部署选项。
- 无需管理底层操作系统。
- 构建包提供对运行时的影响,根据需要提供尽可能多的控制(合理的默认值)。
- 非常适合具有稳定编程模型的许多现有Web应用程序。
缺点
- 失去对操作系统的控制,可能受到构建包版本的支配。
- 关于应用程序结构的更多见解,倾向于 12因素 微服务最佳实践,以及架构灵活性的潜在成本。
- 潜在的平台锁定。
Serverless
Functions-as-a-Service (FaaS)
将逻辑编写为响应各种事件的小块代码。
示例:AWS Lambda,Azure Functions,基于Apache OpenWhisk的IBM Cloud Functions,Google Cloud Functions,华为Function Stage 和 Function Graph,Kubeless,iron.io,funktion,fission,nuclio
Serverless使开发人员能够专注于由事件驱动的函数组成的应用程序,这些函数响应各种触发器并让平台负责其余的事情 - 例如触发器到函数逻辑,从一个函数传递到另一个函数的信息,自动设置容器和运行时间(时间,地点和内容),自动扩展,身份管理等。
其优势包括对任何云原生范例的基础设施管理的最低要求。无需考虑操作系统或文件系统,运行时甚至容器管理。Serverless享受自动扩展,弹性负载平衡和最细粒度的“即用即付”计算模型。
缺点包括不够全面和稳定的文档,示例,工具和最佳实践; 有挑战的调试; 响应时间可能较慢; 缺乏标准化和生态系统成熟度以及平台锁定的可能性。
目标受众
- 希望在单个函数中更多地关注业务逻辑的开发人员,这些函数可根据需求自动扩展并将交易与成本紧密联系起来。
- 希望更快地构建应用程序并且更少关注运维方面的开发人员。
- 创建事件驱动应用程序的开发人员和团队,例如响应数据库更改,物联网读数,人工输入等。
- 在标准和最佳实践尚未完全建立的领域,能够轻松采用尖端技术的组织。
开发/运维人员经验
- 迭代函数,在本地Web开发环境中构建和测试。
- 将单个函数上载到serverless平台。
- 声明事件触发器,函数及其运行时,以及事件到函数的关系。
- 测试并观察生产中的应用。
- 无需更新配置以确保高可用性和扩展以匹配需求。
Benefits优点
- 开发人员的观点已经远离运维问题,如管理高可用性函数的部署,更多地转向函数逻辑本身。
- 开发人员可根据需求/工作量自动扩展。
- 利用新的“即用即付”成本模型,仅对代码实际运行的时间收费。
- 操作系统,运行时甚至容器生命周期都是完全抽象的(serverless)。
- 更适合涉及物联网,数据和消息的新兴事件驱动和不可预测的工作负载。
- 通常是无状态,不可变和短暂的部署。每个函数都以指定的角色和明确定义/有限的资源访问权限运行。
- 中间件层将得到调整/优化,将随着时间的推移提高应用程序性能。
- 强烈推广微服务模型,因为大多数serverless运行时强制限制每个单独函数的大小或执行时间。
- 易于将第三方API集成为定制的serverless API,既可以扩展使用,又可以灵活地从客户端或服务器调用。
缺点
-
一种新兴的计算模型,快速创新,缺乏全面和稳定的文档,示例,工具和最佳实践。
-
由于运行时更具动态性,与IaaS和PaaS相比,调试可能更具挑战性。
-
由于按需结构,如果运行时在空闲时删除函数的所有实例,则某些serverless运行时的“冷启动”方面可能有性能问题。
-
在更复杂的情况下(例如,触发其他函数的函数),对于相同数量的逻辑,可以存在更多的运维表面区域。
-
缺乏标准化和生态系统成熟度。
-
由于平台的编程模型,事件/消息接口和BaaS产品,有平台锁定的可能性。
应该使用哪种云原生部署模型?
为了确定哪种模型最适合您的特定需求,应对每种方法(以及若干模型实施)进行全面评估。本节将提供一些考虑因素的建议,因为没有一个放之四海而皆准的解决方案。
评估特性和能力
体验每种方法。 从功能和开发体验的角度找到最适合您需求的方法。你正试图找到问题的答案,例如:
-
基于前面部分中描述的工作负载,这是serverless证明其价值的地方,我的应用程序是否适合? 与替代方案相比,我是否预期从serverless获得重大收益而值得改变?
-
在运行时及其运行环境中,我真正需要多少控制? 小的运行时版本更改会影响我吗? 我可以覆盖默认值吗?
-
我可以使用我选择的语言提供的全套功能和库吗? 如果需要,我可以安装其他模块吗? 我是否必须自己打补丁或升级?
