云原生学习笔记
- 1: 云原生介绍
- 1.1: 云原生概述
- 1.2: 云计算的历史
- 1.3: 云原生出现的背景
- 1.4: 云原生的定义
- 1.5: 云原生的目标
- 1.6: 云原生的飞轮效应
- 1.6.1: 云原生的飞轮效应概述
- 1.7: 云原生特征
- 1.7.1: 概述
- 1.7.2: 隔离性(Isolation)
- 1.7.3: 可组合(Composable)
- 1.7.4: 容器化(Containerized)
- 1.7.5: 模块化(Modularity)
- 1.7.6: 弹性(Resiliency)
- 1.7.7: 可替换性(Replaceability)
- 1.7.8: 自动化(Automation)
- 1.7.9: 可观测性(Observability)
- 1.7.10: 可测试性(Testability)
- 1.7.11: 可移植性(Portable)
- 1.7.12: 安全(Security)
- 1.7.13: 移动性(Mobility)
- 1.7.14: 可扩展性(Scalability)
- 1.7.15: 可用性(Availability)
- 1.7.16: 成本(Cost)
- 1.7.17: 效率(Efficiency)
- 1.7.18: 敏捷(Agility)
- 2: 12因素应用
- 3: DevOps
- 4: 声明式设计
- 4.1: 声明式设计概述
- 5: 不可变基础设施
- 5.1: 不可变基础设施概述
- 6: 云原生中的容器
- 6.1: 容器概述
- 7: 微服务
- 7.1: 微服务概述
- 8: 服务网格
- 8.1: 服务网格概述
- 9: 云原生参考资料
- 9.1: 参考资料概述
- 9.2: 2019
- 9.3: 2018
- 9.4: 2017
- 9.4.1: 迁移到云原生应用架构
- 9.5: 2016
- 9.6: 2015及更早
- 9.7: 2018
- 9.7.1: 书籍
- 9.8: 演讲(2017)
- 9.8.1: CNCF: What is Cloud Native
- 9.8.2: CNCF: Cloud Native Strategy
- 9.9: 演讲(2018)
- 9.10: 演讲(2016)
- 9.11: 演讲(2015)
1 - 云原生介绍
1.1 - 云原生概述
1.2 - 云计算的历史
在介绍云原生之前,先看看过去几十年间,云计算领域的发展演进历程。
云计算的远古时代
云计算的历史事实上需要追溯到60多年前的计算机远古历史:

-
1955年,John McCarthy(备注:John McCarthy是Artificial Intelligence/人工智能一词的提出者)创造了一种在用户群中共享计算时间的理论。
-
1959年6月,在国际信息处理大会上克里斯托弗Christopher Strachey发表了《Time Sharing in Large Fast Computer》论文,提出了虚拟化概念。该文被公认为虚拟化技术的最早论述。
-
1965年8月,IBM推出System/360 Model 67 和 TSS 分时共享系统(Time Sharing System),通过虚拟机监视器(Virtual Machine Monitor)虚拟所有的硬件接口,允许多个用户共享同一高性能计算设备的使用时间,也就是最原始的虚拟机技术。
-
在20世纪60年代中期,美国计算机科学家 JCR Licklider 提出计算机互联系统(an interconnected system of computers)的想法。
-
1969年,在 JCR Licklider 的革命性创意的帮助下,Bob Taylor 和 Larry Roberts 开发了互联网的前身 ARPANET(Advanced Research Projects Agency Network),允许不同物理位置的计算机进行网络连接和资源共享。
-
1972年,IBM发布了名为VM(Virtual Machine)的操作系统。在90年代,虚拟机的使用开始流行
-
1974年,Popek和Goldberg发表了《Formal Requirements for Virtualizable Third Generation Architectures》提出了虚拟化准备的充分条件,指出满足条件的控制程序可以被称为虚拟机监视器Virtual Machine Monitor (VMM):(1)一致性:一个运行于虚拟机上的程序,其行为应当与直接运行于物理机上的行为基本一致,只允许有细微的差异如系统时间方面;(2)可控性:VMM对系统资源有完全的控制能力和管理权限;(3)高效性:绝大部分的虚拟机指令应当由硬件直接执行而无需VMM的参与。
-
1978年,IBM获得了独立磁盘冗余阵列(Redundant Arrays of Independent Disks,RAID)概念的专利。该专利将物理设备组合为池,然后从池中切出一组逻辑单元号(Logical Unit Number,LUN)并将其提供给主机使用。虽然该技术直到1988年IBM才与加利福尼亚州立大学伯克利分校联合开发了第一个实用版本,但该专利第1次将虚拟化技术引入存储之中。
“Time-Sharing”的背景:自20世纪50年代,人类使用大型计算机系统来处理数据。而在早期,大型计算机体积庞大而且价格高昂。为了提高投资回报率,购买大型机的组织开始实施“分时调度(time-sharing)”,然后从没有处理能力的终端访问大型计算机。“分时”理论可以充分利用可用的计算时间,可以用于为无力购买自己的大型机的小公司提供计算时间。
这里便陆续出现了云计算的基本前提:共享计算能力和共享网络,并出现了虚拟机,虚拟网络和早期基础设施。
但是在2000年前后虚拟化技术成熟之前,市场处于物理机时代。当时如果要启用一个新的应用,需要购买一台或者一个机架的新服务器。
虚拟化技术成熟
在2000年前后,虚拟化技术逐渐发展成熟:

- 1998年,VMware成立并首次引入X86的虚拟技术,通过运行在Windows NT上的VMware来启动Windows 95。
- 1999年,VMWare推出可在X86平台上流畅运行的第一款VMware Workstation,从此虚拟化技术终于走下了大型机的神话。之后,研发人员和发烧友开始在普通PC和工作站上大量使用该虚拟化解决方案。
- 1999年,IEEE颁布了用以标准化VLAN实现方案的802.1Q协议标准草案,从而可以将大型网络划分为多个小网络,使得广播和组播流量不会占据更多带宽的问题;同时,可以利用VLAN标签提供更高的网络段间的安全性。
- 2000年,IEEE颁布了虚拟专用网(Virtual Private Network)VPN标准草案,从而使得私有网络可以跨公网进行建立。
- 2000年,Citrix桌面虚拟化产品正式发布。
- 2001年,VMware发布了第一个针对x86服务器的虚拟化产品ESX和GSX,即ESX-i的前身。
- 2003年10月,Xen虚拟化项目首次面世推出了1.0版本,此时仅支持半虚拟化Para-Virtualization。之后,基于Xen虚拟化解决方案陆续被Redhat、Novell和Sun等的Linux发行版集成,作为默认的虚拟化解决方案。
- 2003年,Microsoft收购Connectix获得虚拟化技术进入桌面虚拟化领域,之后很快推出了Virtual Server免费版。
- 2005年,Xen 3.0发布,该版本可以在32位服务器上运行,同时该版本开始正式支持Intel的VT技术和IA64架构,从而使得Xen虚拟机可以运行完全没有修改的操作系统。该版本是Xen真正意义上可用的版本。
- 2006年10月,以色列的创业公司Qumranet在完成了虚拟化Hypervisor基本功能、动态迁移以及主要的性能优化之后,正式对外宣布了KVM的诞生。同年10月,KVM模块的源代码被正式接纳进入Linux Kernel,成为内核源代码的一部分。备注:Qumranet在2008年被RedHat收购。
- 2009年4月,VMware推出业界首款云操作系统VMware vSphere。
云计算的重要里程碑之一是2001年VMWare带来的可用于X86的虚拟化计划。通过虚拟机,可以在同一台物理机器上运行多个虚拟机,这意味着可以降低服务器的数量,而且速度和弹性也远超物理机。
基于虚拟机的云计算
在虚拟化技术成熟之后,云计算市场才真正出现,此时基于虚拟机技术诞生了众多的云计算产品,也陆续出现了IaaS、PaaS等平台和公有云、私有云、混合云等形态:

- 2006年,AWS推出首批云产品Simple Storage Service (S3)和Elastic Compute Cloud(EC2),使企业可以利用AWS的基础设施构建自己的应用程序
- 2008年4月,Google App Engine发布,是 Google 管理的数据中心中用于 WEB 应用程序的开发和托管的平台。
- 2009年,Heroku 推出第一款公有云 PaaS (Platform-as-a-Service)
- 2010年1月,微软发布 Microsoft Azure云平台服务。备注:Microsoft Azure 于2008年宣布。
- 2010年7月,Rackspace Hosting和NASA联合推出了一项名为OpenStack的开源云软件计划
- 2011年,Pivotal推出了开源版PaaS Cloud Foundry,作为Heroku PaaS的开源替代品,并于2014年底推出了Cloud Foundry Foundation。
- 2013年底,Google 推出 Google Compute Engine (GCE)正式版。备注:GCE的测试版本于2008年发布,预览版于2012年发布。
- 2014年,AWS推出 Lambda,允许在AWS中运行代码而无需配置或管理服务器,即Faas/Serverless。
在这期间,出现了云计算的多个重要里程碑:
- IaaS的出现:通过按时计费的方式租借服务器,将资本支出(Capex)转变为运营支出(Opex),这使得云计算得以大规模兴起和普及。
- PaaS的出现
- 开源IaaS的出现:云计算已经开始进入开源时代
- 开源PaaS的出现
- FaaS的出现
补充术语介绍,Capex Vs. Opex:
- Capex = capital expenditure / 资本支出
- Opex = operational expenditure / 运营支出
容器的兴起和编排大战
2013年,在云计算领域发生了一件影响深广的技术变革:容器。
容器技术可以说是过去十年间对软件开发行业改变最大的技术,而从虚拟机到容器,整个云计算市场发生了一次重大变革,甚至是洗牌。基于容器技术的容器编排市场,则经历了Mesos、Swarm、kubernetes三家的一场史诗大战,最终以kubernetes全面胜利而告终:

- 2008年,LXC(Linux Container)容器发布,这是一种内核虚拟化技术,可以提供轻量级的虚拟化,以便隔离进程和资源。LXC是Docker最初使用的具体内核功能实现
- 2013年,Docker发布,组合LXC,Union File System和cgroups等Linux技术创建容器化标准,docker风靡一时,container逐步替代VM,云计算进入容器时代
- 2014年底,CoreOS正式发布了CoreOS的开源容器引擎Rocket(简称rkt)
- 2014年10月,Google 开源 kubernetes,并在2015年捐赠给 CNCF
- 2015年6月,OCI组织成立,旨在制定并维护容器镜像格式和容器运行时的正式规范,以便在不同的操作系统和平台之间移植
- 2015年7月,Google联合Linux基金会成立了CNCF组织,kubernetes 成为 CNCF 管理的首个开源项目
- 2015年,CNCF组织开始力推 Cloud Nativ ,完全基于开源软件技术栈,Cloud Native 的重要理念是:以微服务的方式部署应用,每个应用都打包为自己的容器并动态编排这些容器以优化资源利用
- 2017年9月,Mesos宣布了对Kubernetes的支持
- 2017年10月,Docker宣布将在下一版Docker,将同时支持自家调度引擎Swarm和来自Google的调度平台Kubernetes
- 2018年3月,Kubernetes 从 CNCF 毕业,成为 CNCF 第一个毕业项目
这里有两个重要的里程碑:
- 2013年,Docker发布,容器逐步替代VM,云计算进入容器时代
- 2017年底,Kubernetes 赢得容器编排的胜利,云计算进入 Kubernetes 时代
在容器编排大战期间,以 kubernetes 为核心的CNCF Cloud Native生态系统也得以迅猛发展,云原生成为云计算市场的技术新热点。
云计算演进总结
云计算的发展演进历史,有以下规律:
-
核心构建块的变化:
从早期的物理服务器,通过虚拟化技术演进为虚拟机,再摆脱机器的限制缩小为构建块,最后通过容器化技术演进为目前的container
-
隔离单元:无论是启动时间还是单元大小,物理机、虚拟机、容器一路走来,实现了从重量级到轻量级的转变
-
供应商:从闭源到开源,从单一供应商到跨越多个供应商
下图形象的概述了这二十年云计算的演进过程:从传统预制IT、托管到云,以及云的不同形态如IaaS、PaaS、SaaS等。