-
我需要多少运维控制? 我是否愿意放弃容器或执行环境的生命周期?
-
如果我需要更改服务代码怎么办? 我可以多快部署它?
-
我如何保护我的服务? 我必须管理吗? 或者我可以卸载到可以做得更好的服务吗?
评估和衡量运维方面
使用PaaS和Container Orchestrator收集性能数据,例如恢复时间,以及使用Serverless平台进行冷启动。探索并量化应用程序的其他重要非功能特性对每个平台的影响,例如:
弹性:
- 如何使我的应用程序适应数据中心故障?
- 在部署更新时如何确保服务的连续性?
- 如果我的服务失败怎么办? 平台会自动恢复吗? 它对最终用户是不可见的吗?
可扩展性:
- 如果有突然的变化,平台是否支持自动扩展?
- 我的应用程序是否设计为有效地利用无状态扩展?
- 我的serverless平台是否会压倒任何其他组件,例如数据库? 我可以管理或限制背压吗?
性能:
- 每个实例或每个HTTP客户端每秒有多少个函数调用?
- 给定工作负载需要多少台服务器或实例?
- 从调用到响应的延迟是多少(在冷启动和热启动中)?
- 微服务之间的延迟,与单个部署中的共存功能相比,是问题吗?
CNCF Serverless工作组的潜在成果之一可能是何时选择特定模型的决策框架,以及如何在给定一组推荐工具的情况下进行测试。 有关详细信息,请参阅结论部分。
评估并考虑潜在成本的全部范围
这包括开发成本和运行时资源成本。
- 不是每个人都可以从头开始开展他们的开发活动。 因此,需要仔细考虑将现有应用程序迁移到其中一个云原生模型的成本。虽然对容器的升降式模型看起来最便宜,但从长远来看,它可能不是最具成本效益的。 同样,从成本角度来看,serverless的按需模型非常具有吸引力,但将单体应用程序拆分为函数所需的开发工作可能令人生畏。
- 与依赖服务集成的成本是多少? Serverless计算最初可能看起来最经济,但它可能需要更昂贵的第三方服务成本,或者非常快速地自动缩放,这可能导致更高的使用费。
- 平台免费提供哪些功能/服务? 我是否愿意以可移植性的潜在成本购买供应商的生态系统?
基于多平台运行应用程序
在查看当前可用的各种云托管技术时,可能并不明显,但没有理由需要将单个解决方案用于所有部署。实际上,没有理由需要在单个应用程序中使用相同的解决方案。一旦将应用程序拆分为多个组件或微服务,您就可以自由地将每个组件分别部署在完全不同的基础设施上,如果这是最符合您需求的。
同样,每个用于其特定目的微服务也可以用最佳技术(即语言)开发。 “分解单体”带来的自由带来了新的挑战,以下部分重点介绍了在选择平台和开发微服务时应该考虑的一些方面。
跨部署目标拆分组件
考虑将正确的技术与正确的工作相匹配,例如,物联网演示可能同时使用PaaS应用程序处理对连接设备仪表板的请求,以及一组 serverless 函数来处理来自设备本身的MQTT消息事件。 Serverless不是一个银弹,而是在您的云原生架构中可以考虑的新选择。
设计多个部署目标
另一种设计选择是使您的代码尽可能通用,允许在本地进行测试,并依赖于上下文信息(如环境变量)来影响它在特定环境中的运行方式。 例如,一组普通的POJO可能能够在三个主要环境中的任何一个中运行,并且可以根据可用的环境变量,类库或绑定服务来定制精确的行为。
为任意方式继续使用DevOps管道
大多数容器编排平台,PaaS实现和serverless框架都可以由命令行工具驱动,并且相同的容器镜像可以构建一次并在每个平台上重用。
考虑抽象以简化模型之间的可移植性
有越来越多的第三方项目生态系统弥补了将当前在PaaS或CaaS上运行的基于HTTP的Web应用程序移植到serverless平台的差距。 其中包括来自Serverless, Inc.和Zappa Framework的几个工具。
Serverless框架提供的适配器使得使用流行的Web应用程序框架(如Python WSGi和JAX-RS REST API)编写的应用程序能够在Serverless平台上运行。这些框架还可以提供可移植性和多个Serverless平台之间差异性的抽象。
详细信息视图:Serverless处理模型
本节总结了serverless框架中当前的函数使用,并概括了serverless 函数需求,生命周期,调用类型和所需的抽象。 我们的目标是定义serverless 函数规范,以便相同的函数可以编码一次并在不同的serverless框架中使用。 本节未定义确切的函数配置和API。
我们可以将FaaS解决方案概括为具有下图中显示的几个关键元素:
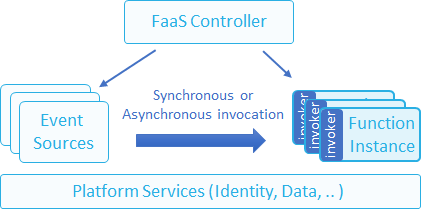
- Event sources/事件源 - 触发事件或流式传输触发到一个或多个函数实例中
- Function instances/函数实例 - 单个函数/微服务,可以按需扩展
- FaaS Controller/FaaS控制器- 部署,控制和监视函数实例及其来源
- Platform services/平台服务 - FaaS解决方案使用的一般集群或云服务(有时称为Backend-as-a-Service)
让我们首先看一下serverless环境中函数的生命周期。
函数生命周期
以下部分描述了函数生命周期的各个方面以及serverless框架/运行时通常如何管理它们。
函数部署管道
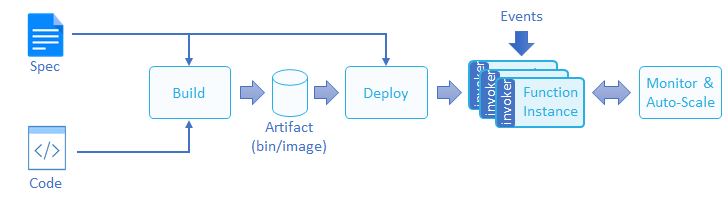
函数的生命周期从编写代码并提供规范和元数据开始(参见下面的函数定义),“builder”实体将获取代码和规范,编译并将其转换为工件(代码二进制文件,包或容器镜像)。 然后将工件部署在具有控制器实体的集群上,该控制器实体负责基于事件流量和/或实例上的负载来扩展函数实例的数量。
函数操作
Serverless框架可以允许以下动作和方法来定义和控制函数生命周期:
- Create - 创建新函数,包括其规格和代码
- Publish - 创建可在群集上部署的函数新版本
- Update Alias/Label (版本的) - 更新别名/标签(版本) - 更新版本别名
- Execute/Invoke - 调用特定版本,不通过其事件源
- Event Source association - 将特定版本的函数与事件源连接
- Get - 返回函数元数据和规范
- Update - 修改函数的最新版本
- Delete - 删除函数,可以删除特定版本或其所有版本的函数
- List - 显示函数列表及其元数据
- Get Stats - 返回有关函数运行时使用情况的统计信息
- Get Logs - 返回函数生成的日志
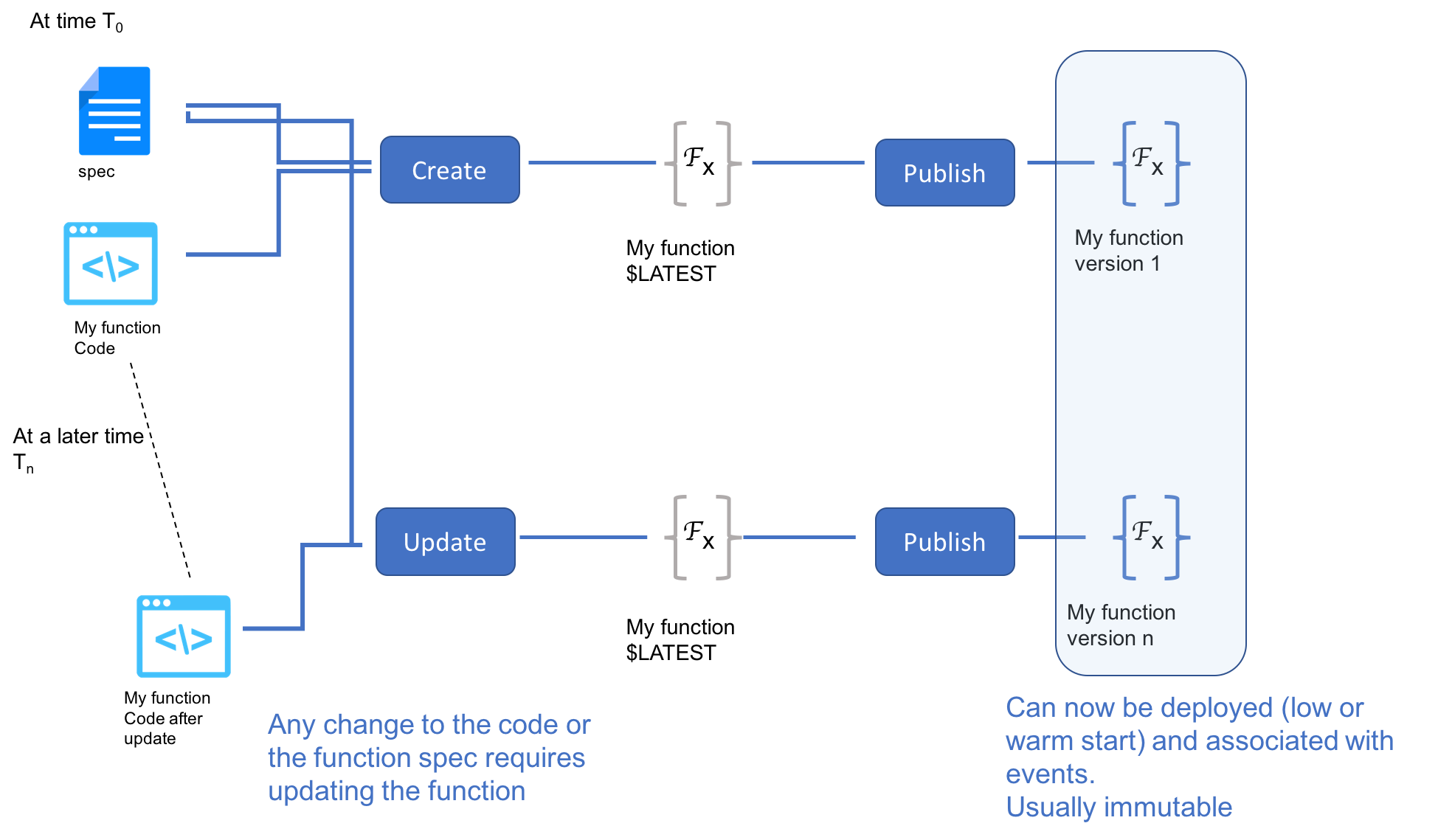
在创建函数时,提供其元数据(稍后在函数规范中描述)作为函数创建的一部分,函数将被编译并可能被发布。 稍后可以启动,禁用和启用函数。函数部署需要能够支持以下用例:
-
Event streaming/事件流,在此用例中,队列中可能始终存在事件,而处理的暂停/恢复可能需要通过显式请求
-
Warm startup/热启动 - 在任何时候具有最少实例数量的函数,在接收的“first”事件时进行热启动,因为该函数已经部署并准备好为事件服务(而不是冷启动,冷启动时指函数获得通过“incoming”事件在第一次调用时部署)
用户可以发布函数,这将创建新版本(“latest”版本的副本),发布的版本可能被标记或具有别名,请参阅下文。
用户可能希望直接执行/调用函数(绕过事件源或API gateway)以进行调试和开发过程。用户可以指定调用参数,例如所需版本,同步/异步操作,详细级别等。
用户可能想要获得函数统计(例如调用次数,平均运行时间,平均延迟,失败,重试等),统计可以是当前度量值或时间序列值(例如存储在Prometheus或云提供者设施中例如AWS Cloud Watch)。