对于XaaS的一路演进,可以简单归纳为:
- 有了IaaS,客户不用关注物理机器
- 有了PaaS,客户不用关注操作系统
- 有了FaaS,客户不用关注应用程序
在这过去的二十年间,云计算几乎重新定义了整个行业的格局,越来越多的企业开始降低对IT基础设施的直接资本投入,不再倾向于维护自建的数据中心,而是开始通过上云的方式来获取更强大的计算、存储能力,并实现按时按需付费。这不仅仅降低IT支出,同时也降低了整个行业的技术壁垒,使得更多的公司尤其是初创公司可以更快地实践业务想法并迅速推送到市场。
参考资料
- CNCF的介绍资料 Cloud Native and Container Technology Landscape
- What is XaaS? IaaS vs SaaS vs PaaS: what’s the difference:对XaaS的概括介绍
- 漫画趣味图解云计算的起源
- 云计算的前世今生——云计算发展大事件: 梳理得较为全面的云计算大事记文章,值得收藏和分享
- 坐看云起时,谈笑无还期
1.3 - 云原生出现的背景
软件正在改变世界
Software is Eating The World —— by Mark Andreessen, in 2011

Mark Andreessen是风险投资公司Andreessen-Horowitz的联合创始人和合伙人,该公司投资了Facebook,Groupon,Skype,Twitter,Zynga和Foursquare等,Mark Andreessen也是LinkedIn的投资者。
在2011年8月20日的华尔街日报上,Mark Andreessen发表了名为 “Why Software Is Eating the World” 的文章,当时正值惠普宣布放弃陷入困境的个人电脑业务,转而投入软件投资,并看好未来的增长潜力;与此同时,谷歌计划收购手机制造商摩托罗拉移动公司;苹果在过去几周成为美国最大的公司,以市值来判断,超越埃克森美孚。
援引原文部分内容:
我们处于戏剧性和广泛的技术和经济转变的中间,软件公司准备接管大量的经济。
越来越多的主要企业和行业正运行在软件上并提供在线服务 - 从电影到农业再到国防。许多获奖者都是硅谷式的创业技术公司,他们正在入侵和推翻既有的行业结构。
为什么现在发生这种情况?
计算机革命六十年,微处理器发明四十年,现代互联网兴起二十年,通过软件转变行业所需的所有技术终于有效,并可在全球范围内广泛传播。
十年前,当我在创办的Netscape公司时,大概5000千人使用了宽带互联网,而现在有超过20亿人使用宽带互联网。在接下来的10年里,我预计全球至少有50亿人拥有智能手机,每个人每天都可以随时随地使用这种手机充分利用互联网。
在后端,软件编程工具和基于互联网的服务可以轻松地在许多行业中推出新的全球软件驱动的初创企业 - 无需投资新的基础设施和培训新员工。2000年,当我的合伙人Ben Horowitz担任第一家云计算公司Loudcloud的首席执行官时,运营基本互联网应用程序每月的成本约为15万美元。今天在亚马逊云中运行相同的应用程序每月花费大约1500美元。
文中列出了被重塑的产业,具体有 : 最大的书店 Amazon、最多人订阅的Video service Netflix、最大的音乐公司iTune、 Spotify and Pandora等、成长最快的娱乐领域 videogame、最好的电影制片厂 Pixar、最大的行销平台 : Google、Groupon、 Facebook等、成长最快的电信公司 : Skype 、成长最快招聘公司 LinkedIn。
文章发表于2011年,在8年后的2019年再来看,感触更加深刻。
补充:有兴趣的同学可以看一下这个文章: A Review of ‘Why Software is Eating The World’: How have the companies fared?: 这是在2018年,有人撰文分析了在上文中提到的几家主要软件公司的发展情况:Facebook/Apple/Amazon/Netflix/Google。
移动互联网在加剧变化
在“Software is Eating The World”一文中,作者展望互联网规模时,写道:
在接下来的10年里,我预计全球至少有50亿人拥有智能手机,每个人每天都可以随时随地使用手机充分利用互联网。
在8年之后的2019年,我们已经可以清晰的确认Mark Andreessen的预测很正确,移动互联网时代的用户规模已经开始向人口基数看齐。
而移动互联网如此巨大的用户规模会对软件开发有什么影响?
援引Netflix的一页PPT,这里按照规模和变更速度将软件企业划分为四个象限/四种类型:
- 企业IT:规模小,变化慢,容易处理
- 电信:规模大,变化慢,主要应对硬件失败
- 初创公司:规模小,变化快,主要应对软件失败
- 网络规模的互联网企业:规模大,变化快,软硬件或者说所有东西都会出问题

在十年前乃至二十年前的互联网时代,大多数软件企业都位于上图左边的两个象限:规模或许有大有小,但是变更速度相对今天都不高。当企业发展壮大时,体现的也更多是在规模上,变更速度并不会发生质的变化。
而今天的移动互联网时代,则都位于上图右边的两个象限:无论规模是大是小,变更速度都要求非常高。并且当企业逐步发展壮大,规模十倍百倍增长时,对变更速度的要求并不会降低,甚至会要求更快。
在移动互联网时代,能够成长并发展起来的这些公司,他们的共同点是什么:
- 快速变更,不断创新,随时调整
- 提供持续可用的服务,因对各种可能的错误和中断
- 弹性可扩展的系统,因对用户规模的快速增长
- 提供新的用户体验,以移动为中心
这样的背景下,对软件开发的有了更高的要求,软件开发的方式也不得不跟随时代而变化:首当其冲的就是如何解决规模越来越大同时变更越来越快的难题。
Pivotal公司的Matt Stine对此描述如下:
We’re trying to bring a perceived conflict into balance: software-driven business agility vs. software system resiliency. We want to move fast and yet not break things. In order to do this, we’re going to change how we build software, not necessarily where we build software.
我们正努力平衡感知到的冲突:软件驱动的业务敏捷性 vs. 软件系统的弹性。我们希望快速前行而不破坏事物。为了做到这一点,我们将改变我们构建软件的方式,而不是在哪里构建软件。
软件上云大势所趋
将软件迁移到云上是应对这一挑战的自然演化方式,在过去二十年,从物理机到虚拟机到容器,从IaaS诞生到PaaS、CaaS、SaaS、FaaS一路演进,应用的构建和部署变的越来越轻、越来越快,而底层基础设施和平台则越来越强大,以不同形态的云对上层应用提供强力支撑。
关于云的定义,Matt Stine表示:
Obviously, we need a place to do this: “cloud.” I define cloud as any computing environment in which computing, networking, and storage resources can be provisioned and released elastically in an on-demand, self-service manner.
显然,我们需要一个地方来做到这一点:“云”。我将云定义为可以按需,自助服务方式弹性配置和发布计算,网络和存储资源的任何计算环境。
2006年AWS通过提供EC2服务开创了IaaS市场。通过按时计费的方式租借服务器,客户不承担资本支出,仅在使用服务时付费。将资本支出(Capex)转变为运营支出(Opex),这是云计算时代的真正开始,而之后PaaS,SaaS等的演进只是超云这个方向一步一步继续前行:

总结
前面我们谈到了软件对各行各业的渗透和对世界的改变,以及移动互联网时代巨大的用户基数下快速变更和不断创新的需求对软件开发方式带来的巨大推动力,结合上一篇文章描述的过去二十年间云计算的发展演进和软件上云的趋势,我们可以清晰的看到这样一个波澜壮阔的技术浪潮:
- 软件正在改变世界
- 移动互联网让这个变革影响到每一个人
- 传统软件开发方式受到巨大挑战
- 云计算普及,软件上云成为趋势
- 云的形态持续在演进
援引InfoQ主编徐川老师对云计算的总结:
- 云计算的技术逐渐发展成为它本来该有的模样;
- 以及与这样的云所匹配的软件架构;
- 以及与这样的架构所匹配的开发流程与方法论。
云原生由此诞生!
参考资料
- Why Software Is Eating the World: by Marc Andreessen
- Why Software Is Eating The World的读后感:繁体中文版本
- A Review of ‘Why Software is Eating The World’: How have the companies fared?: 在2018年,有人撰文分析了在上文中提到的几家主要软件公司的增长情况。
- Netflix Development Patterns for Scale, Performance & Availability ,来自Netflix,2013年
- 2018 年终盘点:我们处在一个什么样的技术浪潮当中?:来自InfoQ主编徐川老师
1.4 - 云原生的定义
云原生定义
云原生意味着应用程序原生就被设计为在云上以最佳方式运行。
云原生是一种专门针对云上应用而设计的方法,用于构建和部署应用,以充分发挥云计算的优势。这些应用的特点是可以实现快速和频繁的构建、发布、部署,结合云计算的特点实现和底层硬件和操作系统解耦,可以方便的满足在扩展性,可用性,可移植性等方面的要求,并提供更好的经济性。同时通过拆解为多个小型功能团队来让组织更敏捷,让人员、流程和工具更好的结合,在开发、测试、运维之间进行更密切的协作。
但是当需要回答“什么是云原生”这个问题时,还是会有些困难:在过去几年间,云原生的定义一直在变化和发展演进,不同时期不同的公司对此的理解和诠释也不尽相同,因此往往会带来一些疑惑和误解。
我们一起来看看云原生定义在不同时期的变化。
Pivotal的定义
Pivotal 是Cloud Native/云原生应用的提出者,并推出了Pivotal Cloud Foundry和Spring系列开发框架,是云原生的先驱者和探路者。
2015年,来自Pivotal公司的Matt Stine编写了一本名为 迁移到云原生应用架构 的电子书,提出云原生应用架构应该具备的几个主要特征:
- 符合12因素应用(Twelve-Factor Applications)
- 面向微服务架构(Microservices)
- 自服务敏捷架构(Self-Service Agile Infrastructure)
- 基于API的协作(API-Based Collaboration)
- 抗脆弱性(Antifragility)
在2017年10月,也是Matt Stine,在接受InfoQ采访时,则对云原生的定义做了小幅调整,将Cloud Native Architectures定义为具有以下六个特质:
- 模块化(Modularity):(通过微服务)
- 可观测性(Observability)
- 可部署性(Deployability)
- 可测试性(Testability)
- 可处理性(Disposability)
- 可替换性(Replaceability)
而在Pivotal最新的官方网站 https://pivotal.io/cloud-native 上,对cloud native的介绍则是关注如下图所示的四个要点:

- DevOps
- Continuous Delivery
- Microservices
- Containers
CNCF的定义
2015年CNCF建立,开始围绕云原生的概念打造云原生生态体系,起初CNCF对云原生的定义包含以下三个方面:
- 应用容器化(software stack to be Containerized)
- 面向微服务架构(Microservices oriented)
- 应用支持容器的编排调度(Dynamically Orchestrated)
云原生包含了一组应用的模式,用于帮助企业快速,持续,可靠,规模化地交付业务软件。云原生由微服务架构,DevOps 和以容器为代表的敏捷基础架构组成。援引宋净超同学的一张图片来描述云原生所需要的能力与特征:

在2018年,随着社区对云原生理念的广泛认可和云原生生态的不断扩大,还有CNCF项目和会员的大量增加,起初的定义已经不再适用,因此CNCF对云原生进行了重新定位。
2018年6月,CNCF正式对外公布了更新之后的云原生的定义(包含中文版本)v1.0版本:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone.
云原生计算基金会(CNCF)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式民主化,让这些创新为大众所用。
新的定义中,继续保持原有的核心内容:容器和微服务,但是非常特别的将服务网格单独列出来,而不是将服务网格作为微服务的一个子项或者实现模式,体现了云原生中服务网格这一个新生技术的重要性。而不可变基础设施和声明式API这两个设计指导理念的加入,则强调了这两个概念对云原生架构的影响和对未来发展的指导作用。