用户可能希望检索函数日志数据。这可以通过严重性级别和/或时间范围和/或内容来进行过滤。 Log数据是每个函数都有的,它包括诸如函数创建和删除,显式错误,警告或调试消息之类的事件,以及可选的函数Stdout或Stderr。倾向每次调用有一个日志条目或者将日志条目与特定调用相关联的方式(以允许更简单地跟踪函数执行流程)。
Function Versioning and Aliases
A Function may have multiple versions, providing the user the ability to run different level of codes such as beta/production, A/B testing etc. When using versioning, the function version is “latest” by default, the “latest” version can be updated and modified, potentially triggering a new build process on every such change.
Once a user wants to freeze a version he will use a Publish operation that will create a new version with potential tags or aliases (e.g. “beta”, “production”) to be used when configuring an event source, so an event or API call can be routed to a specific function version. Non-latest function versions are immutable (their code and all or some of the function spec) and cannot be changed once published; functions cannot be “un-published” instead they should be deleted.
Note that most implementations today do not allow function branching/fork (updating an old version code) since it complicates the implementation and usage, but this may be desired in the future.
When there are multiple versions of the same function, the user must specify the version of the function he would like to operate and how to divide the traffic of events between the different versions (e.g. a user can decide to route 90% of an event traffic to a stable version and 10% to a beta version a.k.a “canary update”). This can be either by specifying the exact version or by specifying the version alias. A version alias will typically reference to a specific function version.
When a user creates or updates a function, it may drive a new build and deployment depending on the nature of the change.