可以通过访问 https://github.com/cncf/toc/blob/master/DEFINITION.md 查看。
云原生定义之外
从上面可以看到,云原生的内容和具体形式随着时间的推移一直在变化,即便是CNCF最新推出的云原生定义也非常明确的标注为v1.0,相信未来我们很有机会看到v1.1、v2版本。而且云原生这个词汇最近被过度使用,混有各种营销色彩,容易发生偏离。因此,云原生的定义是什么并不重要,关键还是云原生定义后面的理念、文化、技术、工具、组织结构和行为方式。
Joe Beda,Heptio 的CTO,指出:
There is no hard and fast definition for what Cloud Native means. In fact there are other overlapping terms and ideologies. At its root, Cloud Native is structuring teams, culture and technology to utilize automation and architectures to manage complexity and unlock velocity.
Cloud Native并没有硬性和牢靠的定义。实际上,还有其他重叠的术语和意识形态。从根本上说,Cloud Native正在构建团队,文化和技术,以利用自动化和架构来管理复杂性和解锁速度。
We are still at the beginning of this journey.
我们还处在这个旅程的开始阶段。
Christian Posta 指出:
“Cloud native” is an adjective that describes the applications, architectures, platforms/infrastructure, and processes, that together make it economical to work in a way that allows us to improve our ability to quickly respond to change and reduce unpredictability. This includes things like services architectures, self-service infrastructure, automation, continuous integration/delivery pipelines, observability tools, freedom/responsibility to experiment, teams held to outcomes not output, etc.
“云原生”是一个形容词,用于描述应用,结构,平台/基础设施和流程,这些共同促使我们以比较经济的工作方式来提高能力,实现快速响应变化和减少不可预测性。包括服务架构,自助服务基础设施,自动化,持续集成/交付管道,可观察性工具,实验的自由/责任,坚持结果而不是产出的团队等。
在下一节,我们将深入分解云原生的理念和诉求,来看看云原生是通过什么方式来实现目标。
参考资料
- 云原生(Cloud Native)的定义 :来自宋净超同学的博客网站
- Migrating to Cloud Native Application Architectures ,作者是来自Pivotal公司的Matt Stine;以及宋净超同学翻译的中文版 迁移到云原生应用架构
- Defining Cloud Native: A Panel Discussion: Infoq对Christian Posta、Kevin Hoffman、Matt Stine的访谈录。
- Cloud Native Part 1: Definition:Joe Beda,Heptio CTO的连载
- CNCF Cloud Native Definition v1.0: CNCF的官方定义
1.5 - 云原生的目标
关键目标
根据前面对云计算历史的追溯,对云原生出现背景的分析,以及对不同时期云原生定义的回顾总结,这里给出云原生的几个关键目标:

-
规模:
要求云原生服务能够适应不同的规模(包括但不限于用户规模/部署规模/请求量),并能够在部署时动态分配资源,以便在不同的规模之间快速和平滑的伸缩。典型场景如:初创公司或新产品线快速成长,用户规模和应用部署规模在短时间内十倍百倍增长;促销、季节性、节假日带来的访问量波动,高峰时间段的突发流量等。
-
可用:
通过各种机制来实现应用的高可用,以保证服务提供的连续性。
-
敏捷
快速响应市场需求
-
成本
充分有效的利用资源
TBD:这里稍后补充详细信息。
解决各目标之间的冲突
在这四个核心目标之间,存在彼此冲突的情况:

-
规模和敏捷之间的冲突:
规模大而又要求敏捷,我们比喻为“巨人绣花”。
-
规模和可用性之间的冲突:
规模大而要求可用性高,我们比喻为“大象起舞”。
-
敏捷和可用性之间的冲突:
敏捷而要求高可用,我们比喻为“空中换发”。
而云原生应用,必须要在同时满足这三个目标的前提下,还要实现成本控制。
稍后的章节,将通过飞轮效应来讲解云原生是如何逐步产生并积累出来的,并在云原生特征中将这四个核心目标拆解为十几个特征来分别介绍各个目标的达成方式。后面会详细讲解云原生的代表技术和理念是如何围绕这些核心目标和特征来实现的。
1.6 - 云原生的飞轮效应
1.6.1 - 云原生的飞轮效应概述
在云原生之前
在云原生出现之前,软件开发领域存在如下图的基本循环:

- 软件供应商开发软件产品
- 产品提供各种功能
- 这些功能可以满足客户的需求
- 于是有更多的客户使用这些产品,产品普及率的增加会带来更多利润,促使软件开发商继续改进产品和加强功能
在这个闭环中,迭代速度通常并不快(典型如大型电信产品一年只做一两次大版本发布),用户规模也比较小(除了电信软件,和目前移动互联网时代相比有一到两个数量级的差异),因此客户(包括开发、测试、运维、市场运营等)需求主要集中在产品的功能性。
云原生时代的新挑战
随着互联网,尤其是移动互联网的发展,用户规模剧增,对功能性的要求急剧增加:

而在满足功能之外,对效率的要求更加迫切:需要在开发、测试、部署、运维等几乎所有环节都大幅提升工作效率,以快速变更来实现对市场的快速响应,同时还必须尽量控制成本:

对速度和成本的追求催生了云计算市场,并一步一步演进到云原生架构,出现了容器、微服务、服务网格、不可变基础设施等技术和理念:

云原生架构,不仅仅体现在功能性方面的进一步改善和加强,而且在易用性方面有了质的飞跃:

最终,云原生不仅仅在功能性方面可以满意客户需求,还通过改善易用性极大的提升了客户体验。在下图中,我们将客户需求升级为客户体验。而良好的用户体验,会直接帮助客户提升各种效率:

因此,在原有的闭环之外,云原生还形成了一个新的闭环:

- 通过云原生架构,在功能性之外提供易用性
- 通过提供易用性,提升客户体验
- 提供提升客户体验,来帮助客户提高效率
- 而效率的持续改进,会促使云原生架构进一步演进,出现更多易用性更好的理念和技术,云原生提供商也愿意加强产品易用性方面的表现
最终,在云原生时代,以客户体验为中心,形成功能性和易用性两个闭环:

1.7 - 云原生特征
1.7.1 - 概述
云原生的特征列表
在前面我们将云原生的目标分解为四个核心目标:

现在将这四个云原生核心目标拆解为多个云原生特性:
| 特征 | 规模(Scale) | 可用(Available) | 敏捷(Agility) | 成本(Cost) |
|---|---|---|---|---|
| 隔离性(Isolation) | ✔️ | ✔️ | ✔️ | |
| 模块化(Modularity) | ✔️ | ✔️ | ✔️ | |
| 可组合(Composable) | ✔️ | ✔️ | ||
| 容器化(Containerized) | ✔️ | ✔️ | ✔️ | |
| 弹性(Resiliency) | ✔️ | ✔️ | ||
| 可替换性(Replaceability) | ✔️ | ✔️ | ||
| 自动化(Automation) | ✔️ | ✔️ | ✔️ | ✔️ |
| 可观测性(Observability) | ✔️ | ✔️ | ||
| 可测试性(Testability) | ✔️ | ✔️ | ||
| 可移植性(Portability) | ✔️ | ✔️ | ✔️ | |
| 安全(Security) | ✔️ | |||
| 移动性(Mobility) | ✔️ |
1.7.2 - 隔离性(Isolation)
隔离性是云计算的最基本的特征。
系统层面的隔离性
云计算中分享的计算能力、网络能力、存储能力,都必须以某种方式实现隔离,才可以提供给客户(或者说租户)使用。
而云原生应用也要求与物理机器和操作系统解耦,理论上说,云原生应用是在更高的抽象级别(即云)上运行,和物理机器和操作系统不应该有直接的依赖关系。
虚拟化技术的历史
系统层面隔离性的实现直接依赖于虚拟化技术。虚拟化技术是云计算的最重要的也是最关键的基础技术:没有虚拟化技术,隔离性和云计算都无从谈起。
在云计算的历史上,虚拟化有两个关键技术出现,都极大的推动了云计算的发展:
-
虚拟机(Virtual Machine)技术

-
容器(Container)技术

虚拟化技术的飞轮
在虚拟机技术出现之前的物理机时代,客户需要直接面对物理机器,比如自行购买机器、安装操作系统、搭建机房、准备网络等。当然也出现了一些改善型的服务,比如服务器托管就免除了机房和网络的工作,而服务器租用则将购买服务器变成了租用服务器,但原则上用户依然是需要面对物理机器。
后来通过在服务器软件(比如说在web应用服务器如Apache、IIS)之上,提供虚拟主机服务,容许用户运行静态网站、或者PHP、ASP等脚本语言,一定程度上实现了有限的隔离性。

虚拟机技术出现之后,基于虚拟机技术(尤其是成熟后的Xen、KVM等)的 VPS 可以提供更多的功能,带来更好的客户体验,更充分的利用物理机器的资源。之后基于虚拟机技术的云计算模式一路发展,IasS/PaaS/SaaS/FaaS 相继出现并成熟。
虚拟机技术有非常好的隔离性,但相对较重,在 LXC、cgroup 等技术发展成熟后,基于共享内核的容器技术出现,由于轻量高效的特点迅速普及,CaaS 出现,IasS/PaaS/SaaS/FaaS 等也随即从基于虚拟机转为基于容器。之后以 Kubernetes 为代表的容器编排技术更是将容器的优点充分发挥。
但从隔离性上说,容器技术由于共享Liunx内核,在隔离性上始终存在不足,而传统虚拟机技术和容器相比又显得太重。最近,以 gvisor 和 kata container 为代表的新型虚拟机/容器技术正在迅速发展,目标是希望能融合虚拟机/容器的优点。目前这些技术还在早期发展阶段,尚未普及。未来会带来什么样的新变化,值得期待。
子系统间的隔离性
当单个应用程序,通过模块化技术(如微服务)拆解为多个相互调用相互协作的服务之后,就出现了子系统之间隔离性的要求。
如图所示,假定当前系统中所有服务的可用性就是99.99%,那么多一个服务依赖多个服务(包括级联依赖),由于被依赖的服务可能失败,因此当前服务的可用性是无法维持在99.99%的,而是随着服务依赖的数量增加而下降:

从实际情况看,通常服务有10个左右的依赖服务(注意包括级联依赖)是很正常的,某些特殊的服务有100个左右的依赖服务也是可能的,而这种情况下,服务的可用性会直接下降到99.9%和99%。
因此,为了达到可用性的目标,将最终的可用性维持在99.99%,有两个方法:
-
提供每个组件的可用性:要求每个组件的可用性上升一个等级,比如达到99.999%,很明显这个难度很大,尤其成本会无法控制

-
隔离发生故障的组件:
打破导致系统失败的级联依赖,实现子系统隔离: 让失败只发生在一个组件中,而不导致级联系统失败。

而子系统隔离需要实现:
- 主动/被动健康检查:排除不健康的实例
- 熔断、重试、超时
- 服务失败时提供fallback
- 金丝雀推出 (Canary Push)
- 蓝绿部署:应该就是现在常说的蓝绿部署
- 灰度发布:先小范围试错,验证OK再全面上线
- Zone Isolation:区域隔离,以应对基础设施失败,如电力故障
- Region Isolation:地域隔离,通过DNS等技术手段切换Region
1.7.3 - 可组合(Composable)
可组合(Composable)
Each service is composable: this implies that the service is designed to allow it to be part of other applications. At the minimum, each Service has an Application Programming Interface (API) that is uniform and discoverable, and in addition can have well defined behaviors for registration, discovery, and request management.
每个服务都是可组合的:这意味着该服务旨在使其成为其他应用程序的一部分。每个服务至少具有统一且可发现的应用程序编程接口(API),此外还可以为注册,发现和请求管理定义良好的行为。
1.7.4 - 容器化(Containerized)
容器化(Containerized)
以容器方式打包的应用程序实现了 dev/prod 的一致性,促进代码和组件重用并简化运维。
打包为轻量级容器:云原生应用程序是打包为轻量级容器的独立自治服务的集合。与虚拟机不同,容器可以快速扩展和扩展。由于扩展单元转移到容器,因此优化了基础架构利用率。
部署在自助服务,弹性云基础架构上:云原生应用程序部署在虚拟,共享和弹性基础架构上。它们可以与底层基础架构保持一致,以动态增长和缩小 - 根据不同的负载调整自身。
1.7.5 - 模块化(Modularity)
模块化的理念
在软件设计中,模块化是管理系统复杂度的重要手段。随着应用程序规模的增大,复杂性越来越高。为了降低应用的复杂度,增加代码重用,需要将应用分解为更小更易于理解的部分。实践中,我们通常将应用程序按照功能的不同划分为独立但相互协作的部分,称为“模块”。
模块是可以部署、管理、重用和组合的单元,多个模块相互协作,组成完整的应用程序,对外提供功能和服务。
模块化的演进
模块化技术由来已久,早不是新的概念,而对于云原生应用来说模块化尤为重要:云原生架构从诞生开始就以SOA、微服务等方式在践行模块化,近年来还出现了Function规模的模块。
我们来看一下模块化的演进过程:

可以清晰的看到,模块化的演进方向是模块的粒度越来越小。
模块化技术的飞轮
结合飞轮理论来细致的追溯模块化演进过程中的粒度变化带来的技术发展:

-
进程内模块:早期的模块化更多的是关注如何拆解系统为多个子系统,拆分功能模块为类库、动态链接库等可重用机制,为了更好的管理这些拆分出去的功能模块,实现组合和重用,还建立了非常完备的依赖管理体系,如Java中我们非常熟悉的Java Maven、Gradle等。
此时的模块只是在打包、发布时独立存在,应用程序运行起来之后就被应用程序加载,隔离性并不好。因此后来出现了加强进程内模块隔离和管理的思路,出现了典型如 OSGi 技术和 Java9 中引入的 Modular 技术。
由于模块都在同一个进程内,因此此时对模块的调用都是方法调用。
-
服务:后面出现SOA架构,提倡服务化,即将模块以服务的方式从应用进程中分离除去并独立部署,应用以远程调用的方式调用SOA服务提供的公共API。SOA架构在进程层面将应用分解,通过对SOA服务的组合和重用来满足应用的需求。SOA时代,产生了一系列非常优秀的服务化框架如dubbo/HSF/SOFA等。
-
微服务:在SOA长期实践的基础上,微服务的理念产生,除了颗粒进一步缩小,还要求不同的微服务也要进程分离,同时为了满足高内聚的要求,对数据库等内在资源的访问也要求隔离。微服务时代,出现了大家熟悉的spring cloud。
在微服务理念出现时,正值容器技术出现,微服务+容器的组合相互促进成为市场热点。后面service mesh理念出现,k8s等容器编排系统成熟,service mesh + k8s成为微服务+容器组合的升级版本。
-
函数:再进一步,将模块的颗粒缩小到函数级别,配合FaaS、Serverless平台使用。
微服务
微服务在云原生中的重要性,我们可以从前面云原生的定义中感受到:所有方式的云原生定义,都会将微服务作为重点。甚至在很多强调模块化的地方,都会明确指明微服务。
可以说,微服务是云原生中模块化最典型的实现模式。
参考资料
1.7.6 - 弹性(Resiliency)
应对单个容器,机器甚至数据中心的故障,满足不同水平的需求。
如果服务能够在中断和故障中存活并保持在线,则服务具有弹性。此外,他们还可以充分利用云中提供的自动故障转移和灾难恢复机制。
Each service is resilient: this means that each service is highly-available and can survive infrastructure failures. This characteristic limits the failure domain, due to software bugs or hardware issues.
每项服务都具有弹性:这意味着每项服务都具有高可用性,可以承受基础架构故障。由于软件错误或硬件问题,此特性限制了故障域。
Resiliency
Resiliency refers to the application’s ability to survive and remain online during an infrastructure outage or failure. A properly designed cloud-native application would have multiple techniques to retry failed transactions and there would be multiple instances of the application services running on other servers or VMs.
Legacy applications that were not designed for a cloud can use tools within a hypervisor or cloud infrastructure such as traffic load balancing, clustering, and server/VM failover, but these are not as effective and transparent to the end user as a cloud-native application’s resiliency. There are many other aspects of resiliency and cloud-native application design benefits that will be covered later in this chapter.
弹性
弹性是指应用程序在基础设施中断或故障期间生存并保持在线的能力。正确设计的云原生应用程序将具有多种技术来重试失败的事务,并且将在其他服务器或VM上运行多个应用程序服务实例。
不是为云设计的传统应用程序可以使用虚拟机管理程序或云基础架构中的工具,例如流量负载平衡,群集和服务器/ VM故障转移,但这些应用程序对于最终用户而言并不像云原生应用程序那样有效和透明。弹性。弹性和云原生应用程序设计优势还有许多其他方面,本章稍后将对此进行介绍。
1.7.7 - 可替换性(Replaceability)
可替换性的由来
可替换性和虚拟化技术密切相关,当应用运行的平台从物理机到虚拟机再到容器,然后配合自动化技术,尤其是Kubernetes这种功能强大的成熟的容器编排平台,创建和销毁一个应用的速度和开销都很理想。加上容器和镜像带来的不可变性,如果应用本身是无状态的,那么这个应用就可以非常容易的做到随意替换任何一个运行中的实例。

虽然说在物理机和虚拟机时代实现类似的可替换性也是有办法的,但是毫无疑问的是在容器时代实现可替换性要简单和实用的多。“容器化 + 自动化 + 不可变性 + 无状态” 为可替换性带来了巨大的实用价值。
Pets vs. Cattle
关于可替换性,有一个非常流行的谚语:“Pets vs. Cattle”,宠物和奶牛(或者直白一点翻译为 牲口 更容易理解)。
援引一段对Pets(宠物)的解释:

Servers or server pairs that are treated as indispensable or unique systems that can never be down. Typically they are manually built, managed, and “hand fed”. Examples include mainframes, solitary servers, HA loadbalancers/firewalls (active/active or active/passive), database systems designed as master/slave (active/passive), and so on.
服务器或服务器对,被视为必不可少或独一无二的系统,永不停机。通常,它们是手动构建,管理和“手工伺候”的。示例包括大型机,单独服务器,HA负载均衡器/防火墙,设计为主/从的数据库系统等。
援引一段对Cattle(奶牛/牲口)的解释:

Arrays of more than two servers, that are built using automated tools, and are designed for failure, where no one, two, or even three servers are irreplaceable. Typically, during failure events no human intervention is required as the array exhibits attributes of “routing around failures” by restarting failed servers or replicating data through strategies like triple replication or erasure coding. Examples include web server arrays, multi-master datastores such as Cassandra clusters, multiple racks of gear put together in clusters, and just about anything that is load-balanced and multi-master.
两个以上服务器的部署,使用自动化工具构建,专为故障而设计,其中每一台都是可以替代的,甚至两台,三台也是可以替代的。通常,在故障事件期间不需要人为干预,因为部署可以通过重新启动故障服务器或通过三重复制或擦除编码等策略复制数据来展示“故障路由”的属性。示例包括Web服务器部署,多主数据存储(如Cassandra集群),以及几乎任何负载均衡和多主机。
简单说,如何判断某个机器、服务是宠物还是牲口,只要简单评估一下:如果它发生失败无法工作,你是倾向于让它恢复,还是倾向于简单抛弃然后拿另一个替换。
云原生下的角色转变
在云原生时代,有一些概念发生了角色转变:有些从宠物转变为牲口,有些从牲口转变为宠物。
IP地址:从宠物到牲口
在云原生之前,尤其是容器技术出来之前,IP地址是非常重要的,某些情况下几乎等同于一台机器(物理机或者虚拟机)的标致,通常IP是固定的不会轻易更改,外部系统也经常是通过IP地址来实现对这个机器的访问。
而在容器时代,容器被频繁创建和销毁,容器的IP地址不再固定而是动态变化,这是IP地址已经不在适合作为标识而使用。举例,在Kubernetes中取而代之的是标签(Label)和标签选择器(Label Selector),通过诸如 “app: service-1” 这样的方式来定位目标容器
端口:从牲口到宠物
TBD
参考资料
- PETS VS. CATTLE
- PETS VS. CATTLE: By Noah Slater
- CERN Data Centre Evolution: PPT 第17页
- DevOps Concepts: Pets vs Cattle
1.7.8 - 自动化(Automation)
自动化性(Automation)
The CN application needs to be abstracted completely from the underlying infrastructure stack. This is key as development teams can focus on solely writing their software and does not need to worry about the maintenance of the underlying OS/Storage/Network. One of the key challenges with monolithic platforms (http://www.vamsitalkstech.com/?p=5617) is their inability to efficiently leverage the underlying infrastructure as they have a high degree of dependency to it. Further, the lifecycle of infrastructure provisioning, configuration, deployment, and scaling is mostly manual with lots of scripts and pockets of configuration management.
CN应用程序需要从底层基础架构堆栈中完全抽象出来。这是关键,因为开发团队可以专注于单独编写软件,而无需担心底层OS /存储/网络的维护。单片平台(http://www.vamsitalkstech.com/?p=5617)面临的主要挑战之一是它们无法有效利用底层基础架构,因为它们对它有很高的依赖性。此外,基础架构配置,配置,部署和扩展的生命周期大多是手动的,具有大量脚本和配置管理口袋。
另一方面,考虑到其规模,CN应用程序必须非常轻松。的规定部署规模循环高度与所述应用程序自动调整为满足需求,资源约束和从故障中恢复无缝自动化。我们在之前的博客中讨论了Kubernetes。
The CN application, on the other hand, has to be very light on manual asks given its scale. The provision-deploy-scale cycle is highly automated with the application automatically scaling to meet demand and resource constraints and seamlessly recovering from failures. We discussed Kubernetes in one of the previous blogs.
自动化功能:云原生应用程序可以高度自动化。它们与基础设施概念作为代码相得益彰。实际上,仅需要一定程度的自动化来管理这些大型和复杂的应用程序。
1.7.9 - 可观测性(Observability)
可观测性(Observability)
1.7.10 - 可测试性(Testability)
可测试性(Testability)
support Continuous Integration and Continuous Delivery…
The reduction of the vast amount of manual effort witnessed in monolithic applications is not just confined to their deployment as far as CN applications are concerned. From a CN development standpoint, the ability to quickly test and perform quality control on daily software updates is an important aspect. CN applications automate the application development and deployment processes using the paradigms of CI/CD (Continuous Integration and Continuous Delivery).
The goal of CI is that every time source code is added or modified, the build process kicks off & the tests are conducted instantly. This helps catch errors faster and improve quality of the application. Once the CI process is done, the CD process builds the application into an artifact suitable for deployment after combining it with suitable configuration. It then deploys it onto the execution environment with the appropriate identifiers for versioning in a manner that support rollback. CD ensures that the tested artifacts are instantly deployed with acceptance testing.
特色#4他们支持持续集成和持续交付……
就CN应用程序而言,单片应用程序中大量手动工作的减少不仅限于它们的部署。从CN开发的角度来看,快速测试和执行日常软件更新质量控制的能力是一个重要方面。CN应用程序使用CI / CD(持续集成和持续交付)的范例自动化应用程序开发和部署过程。
CI的目标是每次添加或修改源代码时,构建过程开始,测试立即进行。这有助于更快地捕获错误并提高应用程序的质量。完成CI过程后,CD过程将应用程序与适当的配置组合后,将应用程序构建为适合部署的工件。然后,它以支持回滚的方式将其部署到具有适当版本控制标识符的执行环境中。CD确保通过验收测试立即部署测试的工件。
和其他的关系
- 自动化
1.7.11 - 可移植性(Portable)
可移植性(Portable) No Lock In
开源软件堆栈支持在任何公有云或私有云(或两者组合的混合云)上部署,避免Cloud绑定(供应商绑定)。

- Software is eating the world
- Open Source is eating Software
- Cloud is eating Open Source
如果没有通用开源软件,我们将冒着Cloud绑定的风险。
1.7.12 - 安全(Security)
安全(Security)
It goes without saying that security is a critical part of CN applications and needs to be considered and designed for as a cross-cutting concern from the inception. Security concerns impact the design & lifecycle of CN applications ranging from deployment to updates to image portability across environments. A range of technology choices is available to cover various areas such as Application level security using Role-Based Access Control, Multifactor Authentication (MFA), A&A (Authentication & Authorization) using protocols such as OAuth, OpenID, SSO etc. The topic of Container Security is very fundamental one to this topic and there are many vendors working on ensuring that once the application is built as part of a CI/CD process as described above, they are packaged into labeled (and signed) containers which can be made part of a verified and trusted registry. This ensures that container image provenance is well understood as well as protecting any users who download the containers for use across their environments.
毫无疑问,安全性是CN应用程序的关键部分,需要从一开始就考虑并设计为一个跨领域的关注点。安全问题影响CN应用程序的设计和生命周期,从部署到更新,再到跨环境的映像可移植性。一系列技术选择可用于涵盖各个领域,例如使用基于角色的访问控制的应用程序级安全性,多因素身份验证(MFA),使用OAuth,OpenID,SSO等协议的A&A(身份验证和授权).Container的主题安全性是本主题的基础,并且有许多供应商致力于确保一旦应用程序构建为上述CI / CD过程的一部分,它们被打包成带标签(和签名)的容器,这些容器可以成为经过验证和信任的注册表的一部分。这样可以确保容器图像出处得到充分了解,并保护下载容器以便在其环境中使用的任何用户。
TDWI调查还向组织询问了云分析采用的障碍。毫不奇怪,两个最重要的问题是安全性和数据隐私 - 这些问题一直困扰着云计算的采用。

Authentication systems
Applications that might have run within existing enterprise datacenters often utilized the internal corporate Microsoft Active Directory or some other identity management system to authenticate user logons. Ideally, applications hosted in a cloud should not assume Active Directory or the internal identity system is available; instead, they should favour an industry standard for authentication and directories such as LDAP, OAUTH, or SAML. These provide authentication capabilities with OAUTH and SAML a bit more robust and appropriate as part of a single sign-on (SSO) system.
There is also a growing trend towards IaaS and SaaS identity management systems, where firms ‘outsource’ authentication and authorization to vendors when integrate at the API level with various directory protocols and identity systems [eg. Centrify and Azure EMS].
认证系统
可能在现有企业数据中心内运行的应用程序通常使用内部企业Microsoft Active Directory或其他一些身份管理系统来验证用户登录。理想情况下, 托管在云中的应用程序不应假定Active Directory或内部标识系统可用 ; 相反,他们应该支持行业标准的身份验证和目录,如LDAP,OAUTH或SAML。这些提供OAUTH和SAML的身份验证功能更加健壮,适合作为单点登录(SSO)系统的一部分。
IaaS和SaaS身份管理系统也呈增长趋势,当API级别与各种目录协议和身份系统集成时,公司将认证和授权外包给供应商[例如。Centrify和Azure EMS]。
1.7.13 - 移动性(Mobility)
移动性(Mobility)
Mobility
With the increasing number of applications hosted in a cloud environment, users or consumers often use mobile computing devices such as tablets or smartphones. The legacy assumption that end users only have desktop PCs or a particular PC operating system (OS) is no longer true.
The concept of mobile first was adopted over the past few years but is more recently replaced with ubiquitous access the intention of both being that applications need to be designed with the ability for users to access the system through any form of computer device, from any location, and have the same experience. Mobility might also require additional security and asset configuration management features and tools to ensure identity, data encryption, data privacy, and synchronization to mobile devices for offline viewing.
Key Take-Away
Ubiquitous access, elasticity, resiliency, and persistent data are the keys to successful cloud-native applications. Applications and data must always be accessible, from any form of computing device and any location, and with a consistent user experience.
流动性
随着云环境中托管的应用程序数量的增加,用户或消费者通常使用平板电脑或智能手机等移动计算设备。最终用户只有台式PC或特定PC操作系统(OS)的传统假设不再适用。
移动优先的概念 在过去几年中被采用,但最近被无处不在的访问所取代, 其意图是需要设计应用程序,使用户能够通过任何形式的计算机设备从任何位置访问系统,并有相同的经验。移动性还可能需要额外的安全性和资产配置管理功能和工具,以确保身份,数据加密,数据隐私以及与移动设备的同步以供离线查看。
Key Take-Away
无处不在的访问,弹性,弹性和持久数据是成功的云原生应用程序的关键。必须始终可以从任何形式的计算设备和任何位置访问应用程序和数据,并且具有一致的用户体验。
因此,CN应用程序需要本地支持移动应用程序。这包括支持一系列移动后端功能的能力 - 包括移动设备的身份验证和授权服务,位置服务,客户识别,推送通知,云消息传递,iOS和Android开发工具包等。
Accordingly, CN applications need to natively support mobile applications. This includes the ability to support a range of mobile backend capabilities – ranging from authentication & authorization services for mobile devices, location services, customer identification, push notifications, cloud messaging, toolkits for iOS and Android development etc.
1.7.14 - 可扩展性(Scalability)
针对现代分布式系统环境进行了优化,能够扩展到数万个自我修复的节点。
应用程序及其所有服务应在需求增加时进行扩展和上下扩展。这种动态管理的服务可确保有效使用资源。
Each service is elastic: this means that each service can scale-up or scale-down independently of other services. Ideally the scaling is automatic, based on load or other defined triggers. Cloud computing costs are typically based on usage, and being able to dynamically manage scalability in a granular manner enables efficient use of the underlying resources.
每项服务都具有弹性:这意味着每项服务都可以独立于其他服务进行扩展或缩小。理想情况下,基于负载或其他定义的触发器,缩放是自动的。云计算成本通常基于使用,并且能够以细粒度方式动态管理可伸缩性,从而能够有效地使用底层资源。
Scalability: Cloud services enable on-demand capacity and allow organizations to scale up and out more dynamically. For example, you can cater seasonal demand in a cost-effective way.
可扩展性:云服务支持按需容量,允许组织更加动态地扩展和扩展。 例如,您可以以经济有效的方式满足季节性需求。
Elasticity
Applications should be elastic as traffic, demand, and usage increases. Elastic means that an application can scale out (adding more compute resources or additional virtual machines) to handle an increase in workload or utilization. A properly designed cloud-native application should be able to automatically detect high utilization and trigger the necessary steps to start up new VMs or application services to handle peak workloads. Then, when peak utilization diminishes, it should reduce VMs or compute instances.
Legacy applications that were not specifically designed to run in the cloud can often use a VM hypervisor to monitor processor and memory utilization, triggering more VM instances when a manually defined peak- utilization threshold is attained. These elasticity techniques make it possible for the applications to take advantage of the power of the cloud infrastructure to dynamically scale—even if the application wasn’t originally designed as cloud-native; although, a cloud native application is more efficient.
弹性
随着流量,需求和使用量的增加,应用程序应具有弹性。弹性意味着应用程序可以向外扩展(添加更多计算资源或其他虚拟机)以处理工作负载或利用率的增加。正确设计的云原生应用程序应该能够自动检测高利用率并触发启动新VM或应用程序服务以处理峰值工作负载的必要步骤。然后,当峰值利用率减少时,它应该减少VM或计算实例。
未专门设计为在云中运行的传统应用程序通常可以使用VM虚拟机管理程序来监视处理器和内存利用率,在达到手动定义的峰值利用率阈值时触发更多VM实例。这些弹性技术使应用程序可以利用云基础架构的强大功能进行动态扩展 - 即使应用程序最初并非设计为云原生的; 但是,云本机应用程序更有效。
我为什么要迁移到云端?关于BI,分析和云的2016年第四季度TDWI最佳实践报告探讨了这个问题,向组织询问了他们在云中进行分析的三大理由。
这些回应非常具有启发性,并非出乎意料,公司将可扩展性,灵活性和成本列为前三个原因。

CN架构的首要特征是能够动态支持大量用户,大型开发组织和高度分散的运营团队。当人们认为云计算本质上是多租户时,这一要求就更为重要。
在这个区域内,需要考虑典型的问题 -
- 能够动态扩展部署足迹(纵向扩展)以及减少占用空间(缩小规模)
- 能够优雅地处理跨层的故障,从而破坏应用程序的可用性
- 通过确保组件本身提供松散耦合来适应大型开发团队的能力
- 能够使用几乎任何类型的基础架构(计算,存储和网络)实施
The first & foremost characteristic of a CN Architecture is the ability to dynamically support massive numbers of users, large development organizations & highly distributed operations teams. This requirement is even more critical when one considers that cloud computing is inherently multi-tenant in nature.
Within this area, the typical concerns need to be accommodated –
- the ability to grow the deployment footprint dynamically (Scale-up) as well as to decrease the footprint (Scale-down)
- the ability to gracefully handle failures across tiers that can disrupt application availability
- the ability to accommodate large development teams by ensuring that components themselves provide loose coupling
- the ability to work with virtually any kind of infrastructure (compute, storage and network) implementation
和模块化微服务的关系
通过使用微服务,云原生应用程序可以独立自动扩展服务。这在大多数情况下会自动发生,因此不需要每天管理它们。
参考资料
1.7.15 - 可用性(Availability)
可用性(Availability)
High availability: The cloud may enable organizations to achieve availability and business continuity requirements that may not be able to be achieved otherwise or that would be cost- prohibitive.
高可用性:云可以使组织实现可用性和业务连续性要求,否则可能无法实现或成本过高。
1.7.16 - 成本(Cost)
成本(Cost)
Budgeting: Often, organizations seek cloud services and claim cost advantages, but more likely, they seek the clarity in budget because consumption-based pricing enables IT organizations to perform better budget forecasting. Specifically, adoption of cloud services allows organizations to budget IT on operating expenses instead of capital expenses.
预算编制:通常,组织寻求云服务并声称成本优势,但更有可能的是,他们寻求预算的清晰度,因为基于消费的定价使IT组织能够执行更好的预算预测。 具体而言,云服务的采用允许组织针对运营支出而非资本支出来预算IT。
1.7.17 - 效率(Efficiency)
通过中央编排过程实现了微服务的动态管理和调度,提高了效率和资源利用率,降低了与维护和运营相关的成本。
Defined, policy-driven resource allocation: Finally, cloud-native applications align with the governance model defined through a set of policies. They adhere to policies such as central processing unit (CPU) and storage quotas, and network policies that allocate resources to services. For example, in an enterprise scenario, central IT can define policies to allocate resources for each department. Developers and DevOps teams in each department have complete access and ownership to their share of resources.
定义的,策略驱动的资源分配:最后,云原生应用程序与通过一组策略定义的治理模型保持一致。它们遵循诸如中央处理单元(CPU)和存储配额以及将资源分配给服务的网络策略等策略。例如,在企业方案中,中央IT可以定义策略以为每个部门分配资源。每个部门的开发人员和DevOps团队都拥有对其资源共享的完全访问权和所有权。
1.7.18 - 敏捷(Agility)
敏捷(Agility)
Organizations often benefit from faster time to value with cloud services. IT organizations may be more agile because they can prioritize other tasks. Sometimes a specific line of business benefits because it can spin up capacity faster. This will vary depending on the strategy and what specific cloud services are under investigation. Organizations face deadlines related to infrastructure and software support end of life, regulatory compliance, or seasonal business opportunities that require a rapid application delivery or migration. Note that agility is often conflated with productivity
组织通常可以通过云服务更快地实现价值。 IT组织可能更敏捷,因为他们可以优先考虑其他任务。 有时,特定的业务线会带来好处,因为它可以更快地提高容量。 这取决于策略以及正在调查的具体云服务。 组织面临与基础架构和软件支持生命周期终止,法规遵从性或需要快速应用程序交付或迁移的季节性业务机会相关的最后期限。 请注意,敏捷性通常与生产力相关
2 - 12因素应用
2.1 - 12因素应用概述
介绍
12-Factors 经常被翻译为12因素,符合12因素的应用则称为12因素应用。
背景
Heroku(HeroKu于2009年推出公有云PaaS)于2012年提出12因素,告诉开发者如何利用云平台提供的便利来开发更具可靠性和扩展性、更加易于维护的云原生应用。
为此还有一个专门的12因素网站: https://12factor.net/ ,以及这个网站内容的中文版本: https://12factor.net/zh_cn/ 。
援引12因素网站的介绍内容:
如今,软件通常会作为服务来交付,被称为web app,或软件即服务(SaaS)。12-Factor 为构建如下的 SaaS 应用提供了方法论:
- 使用声明式格式来搭建自动化,从而使新的开发者花费最少的学习成本加入这个项目
- 和底层操作系统保持简洁的契约,在各个系统中提供最大的可移植性
- 适合在现代的云平台上部署,避免对服务器和系统管理的额外需求
- 最小化开发和生产之间的分歧,实现持续部署以实现最大灵活性
- 可以在工具、架构和开发实践不发生重大变化的前提下实现扩展
12因素理论适用于以任意语言编写,并使用任意后端服务(数据库、消息队列、缓存等)的应用程序。
援引12因素网站的给出的12因素产生的背景:
本文的贡献者参与过数以百计的应用程序的开发和部署,并通过 Heroku 平台间接见证了数十万应用程序的开发,运作以及扩展的过程。
本文综合了我们关于 SaaS 应用几乎所有的经验和智慧,是开发此类应用的理想实践标准,并特别关注于应用程序如何保持良性成长,开发者之间如何进行有效的代码协作,以及如何 避免软件污染 。
我们的初衷是分享在现代软件开发过程中发现的一些系统性问题,并加深对这些问题的认识。我们提供了讨论这些问题时所需的共享词汇,同时使用相关术语给出一套针对这些问题的广义解决方案。
12因素的局限性
12因素创作于2012年左右,SaaS平台非常具有指导意义
12-factor为Web应用程序或SaaS平台的建立非常有用的指导原则,但它在有些地方并不适合微服务体系。
在标准的12个要素以外,还存在哪些因素, 正如Kevin Hoffmann 最近在 O’Reilly 出版的书上提到了超越 12 个因素的应用。
内容
12因素具体内容为:
| Factor | 描述 |
|---|---|
| Codebase 基准代码 |
One codebase tracked in revision control, many deploys 一份基准代码,多份部署 |
| Dependencies 依赖 |
Explicitly declare and isolate dependencies 显式声明依赖关系 |
| Config 配置 |
Store config in the environment 在环境中存储配置 |
| Backing services 后端服务 |
Treat backing services as attached resources 把后端服务当作附加资源 |
| Build, release, run 构建,发布,运行 |
Strictly separate build and run stages 严格分离构建和运行 |
| Processes 进程 |
Execute the app as one or more stateless processes 以一个或多个无状态进程运行应用 |
| Port binding 端口绑定 |
Export services via port binding 通过端口绑定提供服务 |
| Concurrency 并发 |
Scale out via the process model 通过进程模型进行扩展 |
| Disposability 易处理 |
Maximize robustness with fast startup and graceful shutdown 快速启动和优雅终止可最大化健壮性 |
| Dev/prod parity 开发环境与线上环境等价 |
Keep development, staging, and production as similar as possible 尽可能的保持开发,预发布,线上环境相同 |
| Logs 日志 |
Treat logs as event streams 把日志当作事件流 |
| Admin processes 管理进程 |
Run admin/management tasks as one-off processes 后台管理任务当作一次性进程运行 |

12因素在云原生架构中的体现:

2.2 - 基准代码
官方介绍
Codebase
One codebase tracked in revision control, many deploys
基准代码
一份基准代码(Codebase),多份部署(deploy)
12-Factor应用(译者注:应该是说一个使用本文概念来设计的应用,下同)通常会使用版本控制系统加以管理,如Git, Mercurial, Subversion。一份用来跟踪代码所有修订版本的数据库被称作 代码库(code repository, code repo, repo)。
在类似 SVN 这样的集中式版本控制系统中,基准代码 就是指控制系统中的这一份代码库;而在 Git 那样的分布式版本控制系统中,基准代码 则是指最上游的那份代码库。
基准代码和应用之间总是保持一一对应的关系:
- 一旦有多个基准代码,就不能称为一个应用,而是一个分布式系统。分布式系统中的每一个组件都是一个应用,每一个应用可以分别使用 12-Factor 进行开发。
- 多个应用共享一份基准代码是有悖于 12-Factor 原则的。解决方案是将共享的代码拆分为独立的类库,然后使用 依赖管理 策略去加载它们。
尽管每个应用只对应一份基准代码,但可以同时存在多份部署。每份 部署 相当于运行了一个应用的实例。通常会有一个生产环境,一个或多个预发布环境。此外,每个开发人员都会在自己本地环境运行一个应用实例,这些都相当于一份部署。
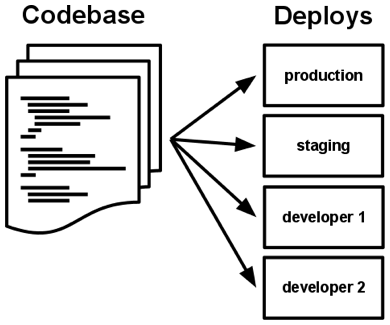
所有部署的基准代码相同,但每份部署可以使用其不同的版本。比如,开发人员可能有一些提交还没有同步至预发布环境;预发布环境也有一些提交没有同步至生产环境。但它们都共享一份基准代码,我们就认为它们只是相同应用的不同部署而已。
12-factor apps using Kubernetes
12 Factor App的原则1是“版本控制中的一个代码基准,许多部署”。
对于Kubernetes应用程序,这个原则实际上嵌入了容器编排本身的本质。通常,您使用源控制存储库(如git repo)创建代码,然后在Docker Hub中存储特定版本的映像。当您将要编排的容器定义为Kubernetes Pod,Deployment,DaemonSet的一部分时,您还可以指定镜像的特定版本,如:
...
spec:
containers:
- name:AcctApp
image:acctApp:v3
...
通过这种方式,您可以在不同的部署中运行多个版本的应用程序。
应用程序的行为也可能有所不同,具体取决于它们运行的配置信息。
2.3 - 依赖
官方介绍
Explicitly declare and isolate dependencies 显式声明依赖关系
大多数编程语言都会提供一个打包系统,用来为各个类库提供打包服务,就像 Perl 的 CPAN 或是 Ruby 的 Rubygems 。通过打包系统安装的类库可以是系统级的(称之为 “site packages”),或仅供某个应用程序使用,部署在相应的目录中(称之为 “vendoring” 或 “bunding”)。
12-Factor规则下的应用程序不会隐式依赖系统级的类库。 它一定通过 依赖清单 ,确切地声明所有依赖项。此外,在运行过程中通过 依赖隔离 工具来确保程序不会调用系统中存在但清单中未声明的依赖项。这一做法会统一应用到生产和开发环境。
例如, Ruby 的 Bundler 使用 Gemfile 作为依赖项声明清单,使用 bundle exec 来进行依赖隔离。Python 中则可分别使用两种工具 – Pip 用作依赖声明, Virtualenv 用作依赖隔离。甚至 C 语言也有类似工具, Autoconf 用作依赖声明,静态链接库用作依赖隔离。无论用什么工具,依赖声明和依赖隔离必须一起使用,否则无法满足 12-Factor 规范。
显式声明依赖的优点之一是为新进开发者简化了环境配置流程。新进开发者可以检出应用程序的基准代码,安装编程语言环境和它对应的依赖管理工具,只需通过一个 构建命令 来安装所有的依赖项,即可开始工作。例如,Ruby/Bundler 下使用 bundle install,而 Clojure/Leiningen 则是 lein deps。
12-Factor 应用同样不会隐式依赖某些系统工具,如 ImageMagick 或是curl。即使这些工具存在于几乎所有系统,但终究无法保证所有未来的系统都能支持应用顺利运行,或是能够和应用兼容。如果应用必须使用到某些系统工具,那么这些工具应该被包含在应用之中。
12-factor apps using Kubernetes
12 Factor App的原则2是“明确声明和隔离依赖”。
确保满足应用程序的依赖性是实际假设的。对于12因子应用程序,其中不仅包括确保特定于应用程序的库,而且还包括不依赖于操作系统,并假设系统库(如curl)将存在。12因素应用程序必须是自包含的。
这包括确保应用程序足够孤立,以免受主机上可能安装的冲突库的影响。
幸运的是,如果应用程序确实具有任何特定或不寻常的系统要求,则容器可以轻松满足这两个要求; 容器包括应用程序所依赖的所有依赖项,并且还提供容器运行的合理隔离环境。(与普遍看法相反,容器环境并非完全孤立,但在大多数情况下,它们都足够好。)
对于模块化并依赖于其他组件的应用程序,例如HTTP服务和日志提取程序,Kubernetes提供了一种将所有这些部分组合到单个Pod中的方法,用于适当地封装这些部分的环境。
2.4 - 配置
Store config in the environment 在环境中存储配置
官方介绍
在环境中存储配置
通常,应用的 配置 在不同 部署 (预发布、生产环境、开发环境等等)间会有很大差异。这其中包括:
- 数据库,Memcached,以及其他 后端服务 的配置
- 第三方服务的证书,如 Amazon S3、Twitter 等
- 每份部署特有的配置,如域名等
有些应用在代码中使用常量保存配置,这与 12-Factor 所要求的代码和配置严格分离显然大相径庭。配置文件在各部署间存在大幅差异,代码却完全一致。
判断一个应用是否正确地将配置排除在代码之外,一个简单的方法是看该应用的基准代码是否可以立刻开源,而不用担心会暴露任何敏感的信息。
需要指出的是,这里定义的“配置”并不包括应用的内部配置,比如 Rails 的 config/routes.rb,或是使用 Spring 时 代码模块间的依赖注入关系 。这类配置在不同部署间不存在差异,所以应该写入代码。
另外一个解决方法是使用配置文件,但不把它们纳入版本控制系统,就像 Rails 的 config/database.yml 。这相对于在代码中使用常量已经是长足进步,但仍然有缺点:总是会不小心将配置文件签入了代码库;配置文件的可能会分散在不同的目录,并有着不同的格式,这让找出一个地方来统一管理所有配置变的不太现实。更糟的是,这些格式通常是语言或框架特定的。
12-Factor推荐将应用的配置存储于 环境变量 中( env vars, env )。环境变量可以非常方便地在不同的部署间做修改,却不动一行代码;与配置文件不同,不小心把它们签入代码库的概率微乎其微;与一些传统的解决配置问题的机制(比如 Java 的属性配置文件)相比,环境变量与语言和系统无关。
配置管理的另一个方面是分组。有时应用会将配置按照特定部署进行分组(或叫做“环境”),例如Rails中的 development,test, 和 production 环境。这种方法无法轻易扩展:更多部署意味着更多新的环境,例如 staging或 qa 。 随着项目的不断深入,开发人员可能还会添加他们自己的环境,比如 joes-staging ,这将导致各种配置组合的激增,从而给管理部署增加了很多不确定因素。
12-Factor 应用中,环境变量的粒度要足够小,且相对独立。它们永远也不会组合成一个所谓的“环境”,而是独立存在于每个部署之中。当应用程序不断扩展,需要更多种类的部署时,这种配置管理方式能够做到平滑过渡。
12-factor apps using Kubernetes
12 Factor App的原则3是“在环境中存储配置”。
这个原则背后的想法是应用程序应完全独立于其配置。换句话说,您应该能够将其移动到另一个环境而无需触摸源代码。
一些开发人员通过创建某种配置文件来实现此目标,指定详细信息,例如目录,主机名和数据库凭据。这是一种改进,但它确实存在某人将配置文件检入源控制存储库的风险。
相反,12个因素应用程序将其配置存储为环境变量; 正如宣言所说,这些“不太可能被意外地检入存储库”,并且它们与操作系统无关。
Kubernetes允许您通过Downward API在清单中指定环境变量,但是由于这些清单本身会在源代码控制中进行检查,这不是一个完整的解决方案。
相反,您可以指定环境变量应该由Kubernetes ConfigMaps或Secrets的内容填充,这些内容可以与应用程序分开。例如,您可以将Pod定义为:
apiVersion:v1
kind:Pod
元数据:
name:secret-env-pod
spec:
containers:
- name:mycontainer
image:redis
env: - name:SECRET_USERNAME valueFrom:secretKeyRef : name:mysecret key:username - name:SECRET_PASSWORD valueFrom:secretKeyRef : name:mysecret key:password - name:CONFIG_VERSION valueFrom: configMapKeyRef: name:redis-app-config key:version.id
如您所见,此Pod接收三个环境变量SECRET_USERNAME,SECRET_PASSWORD和CONFIG_VERSION,前两个来自引用的Kubernetes Secrets,第三个来自Kubernetes ConfigMap。这使您可以使它们远离配置文件。
当然,仍然存在某人错误处理用于创建这些对象的文件的风险,但是它们在一起并制定安全处理策略,而不是清除分散在部署周围的数十个配置文件。
更重要的是,社区中有些人指出,即使是环境变量也不一定是出于自身原因的安全。例如,如果应用程序崩溃,它可能会将所有环境变量保存到日志中,甚至将它们传输到另一个服务。DiogoMónica指向一个名为Keywhiz的工具,您可以将其与Kubernetes一起使用,从而创建安全的秘密存储。
3 - DevOps
3.1 - 持续交付
3.1.1 - 持续交付概述
持续交付 让单个应用随时处于可发布状态,而不用等待与其他变更绑定到一次发布中。持续交付使得发布变成一个频繁且平常的过程,因此组织可以以更低的风险经常交付,并从最终用户获得更快的反馈,直到部署成为业务流程和企业竞争力的重要组成部分。

3.2 - DevOps概述
DevOps
DevOps是开发和运维的合作,目标是自动化软件交付和基础设施更改过程。它创造了一个文化和环境,让构建,测试和发布软件可以快速,频繁,更可靠地发生。

持续交付 让单个应用随时处于可发布状态,而不用等待与其他变更绑定到一次发布中。持续交付使得发布变成一个频繁且平常的过程,因此组织可以以更低的风险经常交付,并从最终用户获得更快的反馈,直到部署成为业务流程和企业竞争力的重要组成部分。
4 - 声明式设计
4.1 - 声明式设计概述
介绍
什么是Declarative?
Declarative(声明式设计)指的是这么一种软件设计理念和做法:我们向一个工具描述我们想要让一个事物达到的目标状态,由这个工具自己内部去figure out如何令这个事物达到目标状态。
和Declarative(声明式设计)相对的是Imperative或Procedural(过程式设计)。两者的区别是:在Declarative中,我们描述的是目标状态(Goal State),而在Imperative模式中,我们描述的是一系列的动作。这一系列的动作如果被正确的顺利执行,最终结果是这个事物达到了我们期望的目标状态的。
声明式(Declarative)的编程方式一直都会被工程师们拿来与命令式(Imperative)进行对比,这两者是完全不同的编程方法。我们最常接触的其实是命令式编程,它要求我们描述为了达到某一个效果或者目标所需要完成的指令,常见的编程语言 Go、Ruby、C++ 其实都为开发者了命令式的编程方法,
声明式和命令式是两种截然不同的编程方式:
- 在命令式 API 中,我们可以直接发出服务器要执行的命令,例如: “运行容器”、“停止容器”等;
- 在声明式 API 中,我们声明系统要执行的操作,系统将不断向该状态驱动。

SQL 其实就是一种常见的声明式『编程语言』,它能够让开发者自己去指定想要的数据是什么。或者说,告诉数据库想要的结果是什么,数据库会帮我们设计获取这个结果集的执行路径,并返回结果集。众所周知,使用 SQL 语言获取数据,要比自行编写处理过程去获取数据容易的多。
SELECT * FROM posts WHERE user_id = 1 AND title LIKE 'hello%';
我们来看看相同设计的 YAML,利用它,我们可以告诉 Kubernetes 最终想要的是什么,然后 Kubernetes 会完成目标。
例如,在 Kubernetes 中,我们可以直接使用 YAML 文件定义服务的拓扑结构和状态:
apiVersion: v1
kind: Pod
metadata:
name: rss-site
labels:
app: web
spec:
containers:
- name: front-end
image: nginx
ports:
- containerPort: 80
- name: rss-reader
image: nickchase/rss-php-nginx:v1
ports:
- containerPort: 88
以下是 etcd 的 operator:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: etcd-operator
spec:
replicas: 1
template:
metadata:
labels:
name: etcd-operator
spec:
containers:
- name: etcd-operator
image: quay.io/coreos/etcd-operator:v0.2.1
env:
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
Kubernetes 中的 YAML 文件也有着相同的原理,我们可以告诉 Kubernetes 想要的最终状态是什么,而它会帮助我们从现有的状态进行迁移。

如果 Kubernetes 采用命令式编程的方式提供接口,那么工程师可能就需要通过代码告诉 Kubernetes 要达到某个状态需要通过哪些操作,相比于更关注状态和结果声明式的编程方式,命令式的编程方式更强调过程。
总而言之,Kubernetes 中声明式的 API 其实指定的是集群期望的运行状态,所以在出现任何不一致问题时,它本身都可以通过指定的 YAML 文件对线上集群进行状态的迁移,就像一个水平触发的系统,哪怕系统错过了相应的事件,最终也会根据当前的状态自动做出做合适的操作。
优点
声明式 API 使系统更加健壮,在分布式系统中,任何组件都可能随时出现故障。当组件恢复时,需要弄清楚要做什么,使用命令式 API 时,处理起来就很棘手。但是使用声明式 API ,组件只需查看 API 服务器的当前状态,即可确定它需要执行的操作。
声明式设计的好处是:
- 简单。我们不需要关心任何过程细节。过程是由工具自己内部figure out的、内部执行的。
- self-documentation,因为我们描述的就是希望一个事物变成什么样子,而不是“发育”过程。
声明式的方式能够大量地减少使用者的工作量,极大地增加开发的效率,这是因为声明式能够简化需要的代码,减少开发人员的工作,如果我们使用命令式的方式进行开发,虽然在配置上比较灵活,但是带来了更多的工作。
总结
Declarative是一种设计理念,是一种工作模式,透传出来的是“把方便留给别人,把麻烦留给自己”的哲学。Declarative模式的工具,设计和实现的难度是远高于Imperative模式的。作为用的人来说,Declarative模式用起来省力省心多了。
参考资料
- 吾道一以贯之–天基风险防范的理论和实践
- Declarative简介
- 谈 Kubernetes 的架构设计与实现原理
5 - 不可变基础设施
5.1 - 不可变基础设施概述
不可变基础设施
6 - 云原生中的容器
6.1 - 容器概述
容器比虚拟机(VM)提供了更高的效率和更快的速度。使用操作系统(OS)级别的虚拟化,单个操作系统实例被动态划分为多个相互独立的容器,每个容器具有唯一可写的文件系统和资源配额。创建和销毁容器的低开销,以及单个instance可高密度运行多个容器的特性使得容器成为部署微服务各个模块的完美工具。

7 - 微服务
7.1 - 微服务概述
微服务是将大型应用程序转变为小型服务的集合的架构方法;每个服务实现单独的业务功能,运行在自己独立的进程中并通过HTTP API进行通信。每个微服务器都可以独立于应用程序中的其他服务进行部署,升级,扩展和重新启动,通常作为自动化系统的一部分,可以在不影响终端客户使用的情况下频繁独立更新。

8 - 服务网格
8.1 - 服务网格概述
服务网格
9 - 云原生参考资料
9.1 - 参考资料概述
Cloud Native 参考资料
9.2 - 2019
9.3 - 2018
9.4 - 2017
9.4.1 - 迁移到云原生应用架构
文章说明:
1.1 为何使用云原生应用架构
速度
在传统企业中,为应用提供环境和部署新版本花费的时间通常以天、周或月来计算。
互联网公司经常提到它们每天几百次发布的实践。为什么频繁发布如此重要?
- 如果你可以每天实现几百次发布,你们就可以几乎立即从错误的版本恢复过来。
- 如果你可以立即从错误中恢复过来,你就能够承受更多的风险
- 如果你可以承受更多的风险,你就可以做更疯狂的试验
- 这些试验结果可能会成为你接下来的竞争优势
所以,速度快很重要。这个快速发布-》试错 -》改进 实现快速创新的说法不错。
TODO:考虑画一个示意图,用来说明为什么要快。
精益大师Mary Poppendick提出的问题了——“如果只是改变了应用的一行代码,您的组织需要多长时间才能把应用部署到线上?“
这个说法非常适合用来直观的体现快。
安全
云原生应用架构在快速变动的需求、稳定性、可用性和耐久性之间寻求平衡。这是可能的而且非常有必要同时实现的。
安全的实现方式:
- 可观测性:指标、监控、警报、数据可视化框架和工具是所有云原生应用程序体系结构的核心
- 故障隔离:将系统拆解为微服务;结合容错
- 容错:防止级联故障
- 自动恢复:有可观测性、故障隔离、容错字后,就有机会做自动恢复。在可替换性的支持下,可以简单的重新或者重新部署
弹性扩展
如何扩大服务能力:
- 水平扩展应用实例
- 改善资源利用率:虚拟化/容器化 + 部署多个工作负载 (需要隔离性支持),然后通过编排来调度以调高效率
公有云基础设施的出现有助于实现这个目标。
付出的代码:
- 架构:支持水平扩展的应用程序的架构必须不同
- 状态:应用无状态 + 状态外部化
移动应用和客户端多样性
- 移动平台的巨大差异也对应用架构提出了要求
- 移动应用程序通常必须与多个传统系统以及云原生应用程序架构中的多个微服务进行交互
- 云原生应用程序架构还通过诸如API网关之类的设计模式来支持移动优先开发的概念:指的是BFF模式吧?
1.2 云原生架构定义
12因素应用
12因素应用是一系列云原生应用架构的模式集合,最初由Heroku提出。如Cloud Foundry、Heroku和Amazon ElasticBeanstalk都对部署12因素应用进行了专门的优化。
微服务
微服务将单体业务系统分解为多个“仅做好一件事”的可独立部署的服务。
自服务敏捷架构
使用云原生应用架构的团队通常负责其应用的部署和持续运营。(开始 + 测试 + 部署 + 运营)
基于API的协作
在云原生应用程序架构中,服务之间的唯一互动模式是通过已发布和版本化的API。 实现体现为微服务
抗脆弱性
稳健性或弹性,
Nassim Taleb在他的Antifragile(Random House)一书中介绍了抗脆弱性的概念
“混沌猴” 将随机故障注入到生产组件中,目的是识别和消除架构中的缺陷。
感觉这个说法有点不太合适,还是用回 弹性 比较好。
2.1 文化变革
企业IT采用云原生架构所需的变革根本不是技术性的,而是企业文化和组织的变革,围绕消除造成浪费的结构、流程和活动。
这个说到点了!
从信息孤岛到DevOps
企业IT通常被组织成以下许多孤岛:
- 软件开发:开发
- 质量保证:测试
- 数据库管理:DBA
- 系统管理:运维
- IT运营
- 发布管理
- 项目管理
DevOps代表着这样一种思想,即将这些信息孤岛构建成共享的工具集、词汇表和沟通结构,以服务于专注于单一目标的文化:快速、安全得交付价值。
从间断均衡到持续交付
从集中治理到分散自治
TBD:后面写云原生文化时再整理。
9.5 - 2016
9.6 - 2015及更早
9.7 - 2018
9.7.1 - 书籍
Cloud Native 书籍介绍
2015
- Migrating to Cloud-Native Application Architectures: 作者 Matt Stine
时间未知
- 云原生应用的构建之路: Redhat出的,中文版,含广告
9.8 - 演讲(2017)
Cloud Native 演讲介绍(2017年)
国内的演讲:
- 容器云对研发工作的挑战与机遇: 作者李大伟,来自易宝支付,中间关于云原生挑战那段不错,比较有代表意义
- Cloud Native 云化架构: 2017年12月,来自陈皓,大名鼎鼎的左耳朵耗子
9.8.1 - CNCF: What is Cloud Native
笔记说明
“What is Cloud Native and why should I care” 这个Slides来自 Alexis Richardson ,他是 CNCF TOC Chair & CEO Weaveworks,时间是 23 Feb 2017。
Weave的解决方案
Netflix率先将云原生作为一种实用工具,这里有一个重要的slides Netflix Development Patterns for Scale, Performance & Availability ,来自Netflix,2013年,应该是第一次提出 Cloud Native 的概念吧?
Weave Cloud 业务需求:
- 24-7-365, 全球,多租户,安全等
- 团队100%专注于快速应用开发,而不是VM管理和维护
- 我们可以根据使用/成本来增加/减少组件
- 不在接线上花钱(Prometheus只适用于Docker,Kubernetes ..)
- 我们可以在任何地方运行Weave Cloud应用程序(开源而不仅仅是亚马逊)
我们的解决方案经验:对我们最重要的是什么?
-
自动化:很多自动化。端到端。自动化所有事情。
如:CI / CD!编排!可观测性!
-
需要关注应用而不是基础设施,例如使用随时随地都能正常工作的标准包装,如容器!
-
需要了解并应用新的云原生模式和工具,以用于监控,日志,正常运行时间管理等,如微服务及其他!

这里有一个非常有意思的自动化实践,ABCDE:
- App is developed & tested locally:本地开发和测试应用,这个对开发效率有非常大的帮助,的确很重要。
- Built automatically using CI of our choice:使用我们选择的CI进行自动构建
- Container image pushed automatically:自动推送容器镜像
- Deployed automatically using Weave Cloud deploy service…:使用Weave云部署服务自动部署
- …to an Execution Environment of your choice:部署到选择的执行环境
经验教训
Cloud Native需要很好的工具:
- 开源
- 随处运行
- 可信赖的软件,由可靠的团队和流程管理
- 易于监控和控制
- 与其他工具互操作,以通用惯例的方式
基础设施必然是枯燥乏味的:
- 要专注于您的应用,基础设施必须是枯燥乏味的
- 使用容器
- 使用PaaS/CaaS或您喜欢的任何容器平台
- 注意1%的故障问题
我们需要良好的模式:
-
微服务(和Microliths)
-
Cattle not Pets:是奶牛不是宠物
-
可观察性和控制性
-
通信模式 - 蓝/绿,金丝雀,智能路由和负载均衡……
Cattle not Pets 算是行业术语,或者典故了,具体解释见 https://devops.stackexchange.com/questions/653/what-is-the-definition-of-cattle-not-pets
Cloud Native是模式
模式用来干嘛:通过向他人学习来避免痛苦
-
Availability/可用性:Microservices & Netflix for everyone
-
Automation/自动化: Deployment & Management
-
促进 CI/CD & 自动化的“ABCDE”
-
任何地方! Containers 是可移动的
通用开源软件

- Software is eating the world
- Open Source is eating Software
- Cloud is eating Open Source
如果没有通用开源软件,我们将冒着Cloud锁定的风险。
Appendix 中的 cloud native 层次关系分析非常有意思。
9.8.2 - CNCF: Cloud Native Strategy
笔记说明
“Cloud Native Strategy” 这个Slides来自 Jamie Dobson,时间是 2017-02。
Strategy
何时使用策略:
- 超越组织边界。
- 组织缺乏关键能力。
- 创造赢家和输家。 (还有抵抗)
元素:
- 目标建立在更大的故事中
- Situational Awareness:情境意识
- Now and the future: 现在和将来
- Coalitions: 联盟
- Self-Supporting Actions: 自我支持行动
- Risk: 风险
- Courage: 勇气
A strategy is a way through a difficulty, an approach to overcoming an obstacle, a response to a challenge.
Strategy可是是克服困难的一种方式,也可是是克服障碍的一个方法,是一个对挑战的回应。
鹅和金蛋
- Microservices.
- Highly available.
- Two pizza teams.
- Auto-Scaling.
- Load Balancing.
备注:这一段没太看懂要说啥。
经验教训
- Lesson #1 - Don’t Steal Ideas But Rather:不要窃取想法,而是
- Lesson #2 - Steal The Processes That Created Those Ideas:而是窃取创造这些想法的流程
这个说法非常有道理。
- Lesson #3 - Define the Problem You Are Trying to Solve :定义要解决的问题

这张图倒是很有借鉴意义,cloud native 的能力,分组方式。
- Infrastructure is Programmable:基础设施是可编程的
- System Shape== Organisational Shape:系统形状==组织形状
摸着石头过河:
-
Risk and Uncertainty: 风险和不确定性
-
Current Advantage: 目前的优势
-
Potential Actions: 潜在行动
-
Lesson #4 - In Great Uncertainty Take Smaller Steps: 在有巨大的不确定性的情况下,小步前进
Triple D 的概念:

- 发现问题
- 定义材料
- 发布解决方案
Lesson #5 - The Quicker The Cycle Time The Quicker You Learn:循环时间越快学的越快
反模式:
Anti-Pattern #1 - Goal Heavy, Action Light: 目标重,动作轻 Anti-Pattern #2 - Doing Two Things At Once:同时做两件事情 Anti-Pattern #3 - Not Finishing What You Start:开始但不结束
这个三个反模式讲的很好。后面还有一个反模式:
Anti-Pattern - Stealing People’s Ideas. AKA Being Extremely Stupid. And Unoriginal. 窃取其他人的想法,十分愚蠢,不是原创
继续lesson:
Lesson #6 - In Times of Great Uncertainty Buy Knowledge:在有巨大的不确定性的情况下,购买知识
●Lesson #7 - Knowing When To Use Strategy:知道该何时使用策略
这里出来一个daniel pink的关于dive 驱动力的图:

Appendix - Other Useful Models 这里的附录有一些模型。
Autonomy, Mastery 和 Purpose 框架
查了一下,Pink的 Autonomy, Mastery 和 Purpose 框架,参考 https://www.mindtools.com/pages/article/autonomy-mastery-purpose.htm
根据Pink的说法,内在动机基于三个关键因素:自主,征服和目的
autonomy/自主
是知道自己生活和工作的需要。要充分激励,您必须能够控制自己的工作,做什么以及做谁。
据Pink说,自主性激励我们创造性地思考,无需遵守严格的工作场所规则。通过重新思考传统的控制理念 - 正常的办公时间,着装规范,数字目标等 - 组织可以增加员工的自主权,建立信任,并改善创新和创造力。
软件公司经常使用自主激励,其中许多公司让他们的工程师有时间在他们自己的开发项目上工作。这使他们可以自由地尝试和测试新想法,这可以为组织带来好处,例如改进的流程或创新的解决方案。
mastery/征服
征服是改善的愿望。如果你受到征服的激励,你可能会发现自己的潜力是无限的,并且你会不断寻求通过学习和练习来提高你的技能。寻求征服的人需要为了自己的利益而获得它。
例如,以征服为动力的运动员可能希望尽可能快地跑步。她收到的任何奖章都不如持续改进的重要性。
purpose/目的
如果人们不了解或不能投身于“bigger picture”,他们可能会在工作中脱离接触并失去动力。
但那些相信自己正在努力做出比自己更大更重要的事情的人往往是最勤奋,最富有成效和最积极的人。所以,鼓励他们找到他们工作的目的 - 例如,通过使用OKR或OGSM将他们的个人目标与组织目标联系起来 - 不仅可以赢得他们的思想,也可以赢得他们的心灵。
例如,为员工提供利用他们的技能使当地非营利组织受益的机会可以培养强烈的目标感。正如开发以价值观或道德为导向的公司愿景一样,鼓励人们“购买”其关键的组织目标。
9.9 - 演讲(2018)
Cloud Native 2018年演讲介绍
- Evolving Cloud Native Landscape: 2018年9月,Chris Aniszczyk, CTO of CNCF
- What Is This Cloud Native Thing Anyway?: 2018年5月,作者 Sam Newman ,building microservice 一书的作者。内容风趣,就是长了点,118页。
9.9.1 - CNCF: Evolving Cloud Native Landscape
说明
Evolving Cloud Native Landscape ,来自 Chris Aniszczyk ,CTO of CNCF。
笔记
Chris Aniszczyk 介绍:
- CTO/COO, Cloud Native Computing Foundation (CNCF)
- Executive Director, Open Container Initiative (OCI)
- VP, Developer Relations, Linux Foundation (LF)
备注:好像之前来杭州和蚂蚁谈合作的是这位,待查证。
What is Cloud Native? Definition v1.0
https://github.com/cncf/toc/blob/master/DEFINITION.md
现在这个定义有中文版本了。
为何采用云原生:
- 更好的资源效率,可以用较少的服务器上运行相同数量的服务
- 云原生基础架构可实现更高的开发速度 - 更快地改善您的服务 - 降低风险
- 云原生允许多云(在公共云之间切换或在多个云上运行)和混合云(在数据中心和公共云之间移动工作负载)
Cloud Native Trail Map
Cloud Native Trail Map为企业开始云原生之旅提供了概述。

图片来自这里:Introducing The Cloud Native Landscape 2.0 – Interactive Edition, 清晰原图请见 https://github.com/cncf/landscape#trail-map (大概4M)
What Have We Learned?
- 核心构建块: Servers ➡ Virtual Machines ➡ Buildpacks ➡ Containers
- 隔离单元: 从重量级到轻量级
- 不可变性: From pets to cattle
- 供应商: 从闭源单供应商到开源跨供应商
IoT + Edge + Kubernetes
物联网 + 边缘计算 + Kubernetes,应该是一个好大的市场。
简单描述了这些场景,有需要时再来看吧,暂时用不上:
- Kubernetes: IoT+Edge Working Group
- KubeEdge: Kubernetes + Edge Nodes
- Serverless + Nodeless
9.10 - 演讲(2016)
Cloud Native 演讲介绍(2016年)
-
CNCF: Cloud Native and Container Technology Landscape: 几块内容比较有意思:1. cloud技术的发展历史 2. OCI介绍 3. Cloud Native Landscape (资料不够新了) 4. 云原生价值主张 5. Cloud Native Reference Architecture
-
The Five Stages of Cloud Native: 比较风趣的介绍了cloud native的5个阶段:denial否定、anger愤怒、bargaining讨价还价、depression沮丧、acceptance接受
-
The Cloud Native Journey: 内容一般
9.11 - 演讲(2015)
Cloud Native 演讲介绍(2015年及更早)
2015
2014
2013
- Netflix: Netflix Development Patterns for Scale, Performance & Availability: 应该是cloud native的开山之作吧?强烈推荐
9.11.1 - Netflix: Netflix Development Patterns
说明
Netflix Development Patterns for Scale, Performance & Availability ,来自Netflix,2013年,应该是第一次提出 Cloud Native 的概念吧?
笔记
这页好像很有历史意义,猜测是第一次出现 Cloud native :

Cloud Native:
- Service oriented architecture:2013年还是SOA,当时还没有微服务的概念
- Redundancy
- Statelessness:无状态对扩展实在是太重要也太方便了
- NoSQL:2013年nosql是大热
- Eventual consistency:最终一致性的实践倒是挺早

按照规模和变更频率划分为四种类型:
- enterprise IT:规模小,变化慢,所以容易处理
- 电信:规模大,变化慢,主要应对硬件失败
- 初创公司:规模小,变化快,主要应对软件失败
- 网络规模:规模大,变化快,软硬件或者说所有东西都会出问题
Netflix Cloud Goals:
- Availability:可用性优先考虑,4个99(99.99%)
- Scale:然后是可扩展性
- Performance:再是性能

可用性的复合,当服务依赖增加时,可用性下降。

为了在有1000个组件的请求下达到4个九:
- 如果组件失败会导致系统失败,则要求每个组件达到6个9
- 或者,如果组件失败可以降解而不是导致系统失败,则可以隔离非依赖
但是,Availability, Scale, Performance 是不够的!
快速迭代,提高变更率,而变更会导致bug,变更频率会影响可用性。

可用性和变更率之间的妥协: 当变更率增加时,可用性下降。

如果要提高可用性,就要降低变更率。

而要改变曲线,同时实现提高可用性和增加变更频率。
这就必须打破导致级联系统失败的级联依赖,实现子系统隔离: 让失败只发生在一个组件中,而绝不导致级联系统失败。
而子系统隔离需要实现:
- 具备超时和故障转移能力的冗余系统:当超时时可以有默认相应作为fallback
- 金丝雀推出 (Canary Push)
- Red/Black 部署:应该就是现在常说的蓝绿部署
- Standby Blue system:待机蓝色系统,应该指冷备、热备之类
- Zone isolation:区域隔离,以应对基础设施失败,如电力故障
- Region isolation:地域隔离,通过DNS切换region,然后一个region下再有两个zone

子系统隔离的总结,不得不说netflix厉害,2013年就做的这么成熟。